For each row, I want to search the TicketStatus column for an target number within the String. If found, iiterate through all the other rows in the dataframe, searching for this target number as an INT in all other row’s TicketID column.
If/when we find a match, we will switch the Odds fields for that matching pair.
@vovavili could you please provide example code? Mine ran overnight for 10 hours and still hasn’t finished. There are 20 million rows in the dataframe. So would have to loop 400 million times minimum. Also I tested on a small sample and I have an error in the code as it hasn’t switched both odds columns, it just replaces the first with the second. (doesn’t replace the second with the first)
I think I slightly underestimated what you meant to accomplish at first. In fact, that’s actually quite a head-scratcher. My immediate thought process is the following:
Extract digits from TicketStatus column
Merge two columns together in a first dictionary. (Possibly, a structured NumPy array might be faster, not sure).
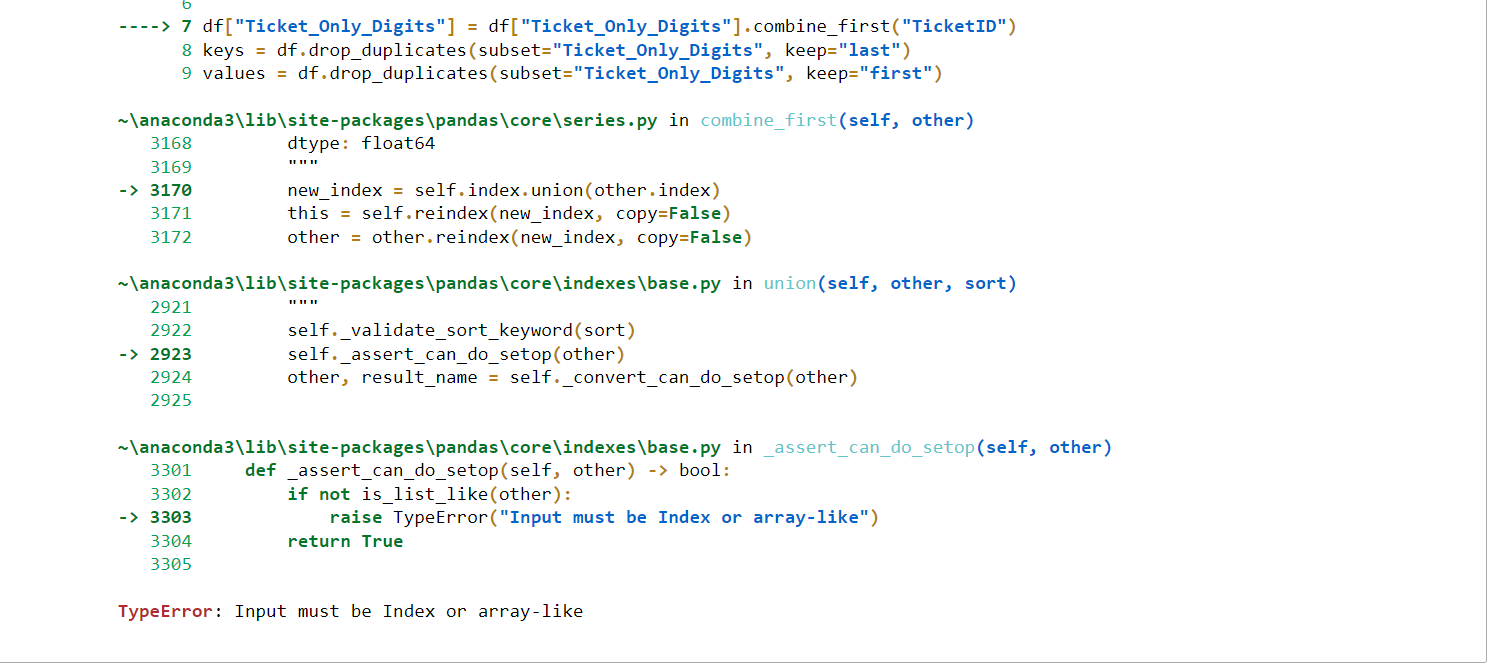
Combine first needed columns, drop duplicates, keeping both duplicates in separate dataframes for a clever dictionary trick
@vovavili Get a ValueError: cannot convert float NaN to integer, even though no N/A values in the TicketStatus column? There are TicketStatus that have no Int though within the String. (Like in the original example ‘Hello’)