Thank you for your wonderful tricks and tips again.
I still have the following puzzles:
- Why can’t the following simple method generate the final form discussed here?
In [49]: a=[0, 2/3, 0.5]
In [50]: [ repr(str(Fraction(s))).replace("'","") for s in a ]
Out[50]: ['0', '6004799503160661/9007199254740992', '1/2']
- I want to obtain data in batches and merge them into a final list for output, but the following methods fail to achieve the goal:
import requests
from bs4 import BeautifulSoup
import re
import numpy as np
from fractions import Fraction
RE_NUMS = re.compile(r'-?[\d/]+')
def str_to_number(s):
if '/' in s:
return Fraction(s)
else:
return int(s)
def matrix_print(value, depth=0):
"""Print the matrix."""
print('[', end='')
for e, v in enumerate(value):
if e:
print(', ', end='')
if isinstance(v, list):
matrix_print(v, depth + 1)
else:
print(str(v), end='')
print(']', end='' if depth else '\n')
def getBCSGens(url):
r = requests.get(url)
soup = BeautifulSoup(r.content, features="lxml")
ids = [el['id'] for el in soup.select('center > table td[id]')]
m = []
for e in ids:
i = [str_to_number(s) for s in RE_NUMS.findall(e)]
d = int(len(i) ** (1 / 2))
i = np.array(i + [0] * d + [1] )
i = i.reshape(d + 1, d + 1).tolist()
m.append(i)
return matrix_print(m)
data = []
for i in range(1, 17+1):
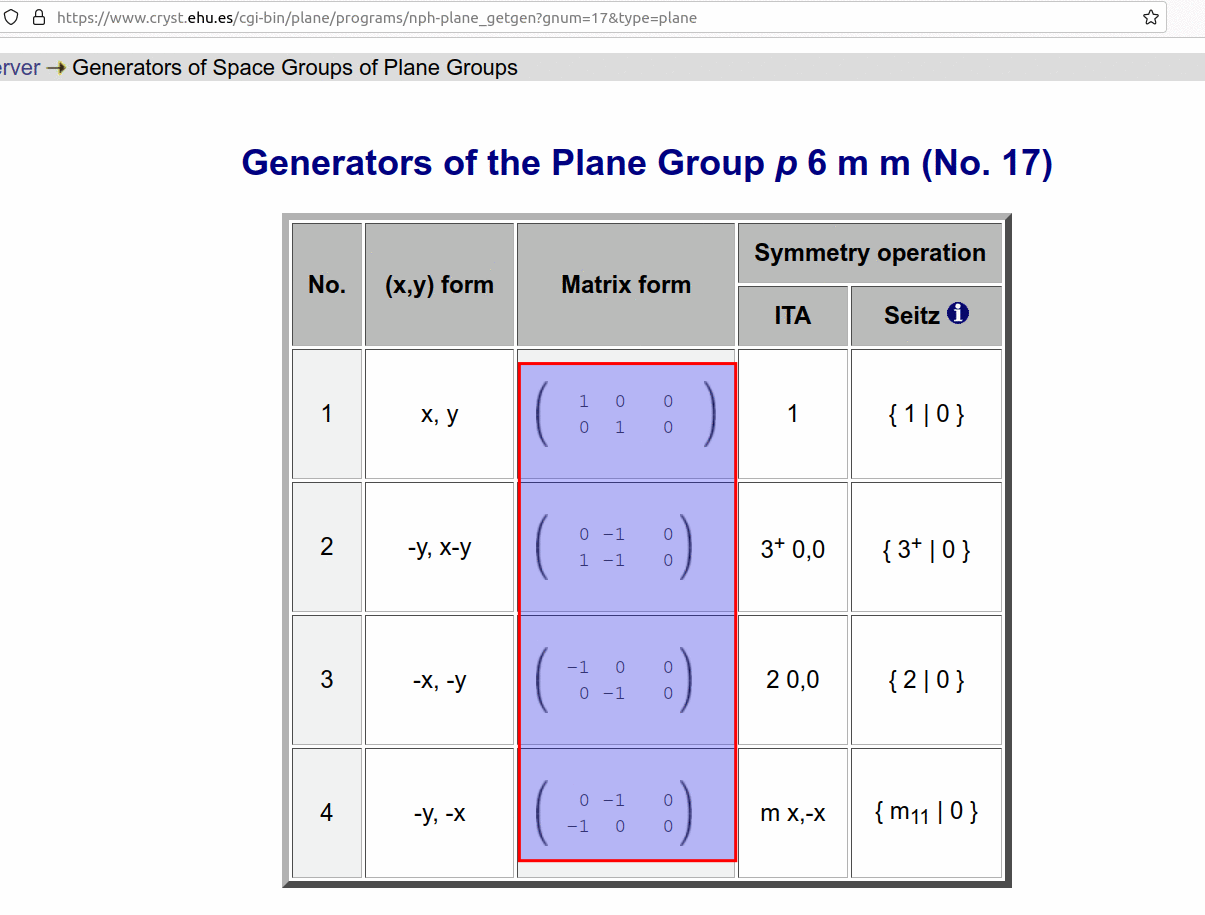
url = 'https://www.cryst.ehu.es/cgi-bin/plane/programs/nph-plane_getgen?gnum=' + str(i) + '&type=plane'
data.append( getBCSGens(url) )
print(data)
The result is as follows:
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 1/2], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 0], [0, 0, 1]], [[1, 0, 1/2], [0, 1, 1/2], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[-1, 0, 1/2], [0, 1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[-1, 0, 1/2], [0, 1, 1/2], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 0], [0, 0, 1]], [[1, 0, 1/2], [0, 1, 1/2], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[0, -1, 0], [1, 0, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[0, -1, 0], [1, 0, 0], [0, 0, 1]], [[-1, 0, 0], [0, 1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[0, -1, 0], [1, 0, 0], [0, 0, 1]], [[-1, 0, 1/2], [0, 1, 1/2], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[0, -1, 0], [1, -1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[0, -1, 0], [1, -1, 0], [0, 0, 1]], [[0, -1, 0], [-1, 0, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[0, -1, 0], [1, -1, 0], [0, 0, 1]], [[0, 1, 0], [1, 0, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[0, -1, 0], [1, -1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]]]
[[[1, 0, 0], [0, 1, 0], [0, 0, 1]], [[0, -1, 0], [1, -1, 0], [0, 0, 1]], [[-1, 0, 0], [0, -1, 0], [0, 0, 1]], [[0, -1, 0], [-1, 0, 0], [0, 0, 1]]]
[None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None, None]
- As you can see, there are multiple columns in the table. If I want to scrape other columns, taking this webpage as an example, what features should be used to extract the contents of the following corresponding columns?
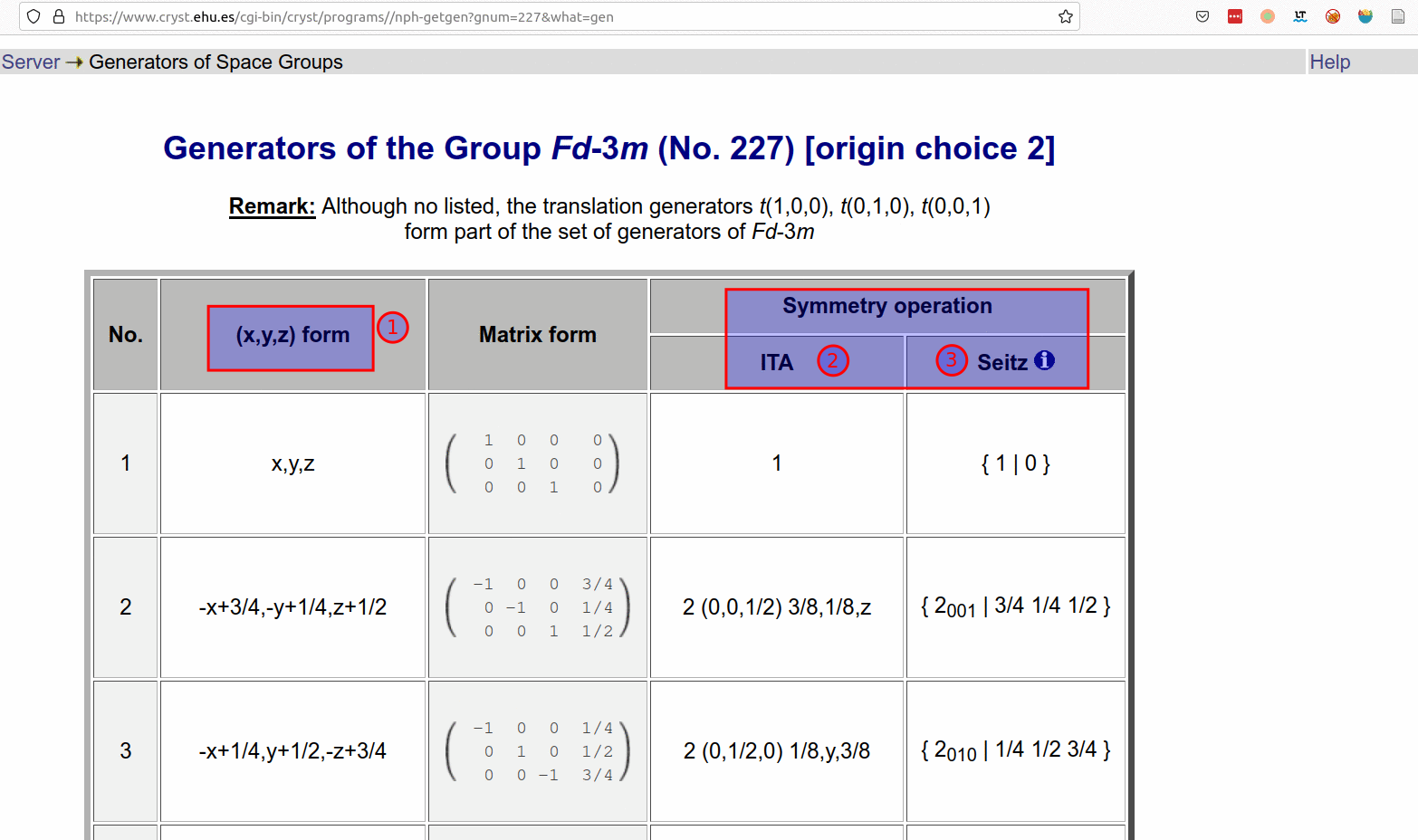
- As one of the more advanced and complicated requirements, if I want to automatically scrape the sub data set which needs corresponding selections through buttons and clicks, as shown below:
How can I achieve this aim before I can use the script discussed here?