For each line, you:
- open the output file;
- write one line;
- close the output file.
The close happens when you leave the with open(...) as ... block.
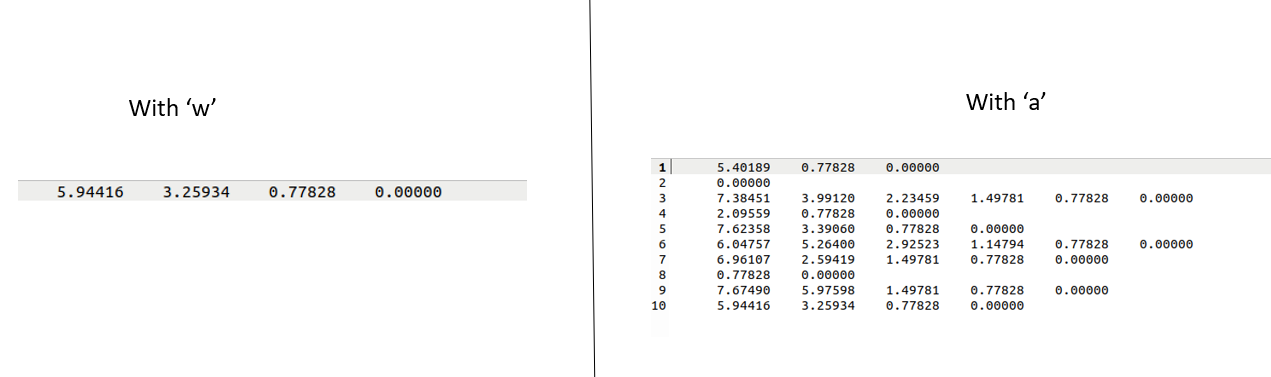
If you use “w” mode, then each time the file is opened, it overwrites what was already there.
If you use “a” mode, you keep appending from one run to the next, and the file ends up with multiple copies of the data.
Solution: use “w” mode, but only open the file once instead of once per line.
Try something like this. (Untested, you will probably need to adjust it to make it work correctly.)
s1 = open(os.path.join(d, 'sss.txt'), 'w')
s2 = open(os.path.join(d, 'sss.txt'), 'w')
for i in l:
p = os.path.join(d, i)
if os.path.isfile(p) and i == 'data.dat':
with open(p, 'r') as f:
for index, line in enumerate(f.readlines()):
if index % 2 == 0:
s1.write(line)
elif index % 2 == 1:
s2.write(line)
elif index % 2 == 2:
print("This is impossible! The rules of mathematics are collapsing, it is the end of the world!")
# Seriously, you don't need this check. Honest.
# Your safety file has never had anything in it, has it?
# Don't forget to close the output files when done.
s1.close()
s2.close()
We can even be a bit cleverer:
s1 = open(os.path.join(d, 'sss.txt'), 'w')
s2 = open(os.path.join(d, 'sss.txt'), 'w')
outputfiles = [s1, s2]
for i in l:
p = os.path.join(d, i)
if os.path.isfile(p) and inputfilename == 'data.dat':
with open(p, 'r') as f:
for index, line in enumerate(f.readlines()):
outputfiles[index % 2].write(line)
for f in outputfiles:
f.close()
As I said, I haven’t tested this code, so it may contain typos, bugs or completely do the wrong thing. Good luck!