Code that I use to test and generate heatplots.
Any additions to data are welcome.
Code that I use to test and generate heatplots.
Any additions to data are welcome.
expanding on this idea somewhat, when a partition node reaches size k where k lg k (performed by sorted in C) is less than the expected value of continuing quick sort partitioning in Python, the partition can be iter(sorted()) with an expected benefit.
the exact expected value of continuing quick sort partitioning at this node depends on the recurrence relation including the possibility of early stopping but it is lower bounded by O(k) because at least one scan is needed.
with these inputs, then, it is better to stop and use sorted when the cost of k lg k in C is less than O(k) in Python. a tighter lower bound (and earlier cutoff) is possible to derive.
Because it’s little-known, elegant, and instructive, I’ll give complete Python code for doing a reasonably efficient in-place merge of adjacent runs.
It’s not optimized. For example, if one of the runs has only one element, as mentioned before it would be more efficient to search for its final position directly.
But it does get the end conditions right for its fancier use of binary search, and that alone can leave it doing much fewer than the len(A) + len(B) - 1 compares the usual “pair at a time” merge algorithms can need.
from heapq import heappush, heappop
from bisect import bisect_right
from itertools import repeat
# Merge adjacent runs xs[L:M] and xs[M:R] in place.
def merge_inplace(xs, L, M, R):
if not 0 <= L <= M <= R <= len(xs):
raise ValueError("bad args", L, M, R, len(xs))
def searchkey(k):
return -(xs[M + k] < xs[highA - k])
h = [(None, L, M, R)]
while h:
_, L, M, R = heappop(h)
lenA = M - L
lenB = R - M
minlen = min(lenA, lenB)
assert minlen >= 0
if not minlen:
continue
highA = M - 1
k = bisect_right(range(minlen), -1, key=searchkey)
if not k:
# the whole banana is already sorted; there's no _need_
# to test for this, but it saves needless additional
# work
continue
startA = M - k
startB = M
for _ in repeat(None, k):
xs[startA], xs[startB] = xs[startB], xs[startA]
startA += 1
startB += 1
# New runs are at
# L, M-k, M
# M, M+k, R
heappush(h, (min(lenA - k, k), L, M-k, M))
heappush(h, (min(lenB - k, k), M, M+k, R))
some data for consideration.
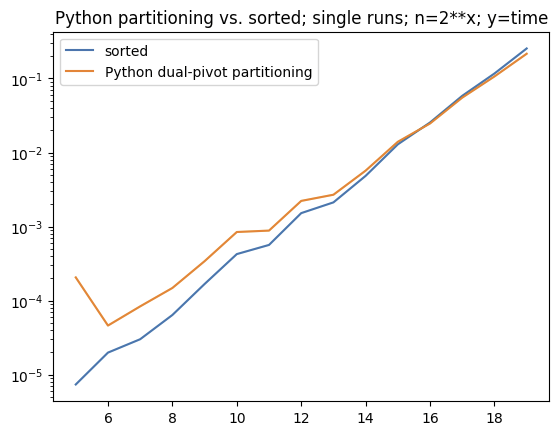
Python partitioning compared to sorted.
this appears to be the current bottleneck in my code based on the following:
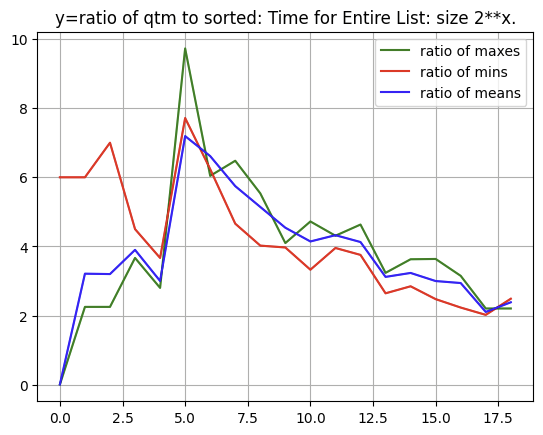
i am going to propose the idea that it lowers expected runtime of sorted to have a single O(n) pass that partitions the data, then each of those partitions are recursively sorted.
the first partition gives the lowest element.
any more than one level partitioning will need to be analysed closely, and i suspect there are benefits to be had at the expense of complexity, but one pass over the data to partition should lower the expected runtime and “time to first” latency.
best case full sort with dual pivot partitioning is:
O(n) + 3 * O(n/3 lg n/3)
worse case full sort with dual pivot partitioning is:
O(n) + O(n-1 lg n-1) + O(1)
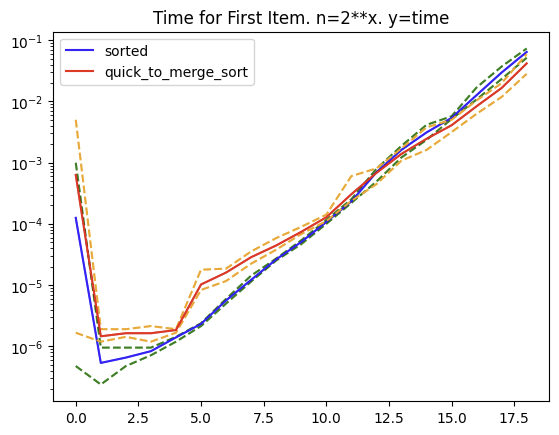
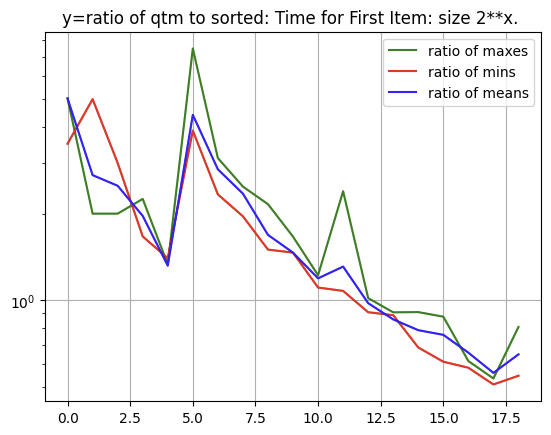
best case dual pivot partitioning first item is:
O(n) + O(n/3 lg n/3)
(actually the absolute best case is O(n) when pivot ends as first item but best case for the ideal partitioning otherwise is n/3 items per partition.)
worst case dual pivot partitioning first item is:
O(n) + O(n-1 lg n-1)
Why use a heap?
My apologies for that! I got it backwards. For randomly ordered data, input runs tend to have about the same length, and K is usually near half their common length. And that’s a worst case for this algorithm. The smaller (or larger!) K is, the quicker progress is made toward completion.
Ah, surely to keep it small. I’ll have to think that through more.
Just code simplicity. As I briefly mentioned, in cases like:
A:2 3 4 5 6 ... B:1
a number of derived non-trivial merge problems are created about equal to the length of A, and an equal number of trivial ones (one of the derived subproblems has an empty run). It’s tedious to write code to weed the trivial ones out before pushing. A min heap automatically deals with them first, and continues just as soon as it sees that minlen is 0. They’re popped off just about as fast as they’re pushed.
More generally, to limit stack (heap) depth, we want to do, for each pair tackled, the smaller of the two derived subproblems first. A min heap also arranges for that without any tedious by-hand logic.
It doesn’t matter to O() behavior. As is, the heap will never contain more than about log2(n) entries, so its size remains trivial
It could do about as well to use a plain stack, but then it would require explicit code to capture the important parts of what a heap gives us (almost) “for free”.
I’m having trouble following this. sorted is the name of a Python builtin function, so the phrase “recursively sorted” doesn’t make sense to me.
If you’re saying you’d like to partition just once, and then apply sorted to the derived partitions, and that’s it … well, I think we have mountains of empirical evidence now saying that multiple levels of partitioning are vital for reducing time-to-first-result in the quicksort-based generators. If some “head theory” disagrees, there’s something wrong with the theory ![]() .
.
@tim, maybe you know why does Timsort or similar variations batch into sizes of 32?
I didn’t know that they do ![]() . timsort picks a minimum run length to enforce that’s only bounded by specific powers of 2, based on the input’s length. It can be any int in the closed interval [32, 64].
. timsort picks a minimum run length to enforce that’s only bounded by specific powers of 2, based on the input’s length. It can be any int in the closed interval [32, 64].
I believe the Java port of the algorithm uses a different range.
It’s explained in the “Computing minrun” section of Objects/listsort.txt in a Python source tree. The higher the minimum run length enforced, the fewer function calls need to be made overall, but the more time burned by the less-effiicent fallback sorting algorithm for “small cases” (for CPython, binary insertion sort).
The range an implementation will pick from is thus influenced by the relaitive costs of function calls and the fallback sorter in the implementation language.
And there’s “a range” instead of a fixed value so that we can try to luck into having a close-as-possible-to-balanced final merge if the data is randomly ordered. See listsort.txt for details.
The sorting code already overwhelmingly dominates listobject.c, and there will be opposition for that reason alone. It’s already at an uncomfortable level of complexity and … well, bloat.
More pushback because, honestly, I still haven’t seen a compelling actual use case for making sort lazy. Actual use cases, like “what are the 100 smallest items?” are already handled very quickly by functions in heapq. As @Stefan2 said, they’re usually O(n) time, largely independent of the number of results requested (most elements usually whiz by without doing any heap operation).
So while I too have had a lot of fun with this, to me it’s still in the “potential solution in search of a problem” category.
No way for anyone else to guess unless you explain what your initial data analysis does.
The current sort does nothing conceivably relevant before sorting starts “for real”:
It does a pre-pass to see whether it can use a faster specialized comparison function.
If key= was specified, it computes the key function for each list element and stores the values for reuse.
Things like getting out “almost instantly” if the data happens to be forward- or reverse-sorted already are not special cases. Those happen naturally because the very first call to count_run() happens to consume the entire list
Even then there’s no code to recognize that as such. A slice object representing the entire list is pushed on the merge stack (a slice representing the number of items count_run() found is always pushed on the merge stack); the main loop breaks out because it sees the end of the input has been reached; and then the ordinary exit code collapses all the runs remaining on the merge stack (which does nothing in these happy cases, because there’s only one entry on the merge stack)..
If some kind of preliminary analysis could help, I’m all ears ![]() .
.
As above, I expect “fairly” is underestimating the difficulty of getting anything major merged here, due to a combination of the current code already being relatively massive & complex, and the seeming lack of compelling use cases.
So proceed for the sheer fun of it without hope of reward - only glory ![]() .
.
I think what threw me off was the power of the heap, and that you deviated from your earlier “recurse on the pair with the smallest total length” and instead switched to smallest smaller length.
Instead of the heap, I might’ve just used a stack and this:
h += sorted([
(lenB, L, M-k, M),
(lenA, M, M+k, R)
])
I.e., if B is shorter, then postpone A (by pushing it first), and vice versa. Granted, this is kinda filthy, storing subproblems with lengths of other subproblems. If that’s disliked, then maybe one of these instead:
h += sorted([
(-lenA, L, M-k, M),
(-lenB, M, M+k, R)
])
h += sorted(
[(L, M-k, M), (M, M+k, R)],
key=lambda LMR: LMR[0] - LMR[2]
)
h += sorted(
[(L, M-k, M), (M, M+k, R)],
key=lambda LMR: LMR[2] - LMR[0],
reverse=True
)
One more tiny thing, about the bisect key: I’d stick with bools and look for True instead of -1:
def searchkey(k):
return not xs[M + k] < xs[highA - k]
k = bisect_left(range(minlen), True, key=searchkey)
import random
from bisect import bisect_left
from itertools import repeat
# Merge adjacent runs xs[L:M] and xs[M:R] in place.
def merge_inplace(xs, L, M, R):
if not 0 <= L <= M <= R <= len(xs):
raise ValueError("bad args", L, M, R, len(xs))
def searchkey(k):
return not xs[M + k] < xs[highA - k]
s = [(None, L, M, R)]
while s:
global max_stack_size
max_stack_size = max(max_stack_size, len(s))
_, L, M, R = s.pop()
lenA = M - L
lenB = R - M
minlen = min(lenA, lenB)
assert minlen >= 0
if not minlen:
continue
highA = M - 1
k = bisect_left(range(minlen), True, key=searchkey)
if not k:
# the whole banana is already sorted; there's no _need_
# to test for this, but it saves needless additional
# work
continue
startA = M - k
startB = M
for _ in repeat(None, k):
xs[startA], xs[startB] = xs[startB], xs[startA]
startA += 1
startB += 1
# New runs are at
# L, M-k, M
# M, M+k, R
s += sorted((
(lenB, L, M-k, M),
(lenA, M, M+k, R)
))
# Test correctness and max stack size
m = 10 ** 5
A = sorted(random.choices(range(m), k=m))
B = sorted(random.choices(range(m), k=m))
xs = A + B
expect = sorted(xs)
max_stack_size = 0
merge_inplace(xs, 0, m, 2 * m)
print(xs == expect, max_stack_size)
Yes, I later thought it would be clearer to judge the derived subproblems on their own merits, not endure another layer of thinking to judge whether they could just partially inherit a measure from their parents.
While I would not, but that’s just me. This is a higher level of “simplicity” for me: I often use a heap to order derived subproblems on a measure of their likely cost, so this is a pattern I naturally use. It minimizes novelty and chances of conceptual error. A stack would doubtless do about as well in many such contexts, but it takes custom work, code, and analysis for each context. “Just use a heap” skips all that. If it proves important to speed, sure, do it. But otherwise “simplest thing that could possibly work” rules for me, where “simplest” refers to analysis & coding effort.
For example, suppose I were to write a 7-pivot quicksort. Binary search can be used to determine which of the 8 buckets "the next’ input belongs in. At the end of partitioning, then, I just push the 8 buckets on to a min heap keyed by their length. No more thought - or code - required. The horrid memory locality of heap operations doesn’t really come into play for heaps so small. In the current context, the underlying vector of C pointers fits in a few L1 cache lines.
Seems a matter of taste. As k marches over range(minrun), the sequence of “is the right element < the left one?” results match the regexp
True* False*
That’s how I picture it. I want to find the boundary (toward which end it doesn’t really matter whether bisecting “left” or “right” is used, provided the thing being searched for matches how you picture it).
The raw regexp isn’t suitable, though, because bisect needs a sequence of non-decreasing values to search over. “Fine, then negate them and look for the boundary between --1 and 0” is just the first thing that came to mind.
You’re changing it into
False* True*
and that’s fine too. Both transformations require applying a unary operator to the original comparison result.
But the transformation could be skipped too by building
False* True*
from the start, via
def searchkey(k):
return xs[M + k] >= xs[highA - k]
...
k = bisect_right(range(minlen), False, key=searchkey)
(or bisect_left looking for True). Then it’s actually faster too.
That didn’t occur to me, because CPython tries to stick to using just __lt__ in sorting/merging/heap contexts. I introduced that convention, but I’m not sure it was worth the bother. It was primarily intended to minimize the work someone with a custom class had to do in order for instances of their class to participate in Python’s sort/merge/heap functions.
But once an instance becomes a component of a tuple (or list), lexicographic sequence comparisons always start with __eq__ compares (to find the first position where the sequences differ), and then their code blows up unless they implement __eq__ too.
But then people in that position usually implement __eq__ too anyway.
In any case, there’s nothing about the problem being solved that requres sticking to __lt__
Looks good! Note that you should also verify that in-place merge is stabile (I believe it is, and my own testing didn’t find an exception).
And glad you had some fun with this too! ![]()
Yes, I also used not instead of >= because of the __lt__ convention. For the binary search with False* True*, I think I got that from Ruby, where I like it a lot. A comparison.
here is an algorithm i thought of.
while performing quick sort dual-pivot partitioning, there are four sections: “less than”, “between pivots”, “unknown”, and “greater than”.
best case is when data is evenly partitioned into four equal parts of n/4 (at every recursion level), and the recursion tree depth is log n with base four.
worst case is when one of the three of “less than”, “between pivots”, or “greater than” reaches n/2 and “unknown” is therefore also (at most) n/2 (at each recursion level), so the recursion tree depth is log n with base two.
(note: log₂b = 2 log₄b.)
it is like recursive merge sort except with the added benefit of the recursion tree possibly being half as deep and at most the same depth.
(note: this algorithm cannot yield the minimum value until the final merge, so using it to return an iterator is tbd.)
def quad_sort(data):
if len(data) <= 2**6:
return sorted(data)
n = len(data)
left = list()
middle = list()
right = list()
pivot_one = data[n // 3]
pivot_two = data[n // 2]
if pivot_two < pivot_one:
pivot_one, pivot_two = pivot_two, pivot_one
half_n = n // 2
three_quarter_n = 3 * n // 4
for _ in range(three_quarter_n):
item = data.pop()
if item < pivot_one:
target = left
elif pivot_two < item:
target = right
else:
target = middle
target.append(item)
if half_n < len(target):
break
unknown_sorted = quad_sort(data)
left_sorted = quad_sort(left)
middle_sorted = quad_sort(middle)
right_sorted = quad_sort(right)
# the group [left_sorted, middle_sorted, right_sorted]
# are sorted both *individually* and *as a group* in this order.
# this represents 3/4 of n in the best case and n/2 in the worst case.
# a merge between this grouping and unknown_sorted should suffice.
# i use sorted() here to do the merge.
unknown_sorted.extend(left_sorted)
unknown_sorted.extend(middle_sorted)
unknown_sorted.extend(right_sorted)
return sorted(unknown_sorted) # merging the two groups from the same list
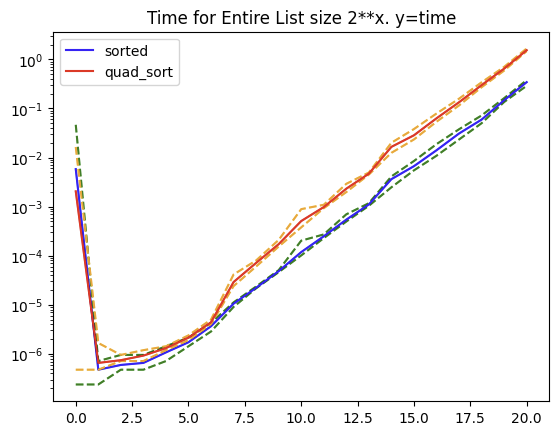
charts (note: at 2**6=64 it calls sorted). this is random integers.
using dg-pb’s tests. i can’t write fast code.
That needs to be rearranged. Everything in the last 3 partitions appeared in the original input before anything in unknown_sorted was seen, so unknown_sorted has to be the last (not the first) piece in the grand catenation. That’s to ensure stability. For example, if 42 appears in unknown_sorted and in left_sorted, the instance of 42 in the latter needs to appear before the instance in the former.
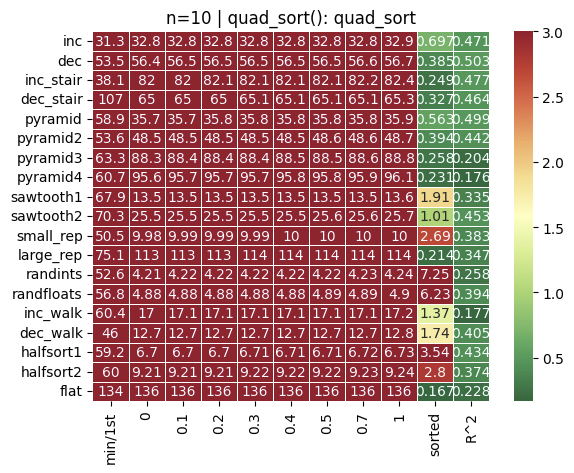
His heat map is mostly judging laziness, and you already know your current code isn’t at all lazy. So long as that remains true, you’ll see “mostly red” no matter what changes you make.
nice catch. i didn’t even think of that.
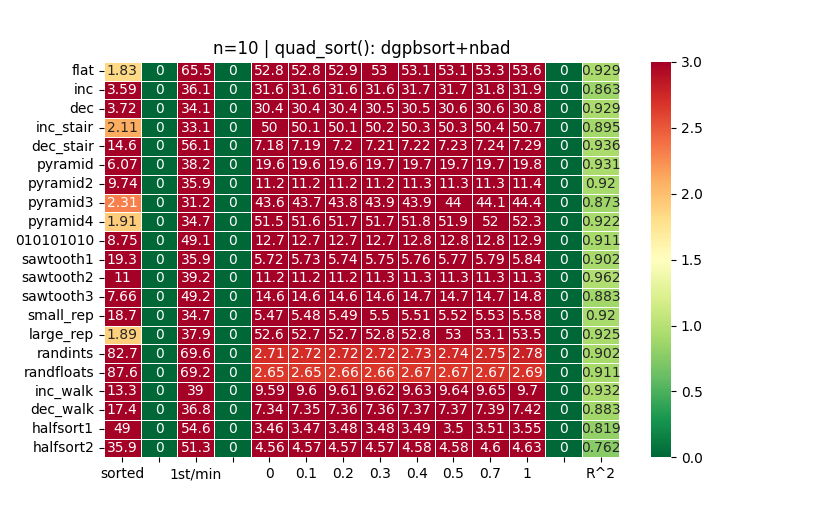
There were some bugs in my test suite. Those sorted times that were low were sequences not being wrapped in [el]. Also, added more datasets and more options. E.g. Can do correctness check via stable1=True/False/None. It shows that your algorithm is not stable for example.
Here is the heat for your algorithm.
As your strategy is not lazy-oriented all row values are the same. And it looks better after fixes: