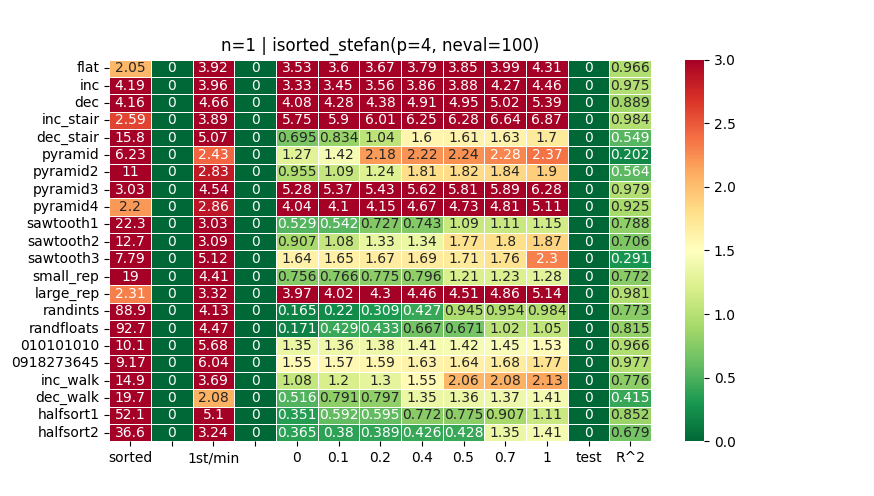
Lovely code! It does great on time-to-completion, but mediocre on time-to-first. Which I expected, because (a) it’s picking a higher-quality pivot than any other method yet tried (“niner” is not median-of-9, but median-of-3-medians-of-3, which is lower quality but cheaper to compute, at least in C); and, (b) it’s handing off so much work to Python’s sort (for example, all of the first hi, which is about half the total input).
My current belief is that laziness is best served by trying to pick 'bad" pivots (from quicksort’s expected time-to-completion view), biased toward making the lo partition smaller - but not too bad .
Ya, I believe choices would be fine, and thanks for trying many ways. But I think we’re still working toward finding better high-level approaches, and don’t want to get too distracted by “just constant factor” optimizations,
So I have parameterised it to try different combinations:
def isorted_stefan(xs, p=4, neval=100):
xs = list(xs)
stack = []
while len(xs) > neval:
pivot = sorted(random.sample(xs, 9))[p]
lo, hi = [], []
for x in xs:
if x < pivot:
lo.append(x)
else:
hi.append(x)
stack.append(hi)
xs = lo
stack.append(xs)
return chain.from_iterable(
xs.sort() or xs
for xs in reversed(stack)
)
```python
from heapq import nsmallest, heapify, heappop
NUMS = this.SortDataGen(100_000).datagen(one='randints')
%timeit min(NUMS) # 4 ms
%timeit nsmallest(2, NUMS) # 5 ms
%timeit a = list(NUMS); heapify(a); a[0] # 9 ms
%timeit sorted(NUMS) # 110 ms
As you can see above, sorted takes 110 ms in total. heapify takes 10 ms.
Thus, the best shot to increase laziness without sacrificing total runtime is to try and get the first 10% of data into sorted as soon as possible.
The cost of trying to identify smaller chunk than 10% of data is hardly going to be worth it.
So ok, nsmallest does it in 5ms so 5% of data is pretty much the lowest bound worth aiming for, but 10% will affect total time less. So let’s see with 5%:
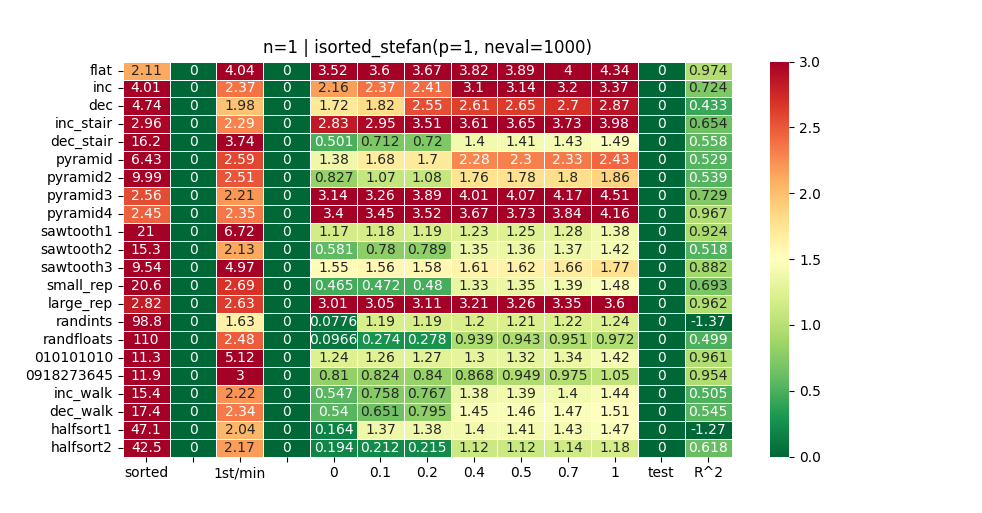
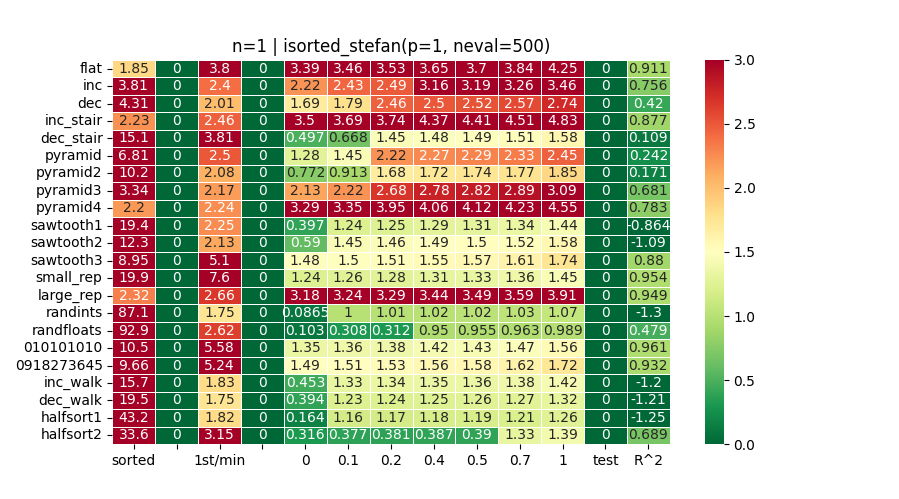
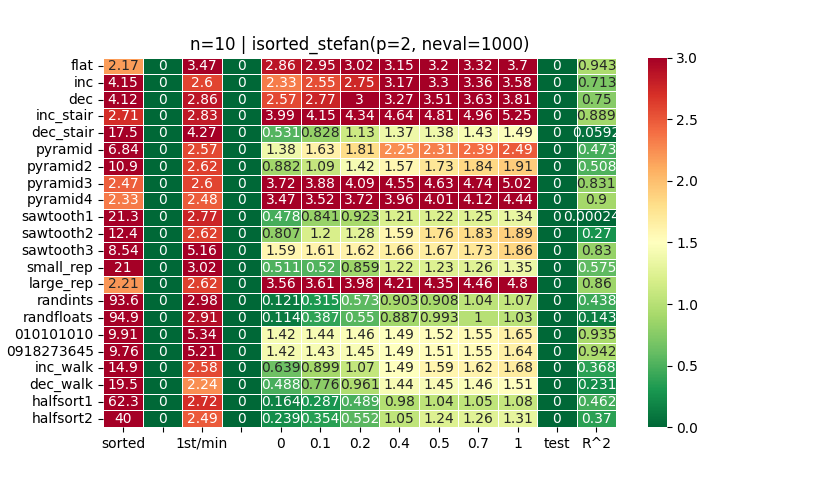
So @Stefan2’s function is great to get a sense of theoretical best for time-to-first + total runtime. Of course this comes at the expense of linearity… (see R^2 in charts above and compare with heatplots of other functions…
On my test data, time-to-first was very significantly decreased by replacing
pivot = sorted(sample(xs, 9))[4]
with
pivot = min(sample(xs, 9))
Which is the all-time fastest I’ve yet seen (apart from the strawman generator based on selection sort).
That change doesn’t hurt time to completion at all - it was already passing so very much of the total work direclty to .sort() that the times for the little partitioning it does don’t much matter.
Aye, that’s the rub. If only we had actual use cases to help inform the tradeoffs .
" Bottom line: a negative 𝑅2 is not a mathematical impossibility or the sign of a computer bug. It simply means that the chosen model (with its constraints) fits the data really poorly."
But it was worth taking a look at… Improved robustness of it all a bit.
Here is one with more repetitions (I was doing only 1 before for quick running):
I think one reason to have isorted is that the user might not need everything but also doesn’t know in advance how much they need, so they read until they have enough. And then my reasoning is that if they do get to the second half, then it seems likely they’re going all the way after all (or at least go quite a bit further). In which case using Python’s sort once for the rest seems appropriate.
Did that now the way I had in mind, though without using the unused dividers later. Doesn’t seem good:
code
from itertools import chain
def isorted(xs):
def chunks(xs):
stack = [list(xs)]
while stack:
xs = stack.pop()
n = len(xs)
if n < 256:
xs.sort()
yield xs
continue
# Get ~sqrt(n) dividers
k = n.bit_length() // 2
K = (1 << k) - 1
divs = random.choices(xs, k=K)
divs.sort()
# Leftward dividers become pivots
parts = []
while K:
K //= 2
parts.append((divs[K], []))
min_bucket = []
# Partition
for x in xs:
for pivot, bucket in parts:
if not x < pivot:
bucket.append(x)
break
else:
min_bucket.append(x)
# Push subproblems on stack
for _, bucket in parts:
if bucket:
stack.append(bucket)
if min_bucket:
stack.append(min_bucket)
return chain.from_iterable(chunks(xs))
i noticed the “partition only the left” code was missing a depth cutoff, so i put one at lg n (without an ‘nbad’ or the similar construction i was using) and reran the tests.
def isorted(xs):
lg_n = len(xs).bit_length()
xs = list(xs)
depth = 0
stack = []
while len(xs) > 100 and depth < lg_n:
pivot = min(sample(xs, 9))
lo, hi = [], []
for x in xs:
if x < pivot:
lo.append(x)
else:
hi.append(x)
stack.append(hi)
xs = lo
depth += 1
stack.append(xs)
return chain.from_iterable(
xs.sort() or xs
for xs in reversed(stack)
)
in my testing, the asymptotic constant compared to sorted() on average on random data is around 10 and i intend to investigate the discrepancy but am trusting the heatmaps.
i looked at the code and what is happening is that the first time is used as the y intercept and the last time (in conjunction with the first) is used to determine the slope of the line.
i could be wrong, but that is what seems to be causing negative R^2 values.
here are the two lines setting the intercept and slope. i think the best approach is to use a library and in my experience i prefer scikit-learn for this kind of task.
Issues with extreme values were not caused by incorrect calculation, but rather 3 factors:
Default repeat was set to 1 for quick testing so it had a lot of noise
Some functions that randomised pivot were not setting seed and this was causing a lot of jitter - especially @Stefan2’s function
I had my aggregation function set to min and for R^2 values it was picking the most erroneous one. Not that it had an effect on repeat=1 :), but now I set this function to mean and did -func(-R^2) for it to take the best value when the function is min so that it is in line with the rest of data.
The only thing that is arguable is whether to set intercept to 0. If we were regressing against some theoretical optimum, we could use its results to set (total_runtime - warmup_time). But this is simple linearity check, so that is more than good enough. Also, if actual linear regression was performed, then it wouldn’t be so sensitive to things such as @Stefan2 did.
And also, is linear regression even appropriate here? What is the thing that it would be measuring? Imagine the data (well you don’t need to imagine - it is right there in heatmaps above).
Red line is linear regression.
Blue line is what I am doing.
I want to measure discrepancy between black and blue lines.
As I needed to normalise it by something, I just used R^2 as it fits the purpose and gives a nice perfect value of 1.
But really it has not much to do with R^2 from linear regression (apart from the fact that it is the same formula of course).
if the data actually is expected to resemble an elbow then i do not believe a linear model is appropriate because they (the data) violate the homoscedasticity assumption.
on the other hand if the homoscedasticity assumption is upheld by the data (ie. the data resembles a line) then we wouldn’t want to use data points directly because the variance in the data points will be baked into the result.
edit: unless we can apply a function to the data that makes it meet the homoscedasticity assumption. R^2 is a decent measure of linearity but the model should be able to freely accommodate the data and the homoscedasticity assumption should be reasonably close (for our purposes). i could be wrong. not a statistician.
R^2 is not a measure of linearity, but a measure of fit. In linear regression it can measure linearity of a trend in case the data is ordered, e.g. time series data.
My mistake - I mistook the number of buckets (1024) for the number of pivots (1023).
“Use cases” are far more compelling when they come from actual end-users giving actual problems they’re having. Else it’s an exercise in “motivated reasoning”.
I don’t deny that it’s possible for cases like you hypothesize to arise, but I’ve never heard an actual user raise the issue. As already noted, I recall only one instance of this coming up from an actual user, and they didn’t care about laziness at all. They were just looking for magic to sort an array that used less RAM than xs.sort().
Related things with plenty of “real use cases” are addressed by heapq’s nsmallest/nlargest. They can’t be beat if you know in advance that you only want k items andk is small compared to n = len(xs).
If k is a significant fraction of n, then just about every method posted here runs faster (at least applied to the wrapped-in-1-lists test data we’ve been using). For example, the “descend to leftmost leaf” code you posted does very well when looking for the smallest 200K from a list with a million elements. nsmallest() takes over 4.5x longer to get it done, and 3.6x longer than my “7-pivot” code (and those two were the fastest of the methods I tried it on).
But that doesn’t count as a “real” use case either - I’m just putzing around. Does anyone actually want a large prefix of a sorted list? If they do, is peak speed important enough to them that they’d suffer if they just used your Python code? If so, would they suffer enough to pay you to rewrite it in C and bribe the Steering Council to put into the core ?
I never wanted such a thing, and am having a hard time imagining a real-life application domain where it would come up. It there is such a thing, offhand I’d guess they’d be far better off using a sortedcontainers.SortedList (which is always in sorted order, so things like “smallest K” are always instantly available to iterate over, along with variants like “iterate over all values >= 1_000_001 and <= 2_500_000”).
The code I wrote for it looks very different, but I believe it does a very similar thing, and for me too it wasn’t special, not really in the running for “the best” on anything I test (not time-to-first, time-to-completion, or time-to-p%-of-the-way for various values of p).
I haven’t had time to dig into why. I just dumped in enough prints to see that it was extremely effective at drilling down to the smallest values quickly on a million-entry input. The smallest partition held under 1000 elements at the top level, and the second level reduced those enough so that its smallest partition was small enough to hand off to Python’s sorted().
So it’s not that it’s doing “excessive” partitioning in time-to-first. It fact, it’s hard to imagine that it could reliably do better at that. But I don’t yet know what the hangup is.
Tim, i would like to publish a group paper if this work yields some fruit if that is alright. something along the lines of the paper for pattern-defeating quicksort. this is a hobby of mine but it would be nice to have something out there.