Sorry for bumping this. Below is the summary from that pull request. Right now I want to know just one thing: can I create a pull request, or should I just delete my branch? I don’t think any further changes I make will change someone’s opinion.
Motivation
For finding multiple substrings, there’s currently no single algorithm that outperforms others in most cases. Their performance varies significantly between the best-case and worst-case, making it difficult to choose one:
| algorithm |
loop in |
loop startswith |
re |
find str |
unit |
| find chars best case |
1.00 |
1.19 |
1.56 |
1.37 |
x 180 nsec |
| find chars mixed case |
1.00 |
1.22 |
1.54 |
91.01 |
x 178 nsec |
| find chars worst case |
1262.20 |
1597.56 |
131.71 |
1.00 |
x 32.80 usec |
| find subs best case |
|
1.00 |
1.33 |
1.17 |
x 212 nsec |
| find subs mixed case |
|
1.00 |
1.30 |
3327.27 |
x 220 nsec |
| find subs worst case |
|
35.82 |
3.62 |
1.00 |
x 1.46 msec |
| find many prefixes |
|
1760.80 |
1.00 |
122.26 |
x 301.00 usec |
| find many infixes |
|
122.17 |
1.00 |
7.71 |
x 4.33 msec |
| rfind chars best case |
1.00 |
2.61 |
4.34 |
1.96 |
x 114 nsec |
| rfind chars mixed case |
1.00 |
2.66 |
4.34 |
4561.40 |
x 114 nsec |
| rfind chars worst case |
50.10 |
55.25 |
6.94 |
1.00 |
x 1.01 msec |
| rfind subs best case |
|
1.58 |
2.55 |
1.00 |
x 229 nsec |
| rfind subs mixed case |
|
1.00 |
1.59 |
1921.05 |
x 380 nsec |
| rfind subs worst case |
|
38.07 |
4.97 |
1.00 |
x 1.45 msec |
| rfind many suffixes |
|
1094.46 |
1.00 |
50.51 |
x 487.00 usec |
| rfind many infixes |
|
54.70 |
1.00 |
2.41 |
x 9.69 msec |
That’s why I’m suggesting a dynamic algorithm that doesn’t suffer from these problems:
| algorithm |
loop in |
loop startswith |
re |
find str |
find tuple |
unit |
| find chars best case |
2.67 |
3.19 |
4.15 |
3.64 |
1.00 |
x 68 nsec |
| find chars mixed case |
2.29 |
2.80 |
3.53 |
208.23 |
1.00 |
x 78 nsec |
| find chars worst case |
1489.21 |
1884.89 |
155.40 |
1.18 |
1.00 |
x 27.80 usec |
| find subs best case |
|
3.07 |
4.07 |
3.59 |
1.00 |
x 69 nsec |
| find subs mixed case |
|
2.32 |
3.02 |
7713.38 |
1.00 |
x 95 nsec |
| find subs worst case |
|
35.82 |
3.62 |
1.00 |
1.01 |
x 1.46 msec |
| find many prefixes |
|
1760.80 |
1.00 |
122.26 |
82.06 |
x 301.00 usec |
| find many infixes |
|
122.17 |
1.00 |
7.71 |
5.22 |
x 4.33 msec |
| rfind chars best case |
1.33 |
3.45 |
5.76 |
2.59 |
1.00 |
x 86 nsec |
| rfind chars mixed case |
1.08 |
2.86 |
4.67 |
4905.66 |
1.00 |
x 106 nsec |
| rfind chars worst case |
50.10 |
55.25 |
6.94 |
1.00 |
1.10 |
x 1.01 msec |
| rfind subs best case |
|
3.70 |
5.98 |
2.34 |
1.00 |
x 98 nsec |
| rfind subs mixed case |
|
3.42 |
5.43 |
6576.58 |
1.00 |
x 111 nsec |
| rfind subs worst case |
|
38.07 |
4.97 |
1.00 |
1.04 |
x 1.45 msec |
| rfind many suffixes |
|
1094.46 |
1.00 |
50.51 |
50.31 |
x 487.00 usec |
| rfind many infixes |
|
54.70 |
1.00 |
2.41 |
2.39 |
x 9.69 msec |
algorithms
# find_tuple.py
def find0(string, chars):
for i, char in enumerate(string):
if char in chars:
break
else:
i = -1
return i
def find1(string, subs):
for i in range(len(string)):
if string.startswith(subs, i):
break
else:
i = -1
return i
def find2(string, pattern):
match = pattern.search(string)
i = match.start() if match else -1
return i
def find3(string, subs):
i = -1
for sub in subs:
new_i = string.find(sub, 0, None if i == -1 else i + len(sub))
if new_i != -1:
i = new_i
return i
def find4(string, subs):
i = string.find(subs)
return i
def rfind0(string, chars):
i = len(string) - 1
while i >= 0 and string[i] not in chars:
i -= 1
return i
def rfind1(string, subs):
for i in range(len(string), -1, -1):
if string.startswith(subs, i):
break
else:
i = -1
return i
rfind2 = find2
def rfind3(string, subs):
i = -1
for sub in subs:
new_i = string.rfind(sub, 0 if i == -1 else i)
if new_i != -1:
i = new_i
return i
def rfind4(string, subs):
i = string.rfind(subs)
return i
benchmark script
# find_tuple.sh
echo find chars best case
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'ab' + '_' * 999_998; chars = 'ab'" "find_tuple.find0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'ab' + '_' * 999_998; subs = tuple('ab')" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = 'ab' + '_' * 999_998; pattern = re.compile('[ab]')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'ab' + '_' * 999_998; subs = 'ab'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'ab' + '_' * 999_998; subs = tuple('ab')" "find_tuple.find4(string, subs)"
echo find chars mixed case
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'b' + '_' * 999_999; chars = 'ab'" "find_tuple.find0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'b' + '_' * 999_999; subs = tuple('ab')" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = 'b' + '_' * 999_999; pattern = re.compile('[ab]')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'b' + '_' * 999_999; subs = 'ab'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'b' + '_' * 999_999; subs = tuple('ab')" "find_tuple.find4(string, subs)"
echo find chars worst case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; chars = 'ab'" "find_tuple.find0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple('ab')" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = '_' * 1_000_000; pattern = re.compile('[ab]')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple('ab')" "find_tuple.find4(string, subs)"
echo find subs best case
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'abcd' + '_' * 999_996; subs = 'ab', 'cd'" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = 'abcd' + '_' * 999_996; pattern = re.compile('ab|cd')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'abcd' + '_' * 999_996; subs = 'ab', 'cd'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'abcd' + '_' * 999_996; subs = 'ab', 'cd'" "find_tuple.find4(string, subs)"
echo find subs mixed case
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'cd' + '_' * 999_998; subs = 'ab', 'cd'" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = 'cd' + '_' * 999_998; pattern = re.compile('ab|cd')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'cd' + '_' * 999_998; subs = 'ab', 'cd'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = 'cd' + '_' * 999_998; subs = 'ab', 'cd'" "find_tuple.find4(string, subs)"
echo find subs worst case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = '_' * 1_000_000; pattern = re.compile('ab|cd')" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.find4(string, subs)"
echo find many prefixes
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'prefix{i}' for i in range(100))" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = '_' * 1_000_000; pattern = re.compile('|'.join(f'prefix{i}' for i in range(100)))" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'prefix{i}' for i in range(100))" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'prefix{i}' for i in range(100))" "find_tuple.find4(string, subs)"
echo find many infixes
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.find1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, re; string = '_' * 1_000_000; pattern = re.compile('|'.join(f'{i}infix{i}' for i in range(100)))" "find_tuple.find2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.find3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.find4(string, subs)"
echo ---
echo rfind chars best case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'ba'; chars = 'ab'" "find_tuple.rfind0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'ba'; subs = tuple('ab')" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 999_998 + 'ba'; pattern = regex.compile('(?r)[ab]')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'ba'; subs = 'ab'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'ba'; subs = tuple('ab')" "find_tuple.rfind4(string, subs)"
echo rfind chars mixed case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_999 + 'b'; chars = 'ab'" "find_tuple.rfind0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_999 + 'b'; subs = tuple('ab')" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 999_999 + 'b'; pattern = regex.compile('(?r)[ab]')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_999 + 'b'; subs = 'ab'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_999 + 'b'; subs = tuple('ab')" "find_tuple.rfind4(string, subs)"
echo rfind chars worst case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; chars = 'ab'" "find_tuple.rfind0(string, chars)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple('ab')" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 1_000_000; pattern = regex.compile('(?r)[ab]')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple('ab')" "find_tuple.rfind4(string, subs)"
echo rfind subs best case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_996 + 'cdab'; subs = 'ab', 'cd'" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 999_996 + 'cdab'; pattern = regex.compile('(?r)ab|cd')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_996 + 'cdab'; subs = 'ab', 'cd'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_996 + 'cdab'; subs = 'ab', 'cd'" "find_tuple.rfind4(string, subs)"
echo rfind subs mixed case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'cd'; subs = 'ab', 'cd'" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 999_998 + 'cd'; pattern = regex.compile('(?r)ab|cd')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'cd'; subs = 'ab', 'cd'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 999_998 + 'cd'; subs = 'ab', 'cd'" "find_tuple.rfind4(string, subs)"
echo rfind subs worst case
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 1_000_000; pattern = regex.compile('(?r)ab|cd')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = 'ab', 'cd'" "find_tuple.rfind4(string, subs)"
echo rfind many suffixes
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}suffix' for i in range(100))" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 1_000_000; pattern = regex.compile(f'(?r){'|'.join(f'{i}suffix' for i in range(100))}')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}suffix' for i in range(100))" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}suffix' for i in range(100))" "find_tuple.rfind4(string, subs)"
echo rfind many infixes
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.rfind1(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple, regex; string = '_' * 1_000_000; pattern = regex.compile(f'(?r){'|'.join(f'{i}infix{i}' for i in range(100))}')" "find_tuple.rfind2(string, pattern)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.rfind3(string, subs)"
find-tuple/python.exe -m timeit -s "import find_tuple; string = '_' * 1_000_000; subs = tuple(f'{i}infix{i}' for i in range(100))" "find_tuple.rfind4(string, subs)"
Examples
>>> "0123456789".find(("a", "b", "c"))
-1
>>> "0123456789".find(("0", "1", "2"))
0
>>> "0123456789".rfind(("7", "8", "9"))
9
Use cases
While I haven’t found a lot of use cases, this new addition would improve the readability and performance for all of them:
>2K files with /max\(\w+\.rfind/
Python implementation
The implementation written in Python is clear and simple (in C overflow and exceptions need to be handled manually):
MIN_CHUNK_SIZE = 32
MAX_CHUNK_SIZE = 16384
EXP_CHUNK_SIZE = 2
def find_tuple(string, subs, start=0, end=None):
end = len(string) if end is None else end
result = -1
chunk_size = MIN_CHUNK_SIZE
chunk_start = start
while True:
chunk_end = min(chunk_start + chunk_size, end)
if chunk_end < end:
chunk_end -= 1
for sub in subs:
sub_end = min(chunk_end + len(sub), end)
new_result = string.find(sub, chunk_start, sub_end)
if new_result != -1:
if new_result == chunk_start:
return new_result
chunk_end = new_result - 1 # Only allow earlier match
result = new_result
if result != -1 or chunk_end >= end:
return result # Found match or searched entire range
chunk_start = chunk_end + 1
chunk_size = min(chunk_size * EXP_CHUNK_SIZE, MAX_CHUNK_SIZE)
def rfind_tuple(string, subs, start=0, end=None):
end = len(string) if end is None else end
result = -1
chunk_size = MIN_CHUNK_SIZE
chunk_end = end
while True:
chunk_start = max(start, chunk_end - chunk_size)
if chunk_start > start:
chunk_start += 1
for sub in subs:
sub_end = min(chunk_end + len(sub), end)
new_result = string.rfind(sub, chunk_start, sub_end)
if new_result != -1:
if new_result == chunk_end:
return new_result
chunk_start = new_result + 1 # Only allow later match
result = new_result
if result != -1 or chunk_start <= start:
return result # Found match or searched entire range
chunk_end = chunk_start - 1
chunk_size = min(chunk_size * EXP_CHUNK_SIZE, MAX_CHUNK_SIZE)
Explanation
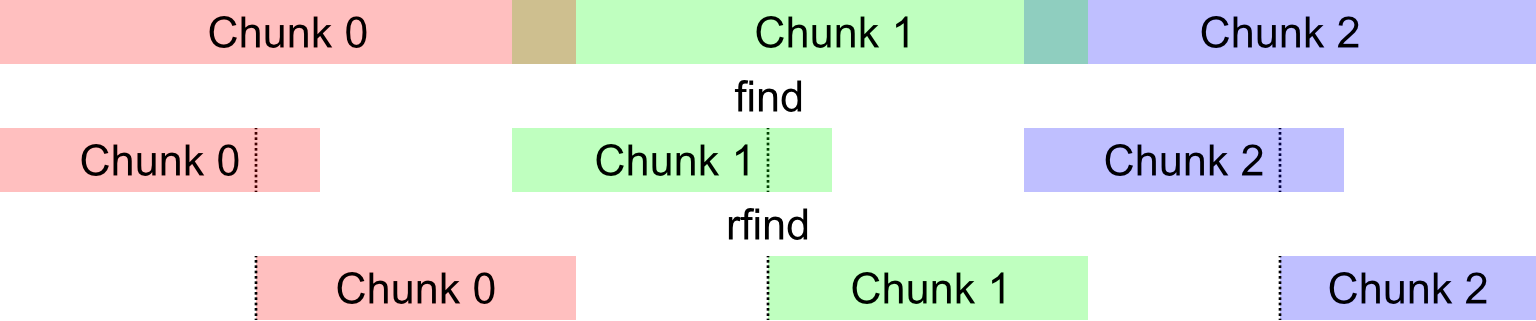
The search is split up in chunks, overlapping by the length of a substring. After the first match, we search for the next substring in the part before (or after for reverse search). Each chunk will be twice as large as the previous one, but capped at 16384. The dynamic size ensures good best- and worst-case performance.
C call hierarchy
find_sub() and find_subs() are called based on the argument type using an inline function. find_sub() is called for tuples of length 1, chunk_find_sub() is called for tuples with more than 1 element:
Calibration
MIN_CHUNK_SIZE and MAX_CHUNK_SIZE were calibrated on this benchmark:
- 32 was the highest mimimum size beating out all other algorithms in the best-case, setting it any lower would hurt performance for substrings after the first chunk.
- 16384 was the highest maximum size with a measurable improvement in the worst case, setting it any higher would only hurt performance in the average case.
| MIN_CHUNK_SIZE |
4 |
8 |
16 |
32 |
64 |
128 |
256 |
512 |
1024 |
unit |
| find chars best case |
1.01 |
1.00 |
1.07 |
1.09 |
1.06 |
1.10 |
1.06 |
1.10 |
1.10 |
x 66.7 nsec |
| find chars mixed case |
1.00 |
1.01 |
1.10 |
1.14 |
1.10 |
1.17 |
1.09 |
1.23 |
1.24 |
x 75.3 nsec |
| find subs best case |
1.00 |
1.01 |
1.02 |
1.05 |
1.00 |
1.04 |
1.01 |
1.01 |
1.01 |
x 70.9 nsec |
| find subs mixed case |
1.00 |
1.01 |
1.06 |
1.22 |
1.39 |
2.22 |
3.31 |
5.51 |
10.0 |
x 84.1 nsec |
| rfind chars best case |
1.02 |
1.01 |
1.02 |
1.00 |
1.01 |
1.00 |
1.00 |
1.03 |
1.02 |
x 92.9 nsec |
| rfind chars mixed case |
1.00 |
1.01 |
1.06 |
1.12 |
1.29 |
1.68 |
2.34 |
3.69 |
6.12 |
x 98.8 nsec |
| rfind subs best case |
1.00 |
1.01 |
1.02 |
1.01 |
1.03 |
1.00 |
1.00 |
1.02 |
1.02 |
x 96.9 nsec |
| rfind subs mixed case |
1.00 |
1.00 |
1.06 |
1.08 |
1.29 |
1.89 |
2.75 |
4.54 |
8.05 |
x 106 nsec |
| MAX_CHUNK_SIZE |
1024 |
2048 |
4096 |
8192 |
16384 |
32768 |
65536 |
unit |
| find chars worst case |
1.63 |
1.27 |
1.11 |
1.09 |
1.01 |
1.00 |
1.05 |
x 27.7 usec |
| find subs worst case |
1.03 |
1.01 |
1.00 |
1.00 |
1.00 |
1.03 |
1.00 |
x 1.47 msec |
| find many prefixes |
1.08 |
1.04 |
1.02 |
1.00 |
1.00 |
1.47 |
1.47 |
x 24.7 msec |
| find many infixes |
1.08 |
1.03 |
1.01 |
1.00 |
1.00 |
1.45 |
1.44 |
x 22.6 msec |
| rfind chars worst case |
1.20 |
1.00 |
1.17 |
1.17 |
1.01 |
1.01 |
1.15 |
x 1.03 msec |
| rfind subs worst case |
1.04 |
1.02 |
1.01 |
1.01 |
1.01 |
1.01 |
1.00 |
x 1.44 msec |
| rfind many suffixes |
1.09 |
1.04 |
1.02 |
1.01 |
1.00 |
1.00 |
1.00 |
x 24.4 msec |
Previous discussion