Fascinating, really! While I didn’t mention it, I also used array.array in my suffix array experiments, which are only slinging lists of ints, for similarly dramatic memory savings. Under PyPy that’s not needed.
The intro I referenced before says
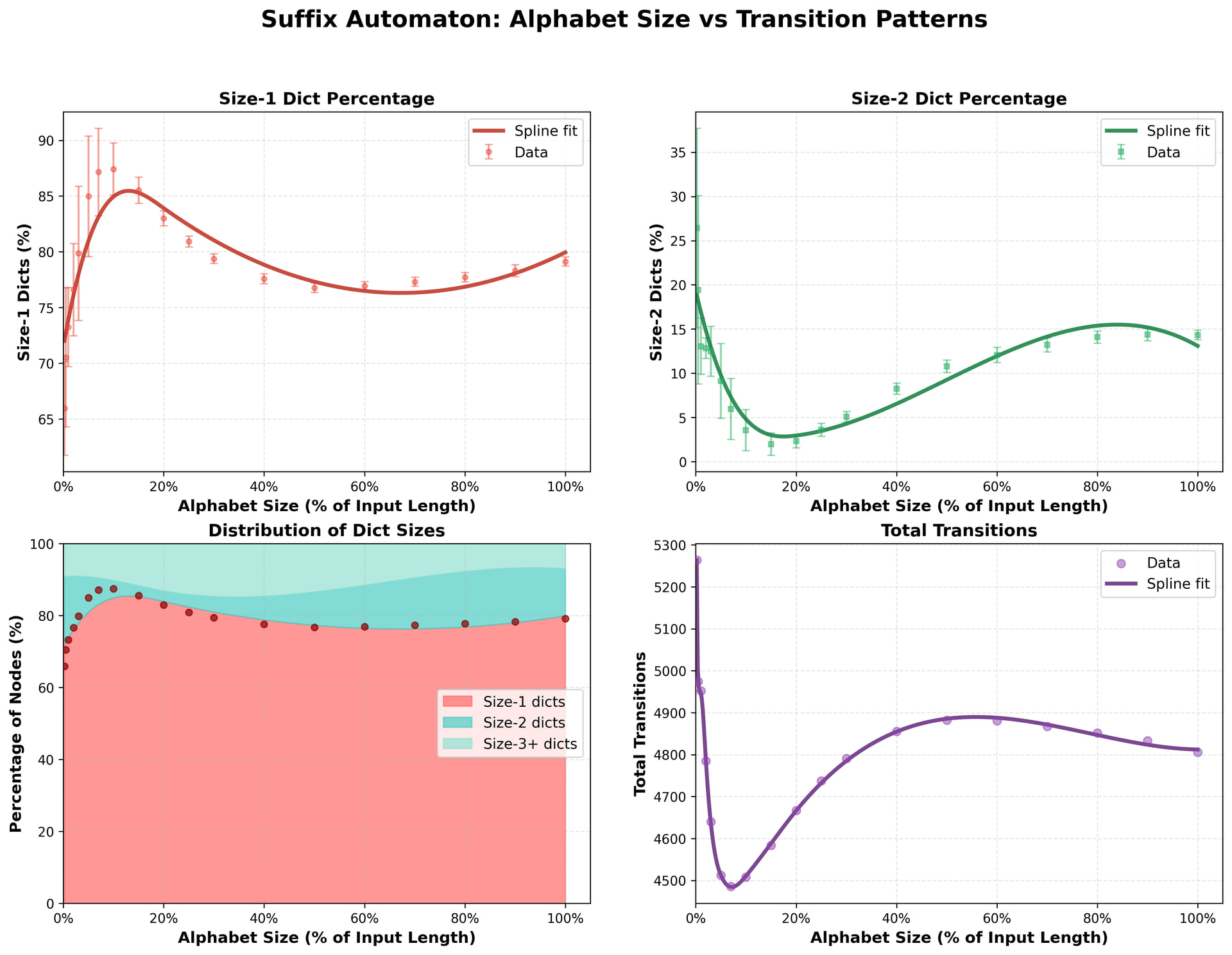
So the average number of transitions per state is at worst 3. If that’s right Since the number of states is bounded above by 2n-1, the average trans/state is likely materially less than 3.
However, for a large alphabet, like a list of lines, the number of transitions from the initial state alone is
len(set(list_of_lines))
That can be as large as n.
Which pretty much screams that dicts are very valuable here, but only in rare cases. Catering to just 1 or 2 transitions is bound to usually suffice, with the initial state being a prime exception.
Of course actually trying it on an alphabet with size much larger than 2 would be the prudent sanity check.
Agreed. Maybe postpone hybrid for later - I am now not even sure if it is worth it - it kind of takes control away from the user and I can not yet see a magic bullet where all is perfect without control.
Automaton, once built, is blazing fast and can be re-used for completely different a (or same a with different alo/ahi).
Hybrid might be avoiding build and calling simple method which is 10x faster.
However it all ends up 10x slower if called 100 times for the same b/blo/bhi.
Then how does
class ExactSequenceMatcher(BaseMatcher):
def __init__(self, isjunk=None, a='', b='', autojunk=False):
...
feel?
Automaton-only variant with autojunk=False by default.
And autojunk=False by default +100. Have already lamented the abuse of “junk” currently in play (intended to improve diff quality for motivated users, but abused by autojunk=True to “go fast” instead, and too often at the expense of quality and is never a good idea for small alphabets, for which “go fast” isn’t a problem for suffix automatons)
def get_case(case):
string = list(make_fib_xs())[-15]
if case == 'fib':
s1 = s2 = string
elif case == 'rng':
import random
random.seed(1)
N = len(string)
s1 = ''.join([chr(random.randint(1, 2)) for _ in range(N)])
s2 = ''.join([chr(random.randint(1, 2)) for _ in range(N)])
elif case == 'rng-N//10σ':
import random
random.seed(1)
N = len(string)
s1 = ''.join([chr(random.randint(1, N // 10)) for _ in range(N)])
s2 = ''.join([chr(random.randint(1, N // 10)) for _ in range(N)])
elif case == 'rng-N//2σ':
import random
random.seed(1)
N = len(string)
s1 = ''.join([chr(random.randint(1, N // 2)) for _ in range(N)])
s2 = ''.join([chr(random.randint(1, N // 2)) for _ in range(N)])
else:
raise ValueError
return s1, s2
This kind of covers it. 'rng-N//10σ' is about as bad as it gets (memory-wise). This is in relation to simple method
(which means alphabet size is 10% of total length)
Sorry, I wasn’t clear. I didn’t mean time or memory use, but the back-of-the-envelope musing about number of transitions per state. Of course with an alphabet of size 2, there can never be more than 2.
The speculation was that the average, across all states, would be under 3 transitions regardless of alphabet size, with the initial state suffering as many as n by itself.
If so, the case for always using a dict plummets. Of course a dict was never really helpful when the alphabet only had 2 characters.
Or, IOW, your specialization for 1- or 2-transition states was a big memory win for the 2-character alphabet you tried it on. Was that unique to tiny alphabets, or much more generally applicable? My guess is “yes, not at all unique to tiny alphabets”. That’s what I’m looking for a sanity check on.
Searching through a tiny list of transitions instead is much more memory-friendly, but can’t realistically be considered if the lists get large as the alphabet grows.
Thanks! In the meantime, bots assured me that an average of 3 transitions per state is a rigorous worst-case upper bound, regardless of input or alphabet size. following much the same line of argument I sketched.
For a single state, it can be much higher (in particular, the initial state has a number of transitions equal to the number of distinct characters in the input, which is the highest number of transitions any state can have).
Seems exploitable
It’s surprising! In general, a DFA can have a number of transitions quadratic in the number of states.
(up to and including) 1- and 2- transitions are optimized in Automaton 3 and Automaton 4 respectively
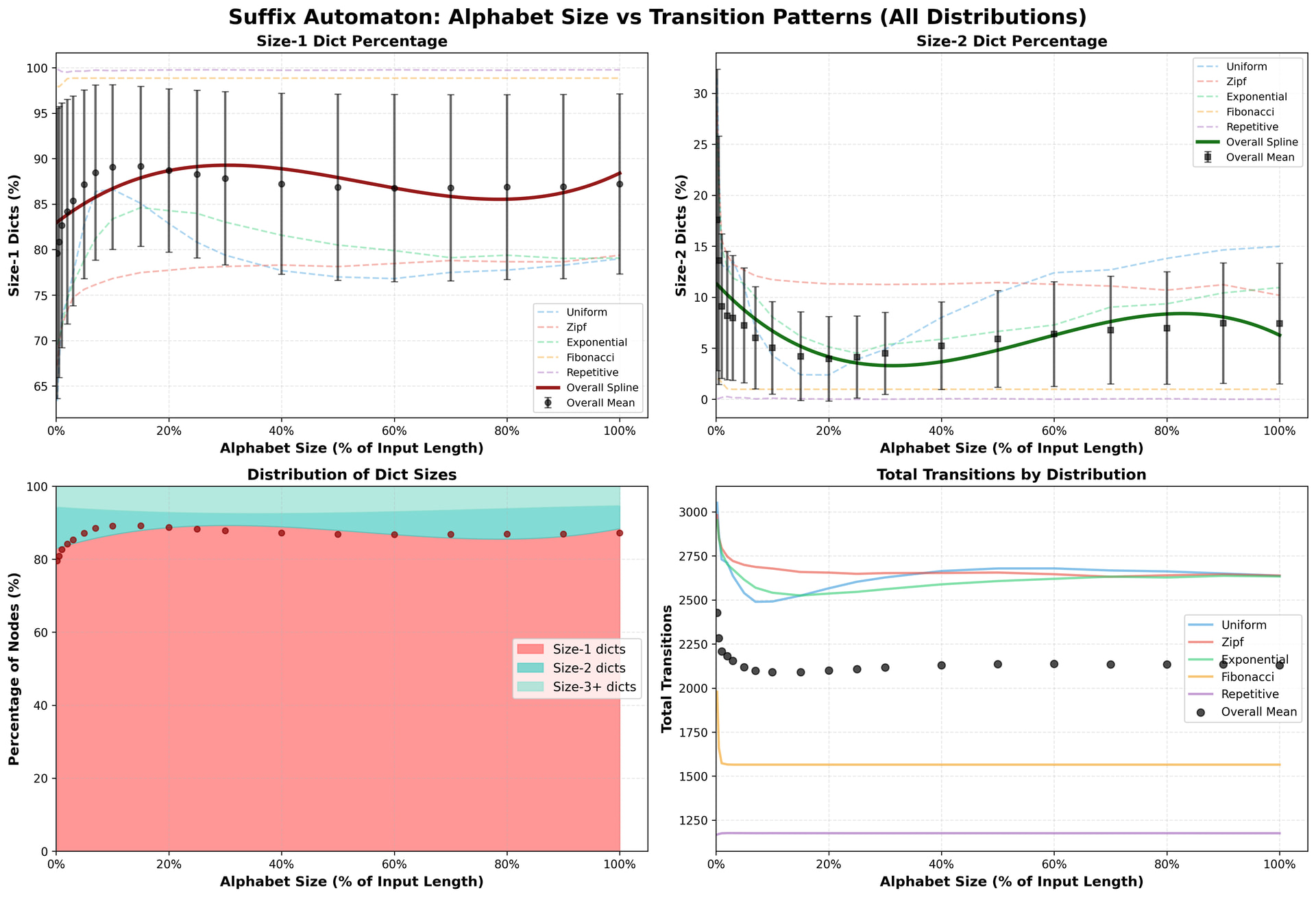
If 3-average is upper bound then this is all that is needed to know. By the way previous chart was only for random strings. Here are few more structures thrown into the pool.
It seems to me that 1- transition optimization covers most of it.
2- transition might not even be worth it, the implementation starts to not look very pleasant anymore with it…
Right, I realized that. Which is why I was so keen to figure out whether that was unique to using the smallest possible non-degenerate alphabet.
Although nothing about the input or alphabet is relevant to the upper bound of 3 on the average. It’s good to know, though, that just 1 transition is clearly the mode across all distributions you tried.
Exploiting just-1 certainly shows the most bang for the buck. Up to you! An alternative you may not like: never use a dict. Just live with a linear search through a state’s list of transition characters (and parallel list of corresponding transition targets). Then everything is spelled list.index(character).
May not be as scary as it sounds! The graph is acyclic, so we’ll only visit the initial state (which always has the largest number of transitions) once.
Or use a dict for the initial state once at the start, and leave the body of the searching code dict-free.
Or …
I wouldn’t want to see the code obfuscated by proliferating optimizations either. “But there’s usually just 1!” is just too juicy to resist
Automaton4 with cints takes less memory than simple approach.
In 1 case.
I think optimizing single transition is a good deal - it pretty much halves the memory.
Optimizing doubles has way less value - only 1 out of 4 cases are impactful here.
And no cints of course. In addition to obvious reasons, performance penalties are non-trivial.
Not under PyPy, though The vast bulk of RAM in the current approach is consumed by lists of small ints (b2j’s values), and PyPy stores them as raw machine ints.
Wholly agreed on all counts!
Offhand observation: while Fibonacci strings stress the snot out of many approaches, they appear to be an exceptionally good case for the new approach! All their fractal self-similarities appear to be things suffix automatons can exploit, sharing long stretches of identical substrings.
Why is it possible to get close (or even better) in memory consumption to suffix array?
It is because Automaton only compiles 1 sequence, while suffix array needs to process both at the same time (and do some work with both of them). Thus, although compiled memory should be low, memory peak can get quite high.
After construction of suffix array I put a sleep loop for a second so it can be clearly seen where building of sa and lsp stops.
So even with my best attempts, final size of built Automaton is twice as large (no cints, all Python objects here). However, if we are interested in peak, it is actually lower. And often by quite a lot.
Sure can! But there are many, many ways to build and use suffix arrays here. Some ways are aimed at minimizing memory use while building, and some are highly parallelizable.
For example, look for the DC3 (Difference Cover 3) algorithm which builds a suffix array in linear time by breaking the input into 3 interleaved pieces (based on their indices mod 3). Those 3 can be processed independently (even on different machines!), and then there’s an efficient (time and RAM) way to merge the results into a single suffix array.
And you don’t have to paste the haystack and needle together. For example, a genome can run into billions of base pairs, and for that kind of haystack, it’s searched over many times by researchers all over the world, and you never want to process the genome sequence again from scratch.
Instead for each suffix of the needle, you do a form of binary search over the haystack suffix array, to find the longest match starting with that suffix. That’s O(len(needle) * log(len(haystack))) time overall, but since the haystack doesn’t change the log term is effectively constant, giving O(len(needle)) time, albeit with a hidden constant factor that can grow to dozens.
Of course I skipped many details there.
BTW, there are parallelizable ways to build suffix automatons too. But, best I can tell, they mostly work by building on the massive amount of work that’s gone into parallelizing suffix array construction, and deduce the suffix automaton at the end from the suffix array.
But let’s drop the suffix array offshoot? Suffix automatons are clearly a better choice for our purposes, except for their hostility to slice-restricted haystack searches. That the peak memory use is lower is yet another point in their favor.
I conflated some different algorithms there, and don’t want to let wrong claims stand, but neither is it worth the time to straighten that all out here.
DC3 does work with elements based on their indices mod 3, but lumps 2/3rd of them into one array and the remaining into another. It’s not primarily aimed at parallelization, but rather at a linear-time recursive algorithm that can be written with remarkably short code. A practical limitation is that it relies on clever use of radix sorting, which requires representing characters as machine integers, so is a real strain for “giant alphabet” inputs.
Code is twice as long compared to previous candidate (in PR).
However, most of it is extra code that is needed for different structure, where nodes are stored in a list and navigation is by integer indices (as opposed to direct references) and the fact that each field now has its own list.
Also, this structure is much more GC friendly.
I am not sure if this is the real reason, but when using nested structure with self references for 1M sizes, my interpreter was taking a while to close.
Also, now the nodes can be printed and inspected.
Single-transition dict optimization is a small part of it.
The performance, compared to previous, is sometimes a bit better and sometimes a bit worse - memory optimizations had no significant impact here.
Lists of ints are much less work for cyclic gc to deal with, and I expect that accounts for it. At least one full gc collection is done as part of normal interpreter shutdown.
Even better is tuples of ints. There’s magical code that exempts them from being traversed by cyclic gc at all
That is, tuples are tracked by cyclic gc at first. But after the first time one is collected, gc detects whether it contains any elements that are tracked by cyclic gc. If not (and ints aren’t), the entire tuple is exempted from future cyclic gc scanning. Because tuples are immutable, the first decision about this is also the final decision.
You probably don’t want these lists to be tuples while building them, but converting to tuple when building is done is worth considering.
BTW, people are often puzzled by whether tuples are “suitable” for long sequences. Rest assured they are. They’re basically the same as lists under the covers, but a tiny bit more memory efficient (the space for the C array of PyObject* is in the tuple object, but is allocated separately for lists, because it may need to be resized).
Probably will not bother.
Lists need to be constructed anyway, so memory peak wouldn’t change.
Also, after conversion to tuples they will need to be deallocated.
Thus, it happens sooner or later.
And the creation itself can take time - e.g. 5 tuples of 1M length can take a bit of time.
To me this is a bit of surprise.
Given that initially I was thinking along the lines of single dict with tagged keys.
So I think the path is more or less clear.
I will finish couple of things and will draft new PR with all that has been considered here.
Which are the parts you see What you don’t see is that every time cyclic gc runs on a generation containing the SAM, it will need to crawl over every one of those 5M total list entries. With tuples instead, it’s a one-time cost (to figure out that it never needs to be done again).
But the same argument applies to the lists of ints in the current approach (b2j.values()), and I didn’t convert those to tuple either. But they’re generally short with a large alphabet, and autojunk can, unfortunately, make them nearly empty with a very small alphabet.
The new approach has far fewer lists, but generally much longer.
It’s not crucial regardless, just something to ponder. Suit yourself!
I meant I wasn’t surprised by that some cases ran a bit faster and others a bit slower, and that the memory savings didn’t much matter to runtime regardless. In the context of a real machine running a real, mixed workload, cutting memory has 2nd-order effects on speed, by reducing cache contention with other processes. Those aren’t visible when running intense single-program benchmarks.
I was certainly surprised that we discovered dicts are usually vast overkill to record a state’s transitions.
And I should note that in the context of cyclic gc, this is costlier than just iterating over the lists. gc_traverse() takes a callback argument. While the list itself iterates over its elements at full speed, it has to invoke the callback function on each list element.
Which is all done more than just once per cyclic collection. Cyclic gc knows nothing about the object graph apart from what those callback functions tell it, and it uses different callback functions at different times to learn what it needs to know at the time. It can’t afford the RAM to remember which objects a container contains, so instead asks anew each time that knowledge is needed.
Which typically doesn’t matter much. But it can become a drag when a long-running process hangs on to larger tracked (by cyclic gc) containers.
It cerrtainly shouldn’t drive anything here, though. Just another muddy tradeoff to consider