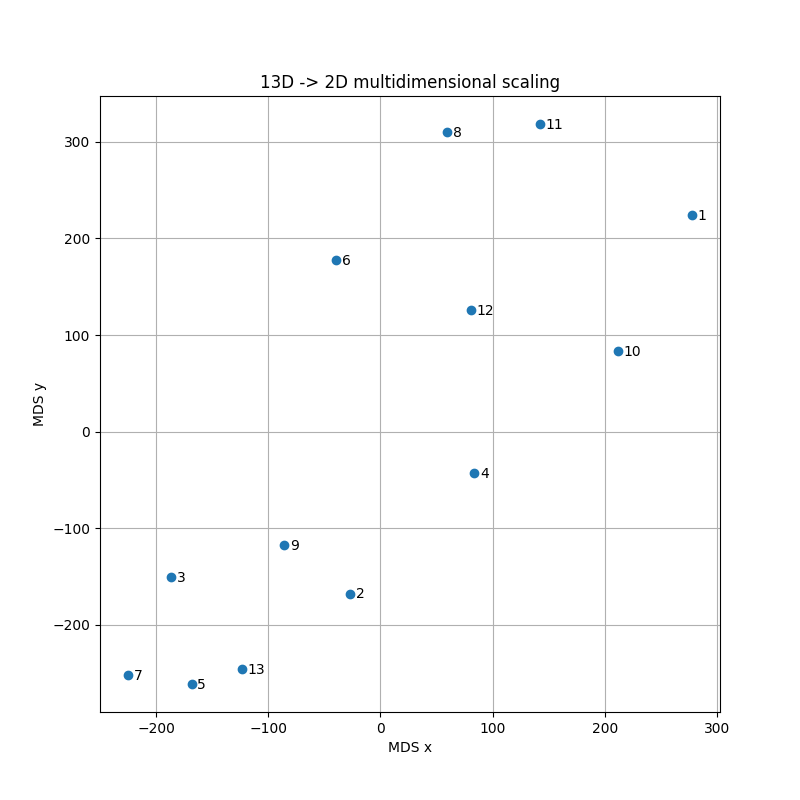
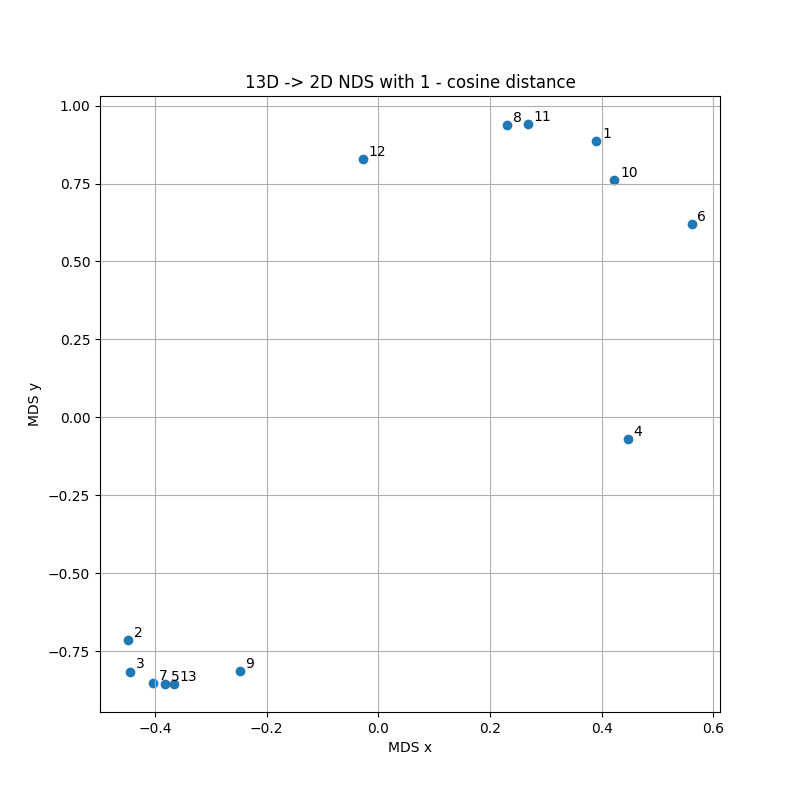
Clustering.
Another line of analysis is quantifying “how similar” ballots are. There were 2^{13} possible distinct ways to fill out a ballot in this election, but despite that we had only 683 ballots (which could cover no more than 9% of the possibilities), they were hardly all unique. They “clump”.
So how “similar” are two ballots? Given sets (of approvals, here) S and T, Hamming distance is a popular measure: len(S ^ T). It counts how many elements appear in only one. The smaller, the more similar. and 0 if and only if S == T.
But that’s unsatisfying in this context because it doesn’t take the size of the sets into account. {1} and {1, 2} have Hamming distance 1, same as {1,2,3,4,5,6,7,8} and {1,2,3,4,6,7,8}, but the latter pair is obviously “much more similar” than the former to human eyes.
“Jaccard similarity” is more on target: a float in 0.0 (the sets have nothing in common) to 1.0 (the sets are the same). If S and T are both empty, it’s 1.0. Else it’s len(S & T) / len(S | T), the number of elements in common divided by the number of distinct elements total. {1} and {1, 2} have similarity 1/2 by this measure, while{1,2,3,4,5,6,7,8} and {1,2,3,4,6,7,8} have similarity 7/8. Better.
Next, given a measure, how can we use it to group ballots into similar cluslters? There is no definitive answer to that. Consider a simpler context, grouping the ints 3, 4, 5 into maximal sets whose elements are “within 1” of each other. [{3, 4}, {5}] and [{3}, {4, 5}] both work for that. There just isn’t a unique grouping.
I use a common compromise. Start with an empty list of “equivalence classes” (an abuse of terminology, but helpful in context). Given a similarity floor minsim, the next ballot marches over that list, and adds the ballot to the first class found (if any) where every element in the class is at least within minsim of the new ballot. If no such class is found, the new ballot is added as a new singleton equivalence class.
So, a lot of preliminaries.
First thing to try is similarity 0. This puts all ballots into the same class:
Jaccard similarity 0 yields 1 equivalence class
1 class with 683 ballots each
Next is to try similarity 1. This breaks the ballots into classes each of which contains identical ballots. Output is ordered by deceasing cardinality of equivalence class:
Jaccard similarity 1 yields 338 equivalence classes
1 class with 23 ballots each
1 class with 15 ballots each
2 classes with 14 ballots each
2 classes with 11 ballots each
1 class with 10 ballots each
4 classes with 9 ballots each
7 classes with 8 ballots each
3 classes with 7 ballots each
2 classes with 6 ballots each
9 classes with 5 ballots each
9 classes with 4 ballots each
17 classes with 3 ballots each
48 classes with 2 ballots each
232 classes with 1 ballot each
So we had only 338 distinct ballots. The most populated class contained 23 ballots, which was identified before as the “I approve of everyone” ballot.
It’s at least “interesting”, e.g., that there were groups of 8 identical ballots, and that was so 7 times. The voters casting those ballots viewed the candidates the same way, However, the largest equivalence class had only 23 members, and in a situation where PR would make a major difference, the electorate would show much more duplication.
Coordinated gamers would try to “hide” their games by not casting identical ballots, but things don’t change all that much if the similarity threshold is cut to 80%:
Jaccard similarity 0.8 yields 265 equivalence classes
1 class with 31 ballots each
1 class with 17 ballots each
2 classes with 16 ballots each
1 class with 15 ballots each
3 classes with 14 ballots each
1 class with 12 ballots each
2 classes with 11 ballots each
3 classes with 10 ballots each
2 classes with 9 ballots each
4 classes with 8 ballots each
2 classes with 7 ballots each
4 classes with 6 ballots each
6 classes with 5 ballots each
11 classes with 4 ballots each
22 classes with 3 ballots each
54 classes with 2 ballots each
146 classes with 1 ballot each
There are numerous small groups of voters who voted much the same way, but PR aims to elevate small groups by kneecapping large groups, and there are no large sufficiently like-minded groups in sight.
In the limit, each voter is a minority of 1, and they can’t all win  ,.
,.