I don’t think people are ignoring that. I think people are finding a year+ on “clarifying” this wasted, when it leaves existing cases less clear, and is predicated on the author’s opinion that negation will fix this for people later. The people who have issues with the existing “status quo” are the people who see that this clarification doesn’t actually clear things up.
Here’s another case not currently clarified: TypeIs interaction. The current specification says typecheckers should treat TypeIs like isinstance. Does that mean that after this, even though TypeIs is in an annotation, that TypeIs[list[float]] narrows to a list of floats, not the Union?
That’s a bug in mypy, since the overloads overlap unsafely; you can use this to construct code that returns one type at runtime but that is inferred by mypy to return another. The fact that mypy currently doesn’t catch this is an indication that the current specification for the int/float/complex special case is too vague.
The proposed spec is quite clear: float means float | int in a type expression, and only in a type expression. “Type expression” is a precisely defined term (Type annotations — typing documentation). So TypeIs[list[float]] means TypeIs[list[float | int]], but passing float as a runtime argument to a function means just the class float.
So you’re explicitly proposing that we trade a case that’s wrong, but consistently wrong (subtype relation version), for a case that adds new levels of inconsistency, doesn’t account for something that the entire purpose of is a runtime check, and remains wrong?
I think this example actually demonstrates the point that the status quo isn’t necessarily doing what someone thinks it will, precisely because the spec isn’t clear and different type checkers have different behavior due to the imprecise language
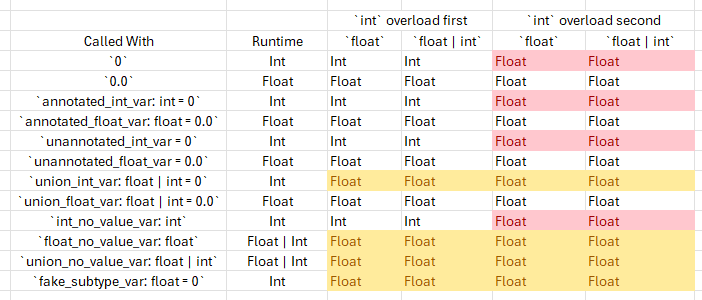
I expanded your example to have 4 different versions of the overloaded function, comparing:
float vs int | float in the overload
swapping the order of the two overloads
and also added calling each of those 4 versions 12 different ways:
int literal
float literal
variable annotated as int with a literal int value
variable annotated as float with a literal float value
unannotated variable with a literal int value
unannotated variable with a literal float value
variable annotated as float | int with a literal int value
variable annotated as float | int with a literal float value
uninitialized variable annotated as int
uninitialized variable annotated as float
uninitialized variable annotated as float | int
variable annotated as float with a literal int value (i.e. the special case)
Expanded example code
from typing import overload, reveal_type
class Int: ...
class Float: ...
@overload
def convert1(x: int) -> Int: ...
@overload
def convert1(x: float) -> Float: ...
def convert1(x: float | int) -> Float | Int:
if isinstance(x, int):
return Int()
elif isinstance(x, float):
return Float()
else:
raise TypeError
@overload
def convert2(x: int) -> Int: ...
@overload
def convert2(x: float | int) -> Float: ...
def convert2(x: float | int) -> Float | Int:
if isinstance(x, int):
return Int()
elif isinstance(x, float):
return Float()
else:
raise TypeError
@overload
def convert3(x: float) -> Float: ...
@overload
def convert3(x: int) -> Int: ...
def convert3(x: float | int) -> Float | Int:
if isinstance(x, int):
return Int()
elif isinstance(x, float):
return Float()
else:
raise TypeError
@overload
def convert4(x: float | int) -> Float: ...
@overload
def convert4(x: int) -> Int: ...
def convert4(x: float | int) -> Float | Int:
if isinstance(x, int):
return Int()
elif isinstance(x, float):
return Float()
else:
raise TypeError
reveal_type(convert1(0)) # mypy says Int, runtime will be Int
reveal_type(convert2(0)) # mypy says Int, runtime will be Int
reveal_type(convert3(0)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(0)) # mypy says Float, runtime will be Int - error
reveal_type(convert1(0.0)) # mypy says Float, runtime will be Float
reveal_type(convert2(0.0)) # mypy says Float, runtime will be Float
reveal_type(convert3(0.0)) # mypy says Float, runtime will be Float
reveal_type(convert4(0.0)) # mypy says Float, runtime will be Float
annotated_int_var: int = 0
reveal_type(convert1(annotated_int_var)) # mypy says Int, runtime will be Int
reveal_type(convert2(annotated_int_var)) # mypy says Int, runtime will be Int
reveal_type(convert3(annotated_int_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(annotated_int_var)) # mypy says Float, runtime will be Int - error
annotated_float_var: float = 0.0
reveal_type(convert1(annotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert2(annotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert3(annotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert4(annotated_float_var)) # mypy says Float, runtime will be Float
unannotated_int_var = 0
reveal_type(convert1(unannotated_int_var)) # mypy says Int, runtime will be Int
reveal_type(convert2(unannotated_int_var)) # mypy says Int, runtime will be Int
reveal_type(convert3(unannotated_int_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(unannotated_int_var)) # mypy says Float, runtime will be Int - error
unannotated_float_var = 0.0
reveal_type(convert1(unannotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert2(unannotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert3(unannotated_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert4(unannotated_float_var)) # mypy says Float, runtime will be Float
union_int_var: float | int = 0
reveal_type(convert1(union_int_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert2(union_int_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert3(union_int_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(union_int_var)) # mypy says Float, runtime will be Int - error
union_float_var: float | int = 0.0
reveal_type(convert1(union_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert2(union_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert3(union_float_var)) # mypy says Float, runtime will be Float
reveal_type(convert4(union_float_var)) # mypy says Float, runtime will be Float
int_no_value_var: int
reveal_type(convert1(int_no_value_var)) # mypy says Int, runtime will be Int
reveal_type(convert2(int_no_value_var)) # mypy says Int, runtime will be Int
reveal_type(convert3(int_no_value_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(int_no_value_var)) # mypy says Float, runtime will be Int - error
float_no_value_var: float
reveal_type(convert1(float_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert2(float_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert3(float_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert4(float_no_value_var)) # mypy says Float, runtime will be Float | Int - error
union_no_value_var: float | int
reveal_type(convert1(union_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert2(union_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert3(union_no_value_var)) # mypy says Float, runtime will be Float | Int - error
reveal_type(convert4(union_no_value_var)) # mypy says Float, runtime will be Float | Int - error
fake_subtype_var: float = 0
reveal_type(convert1(fake_subtype_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert2(fake_subtype_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert3(fake_subtype_var)) # mypy says Float, runtime will be Int - error
reveal_type(convert4(fake_subtype_var)) # mypy says Float, runtime will be Int - error
The difference you originally saw is just mypy not detecting the overlapping variants. The revealed types for all 12 call variants are identical and match the “expected” behavior mostly, as long as you put the “subtype” overload for int first
I think this is a misguided change, and that it’s simpler and more consistent to just remove the special case. That’s been argued before, and each time, the people in favor of just changing the special case just shift where the inconsistencies show up, but it’s impossible to remove them entirely without removing the special case.
I don’t agree that this is clear. The typing specification is a mess right now. The special cases that exist aren’t even on the same page as the things they interact with, nor are there references from the affected places to a set of “exceptions” to the rule, or even saying which conflicting rule takes precedence.
I also think this inconsistency is worse than an additional special case for TypeIs to remain consistent with isinstance, as both are for runtime checks, where the difference actually is seen in the available ways to check at runtime.
I don’t think this change is a positive, and despite saying people should propose removing it if they care about the inconsistencies, you’ve participated in shooting that down.
The special case here makes it very easy to return a type at runtime that mypy will misinterpret:
def f() -> float:
return 1
a = f()
print(a.hex())
Is that a bug in mypy or is it following the spec “correctly”?
The overloads shown do not overlap unsafely. I used the exact concrete types to map two types (int, float) to to others (Int, Float). There is nothing wrong with that except for a massive bug in the type system that fails to understand it. Any unsafeness in that example is purely in failures of the type system and type checkers and not in the actual code which is correct and not unsafe at all.
Reiterating again: these lines of argument are off-topic
This is the current spec’s behavior (maybe? hard to say since it’s unclear), the current behavior of all four type checkers I tried it in (mypy, pyright, pyrefly, and ty), and also the behavior with Jelle’s proposed change
Disagree with the int is a subtype of float specification all you want, but saying that this proposal is bad because of it is unhelpful at best and could uncharitably be viewed as trying to sink a good proposal so that the current experience stays bad because that helps motivate your preferred change (that has had major pushback)
I’m disagreeing with the change because it isn’t accomplishing what it claims to. There are new inconsistencies in the type system without an explicit statement of which rule is meant to win. When this was pointed out, instead of actually addressing that there are places that conflict, it was claimed to be clear.
I’m also disagreeing with the social aspect of taking a year to make this kind of clarification, not ensuring it actually clears up existing muddy cases, and claiming that the right way to remove the special case is to propose that, when the person who said that also shot that down over a year ago. It’s disingenuous at best.
Anyone absolutely has the right to say that you should make your own proposal and to disagree with your proposal. Jelle is not the Python Typing Dictator and did not single-handedly shoot down your proposal.
The closest anyone would be to that is Guido as the BDFL, and he also disagreed with your proposal
I don’t think these lines of argument should be off topic. The only reason to expend effort on changing this is to avoid fixing the actual issue people have been trying to fix for 8+ years, and that the author has consistently pushed against fixing.
It’s relevant, time people can spend on this kind of thing isn’t infinite. It’s also really irksome to have someone come back a year later on what was a contentious topic previously, and then claim it’s ready and refuse to acknowledge the couple things that still have contradictions in the specification.
The whole behavior here feels like an attempt to sneak in the assumption that this will never be fixed at a time hoping people are no longer engaged with it.
I’m against the change, but I can at least accept it if there is a clear ruling in the specification on which pieces of conflicting guidance take priority. That doesn’t exist in the current proposed form.
You can use “could be viewed” as a way of guarding your insinuations if you like but it does not make it less rude.
I don’t think that this proposal will bring any meaningful improvement to the user experience. That is not necessarily an argument against the proposal since it is not motivated by improving the user experience. This is just coordination among type checker authors to give some guidelines around a part of the type system that is defined to be contradictory.
The proposal can still have negative impacts though. I showed reasonable code above that currently passes with mypy. Apparently it is a bug that mypy accepts this and it should be rejected but it is very clearly correct code and I don’t think it is a coincidence that mypy accepts this correct code even though the acceptance involves something that some would call a bug (why wasn’t this bug fixed? Is it because it was already known that the fix would reject correct code?). Fixing the supposed bug and tightening the definitions means aiming for that correct code to be incorrectly rejected. The goal of the discussion here is for all type checkers to do that consistently rather than for any of them to recognise that the code is correct.
To me this proposal looks like trying to bring consistency out of a contradiction which is impossible. I agree that there is benefit in aiming for consistent behaviour across type checkers. As a type checker user who has problems with the int/float/complex mess though I expect that the end result of this will be that the type checkers will just be more confidently wrong than they were before.
The code you showed involves both runtime code and annotations. What you consider reasonable depends on your interpretation of the annotations. If you accept Jelle’s interpretation, then it is not “reasonable”, and it should be rejected by type checkers.
I don’t see how these questions and conjectures advance your argument.
This is begging the question (assuming what you’re trying to prove). According to this proposal, the code you showed is not “correct”, so it’s correct to reject it. I feel like you’ve made the assumption throughout your comment that your code should be seen as correct.
??? It’s correct. The type system isn’t. Nobody has argued that it is correct for int to be a replacement for float, only that it’s pragmatic for typecheckers to intentionally treat it incorrectly.
Just as disruptively as just removing the special case, while being less clear. Take the overloads I spelled out and replace the negation with that intersection, and it’s still obtuse. The special case is wrong. We shouldn’t be waiting on future type system features to fix this or spend effort intentionally making it more entrenched.
Formally, type NP should be narrowed to the intersection of A and R, and type NN should be narrowed to the intersection of A and the complement of R. In practice, the theoretic types for strict type guards cannot be expressed precisely in the Python type system. Type checkers should fall back on practical approximations of these types. As a rule of thumb, a type checker should use the same type narrowing logic – and get results that are consistent with – its handling of isinstance().
Matching the behavior of isinstance is only a rule of thumb, not the actual definition.
Yes they have argued that (and “they” here literally includes the designer of the language). int being a structural subtype of float has been the design intent of Python from the very beginning.
Quoting a handful of comments by Guido van Rossum on a related GitHub issue
I don’t really have anything to add to this conversation, except that I believe that historically when we wrote and accepted PEP 484, I personally believed that we were specifying that int was a subtype of float (and float a subtype of complex). Until today I wasn’t aware that the spec actually says that e.g. the type float should be interpreted, in certain contexts, as float | int. This is neither here nor there, it’s just an admission of my flawed understanding of the subtleties here at the time.
Why allow passing 42 to an API which requires a float?
Because Python users have been doing that for the last 30 years.
If we can guarantee that int <: float <: complex structurally, then there is no issue with the original wording in PEP-484, because users cannot observe the difference between the types.
That would be my preferred approach (and what I had in mind when we created PEP 484, nearly 10 years ago).
Python the language has been designed carefully to allow mixing floats and ints at runtime (some corner cases notwithstanding).
The intent is currently and has always been that int should be considered a subtype of float, regardless of the fact that isinstance(0, float) returns False
This was one of the original decisions about how typing should work in Python, has been in effect for over a decade, and reflects what the expected semantics have been for over 30 years (longer than I personally have been alive).
The issue that is being addressed is that it is not clear how that intent should be written in an unambiguous way in the formal specification that all type checker implementations should adhere to and can be tested for conformance against.
The current proposal on hand is to clarify that the way that structural subtype relationship should be handled across type checker implementations is that the type annotation float has the same meaning as the union of runtime floats and runtime ints.
This matches the current actual implementation behavior of every major type checker.
Disagreeing with the premise that int is a subtype of float does not help clarify how the formal specification should be written
3 of the 4 quotes there acknowledge that the status quo is broken and that there are issues with it.
Nobody is saying the language behavior of 30+ years should change, only that the acknowledged mistake in the original typing relation should change. People want typing to actually be able to express the language behavior. That’s not possible due to this special case.
It’s not a proper subtype of float, The contradiction here creates problems, and for the typing specification, it’s eminently relevant to why this is such a problem. The type system is largely defined in terms of subtyping relations, yet here’s a case that breaks that. The quotes you have above acknowledge as much. You aren’t presenting anything but a wall of quotes here that don’t even support your stance on this.
This is not about structural subtyping but about the nominal types int and float. There are many ways to define a protocol that works for both int and float but int is not a subclass of float and nor should it be.
PEP 484 was correct that the numeric tower is not a good basis for typing (or much at all really) but the shortcut taken with float was a mistake. All it said though was:
when an argument is annotated as having type float , an argument of type int is acceptable
This is a very specific statement that you can write e.g.
def cos(x: float) -> float:
...
y = cos(1)
It did not say that a list[float] can contain ints or that a variable annotated as float can be assigned an int value or anything else. It did not say that you can return int if the return type is annotated as float. It did not say that type checkers should treat float as allowing int even in the context of @overload and even if when doing so leads to “unsafe overlap”.
It did not say that it should be impossible to use @overload to express obvious type relationships that are widespread within Python like the convert function I showed. I can give many examples of this but hopefully this one makes it clear that there is nothing contrived about what that convert function is doing:
So the special case is not even useful for its original purpose.
Modelling this weird special case is awkward for type checkers. What should have happened is that over time the type checkers would figure out how to isolate this one special rule about function arguments as much as possible from contaminating the rest of the type system. Somehow instead though this has drifted the other way rendering all use of float in annotations as ambiguous.
The original idea in PEP 484 was misguided but it has evolved over time in precisely the wrong direction which now culminates in the proposal here that removes the possibility of being able to refer to the real float type as a nominal type altogether. The proposal here is for type checkers to standardise consistently on this broken behaviour.