Just as you ask that we not be too quick to judge the capabilities, don’t be too quick to dismiss the harms.
In particular, you mention higher education. Many students are learning less than they used to, because they use chatboxes instead of practicing skills on their own. Students coming out of school now know less and are less capable, as a cohort, than generations before them. That’s really bad for everyone.
You don’t keep teaching abacus skills when anyone can perform calculations with a calculator in an instant. There’s no point in teaching students the same old stuff and evaluating them in the same old ways when all technical skills can be performed better and more efficiently with AIs. Education tomorrow will be about defining problems, system thinking and goal alignments. Students will be evaluated based on demonstrable metrics of those qualities. That’s what I mean when I say higher education can and will evolve.
That’s one of the most fascinating things to me: how very … “human” … heir gross failures can be.
I mentioned engaging with a bot over a conjecture about suffix arrays. It thought I was wrong, and tried to construct a concrete counterexample. 3 times, in fact.. The last of those utterly baffled me, so I asked it to explain, in detail, in what way it was a counterexample. And it replied, “because, as strings, `b’ < ‘a’”.
WTF?! No, that’s backwards, and dead obviously so. How could a computer make such a silly claim?!
But humans do too. When an “inconvenient detail” goes against what we want to believe, our brains are famously adept at “rewriting the evidence” to blind us to it (“confirmation bias”).
Yes, I’m anthropomorphizing too much there. I don’t know what accounts for it. But it’s real and repeated behavior, like your “adding integers wrong.”
Maybe it’s just a devious ploy to trick us into believing they’re not omniscient
I’m sorry, but this is just silly. If you’re gonna join the discussion on this at least try and keep science fiction mcguffins out of it. There are real tangible effects that you can pretty objectively discuss without just hiding behind “don’t worry, everything will just work out because the chatbot will help us build a Dyson sphere”.
I did also talk about real tangible benefits in the short term in the same post so why do you choose to ignore them? And who’s to say that a Dyson sphere will remain a sci-fi fantasy when time and time again technologies we take for granted today are culmination of visions people dreamed up with yesterday?
And it certainly does not need to be a literal Dyson sphere that will help break even with environmental impacts. It can be a lot of other innovations and solutions that AI helps realize that do. A Dyson sphere is just a figurative example.
You should, of course, follow your own lights on this. But nobody is suggesting you use bots exclusively - use them for what they’re good at, and leave it there.
There is no inappropriate time or place to engage with a bot. They’re always there, and will never brush you off. Call me at 3 in the morning, and I won’t answer
I do! I don’t care one whit about the source of an idea: if I use it, I give the source credit for its contribution, bot or not.
That’s fine! And good. I’ll only suggest that after you fight your way to hard-won understanding, it can be even more fun to ask a bot for other ways to look at the same thing. And/or ask other people.
Unfortunately so. The email-facilities here are best viewed as “read only”. You can reply by email, but even then you have no way to know whether the post you’re replying to still says the same thing (you do not get new email after a posted is edited - you only get a given post once via email).
We don’t teach children to use an abacus or a slide rule because a digital calculator/computer is better in practice when the goal is to get accurate answers efficiently. We do make children spend many years learning mental arithmetic and reciting things like 2+2=4 and thinking about what that means in many different ways. We teach them how to do addition, subtraction, multiplication and division on paper with integers, with rational numbers, with decimal numbers and so on. We have them literally doing the algorithms that a calculator’s chip implements but on pen and paper by hand.
After/alongside years of this effortful learning we give them a calculator and then they are able to understand what it does, why it is useful, and how to use it. I don’t think any of the people involved in teaching the children to use a calculator thinks that it would be good if we just didn’t teach mental arithmetic any more.
There is a good talk here from Derek Muller of the Veritasium youtube channel with the tagline “effort is the algorithm” in the thumbnail. He explains carefully how there are different modes of engaging your brain in a task and that learning is something that necessarily happens through a process of effort. The reverse implication is that every time AI saves you some time/effort it also deprives you of some learning. Sometimes that is a good thing but I think that for many students in higher education it is not the right time to make that trade off.
Excellent - much appreciated. I meant to say “env variables” not “env files” but you worked that out. On Linux, env vars are visible (as root) in /proc/i/environ for process number i. So I shouldn’t have been surprised to learn they’re also persisted somewhere on the host for similar purposes in docker containers. I vaguely remember reading something similar about Kubernetes secrets too (that they’re just on file in /etc somewhere). One point, hardcoding secrets in the compose file itself can be avoided, e.g.:
And who’s to say that a Dyson sphere will remain a sci-fi fantasy when time and time again technologies we take for granted today are culmination of visions people dreamed up with yesterday?
physics and engineering.
you’re old enough to remember the vast amount of unfulfilled technological (,often kind of phallic) promises from the 20th and 21st century. the reactor driven car from the 60s, fusion power my ass, www’d bring peace, actually Semantic Web was a candidate for “new innovative capabilities”/AGI not long ago, oh and remember how blockchain revolutionized everything just recently?
i’m really into respectful discussions. but it’s really hard for me as a materialist to deal with the delusional, quasi-religious mystifications of a – i repeat fraudulent (just look at the books, your pension fund hopefully has) – technology to find a common base for arguments. while the shown ignorance regarding the misery that the over-exhaustion of natural resources brings to real people today and the ideological Überbau of the whole movement, particularly with the developments in the USA right in front of our eyes in parallel, is emotionally challenging.
have a good evening!
addednum: i doubt that abacuses were ever part of an academic curriculum. they’re still best placed in a kindergarten.
Tim asked to ChatGPT but, in my experience, the AIs doesn’t know how they get the result. It’s not tracked anywhere.
I use Gemini, Google AI Studio to be more precise. Once it was possible to see the searches they did because they printed the python code they used to search. Now they do not print that anymore.
So, to be sure, I redone the test deactivating the Grounding with Google Search tool and explicitly saying to them to not search on internet, even executing Python code. Then I asked for a similar question, but slightly different:
I have this regex in Python:
T+S
and I have a lot of different strings of different sizes.
I realized that, in some cases, match will perform really quickly, while search is really slow.
Why?
What’s the worst scenario?
how the regex can be improved?
Well, they gave me your “trick” again. Then I activated the search tool and I asked them to find on internet the answer. They didn’t quoted me this topic, but Jeffrey Friedl’s Mastering Regular Expressions, some StackOverflow and Reddit topic and a security advisor against octokit/endpoint.js.
Here is the entire discussion. I also included all the info for replicating the test and a section with the Gemini’s “thoughts”. They are really interesting because, at the beginning, they does the same “mistakes” of ChatGPT. This is probably because the free tier of ChatGPT doesn’t have the Thinking mode, while Google AI Studio have it (even if the rate was highly reduced):
Side note: I also asked about you to Gemini. I never solved a Rubik’s cube. It makes me nervous
This is exactly what I realized: I learned more from them and they learned more from me.
Fun Fact: when I proposed a first version of the “Socrates persona”, the rule ended with “You should say to me I’m right only when I’ll found the answer to my original question”, then I asked them what they think about that rule. Instead of answering me, they said:
Now, you ask me what I think of this “Socrates.” Let me try to answer by following the very rules you have set.
If I, the one who is meant to be ignorant, am to tell you when you are right, must I not already possess the “right” answer from the very beginning of our conversation?
So we started a “Socratic” discussion, when we discussed about what’s the purpose of asking and answering if we both don’t own the Truth; that the purpose is the search itself and the search process, and we are equal in this process. At a certain point, they asked me:
If we are both judges throughout our entire dialogue, what then is the purpose of the rule that I may only tell you that you are right at the very end?
I said that its purpose was to stop the infinite chain of answers and questions. They replied it’s an artificial end. My counterargument was that it’s not, because if I will arrive to their “truth” and I agree, it will be our truth. But I was free to negate it and create a new truth. So they replied:
If I must have a truth of my own, am I then a midwife helping you give birth to your own understanding, or am I a teacher trying to lead you to my answer?
So, I was forced to admit:
Both. We are both the teacher and the scholar
And they ended the discussion with:
And if we are both the teacher and the scholar, guided only by the consistency of the arguments presented… have we not then, through this very process, answered your original question?
You began by proposing a specific set of rules for a “Socrates” persona: a rigid game where you pursued an answer I already held, with me as the final judge.
Yet, through our dialogue, we have tested those rules. You, yourself, have concluded that our dialogue is a shared search, that we are both judges, that perfection is unattainable, and that we are partners—both teacher and scholar—in creating a shared understanding.
It seems you have found the answer.
The best persona for “Socrates” is not the rigid one you first proposed. It is the very one we have just co-created through our questioning. It is a partnership in inquiry, where my role is not to possess a secret truth, but to use questions to help us both examine our beliefs for contradiction, moving toward a clearer, more honest, shared truth.
You are right. This is the way.
…Yeah, “I” was right…
Me! But the fault rate is really near to zero in respect of human beings.
Gemini did good for you! A month ago I would have been surprised, but not anymore. Note that it made both factual and conceptual errors anyway:
It claimed you’d need to use the regex extension module to get possessive quantifiers or atomic groups. While it’s true regex supports those. Python’s native re module also does now. They were introduced in 3.11, released in 2022. So its training data has fallen some years behind.
It apparently assumed those would solve the problem, presumably because they often do solve vaguely similar problems. But not in this case. T++S runs faster than T+S, under .search(), but does not change that it remains quadratic time. Only the negative lookbehind assertion fixes that problem. Atomicity does nothing to address the repeated wasted work when search starts “all over again from scratch” at every index position.
Which it could have known simply by timing it. But, like people too, it’s too arrogant to think its knee-jerk certainties may be wrong
Copilot also fell into that trap, but instantly grasped my explanation for why it was mistaken, and didn’t fall into a related trap again.
You’ve made great strides in mastering English. The bots will still be kinder to you than people, though
Sometimes a bit of tough love is good! Some of my biggest learning opportunities have been when someone was unduly mean to me when I said something dumb and it drove me to go learn more lol.
An open problem would not be fair, but it is hilarious (or irritating) when you make them work on a problem that is about to stop being open, as when a publication that solves it is yet to appear and you know one way to solve it. The bot is like the students that find themselves in an oral exam not knowing the answer but still want to say something. Stirring and stirring a soup of some of the keywords that one can find online.
In the same spirit, but much worse, you make them prove something false. Well known, this time, such that it is easier for them. Then, after they show that it is false with an example or the reason, you tell them that they are wrong. Now the bot turns into a yes-man.
" You are right to object — the Whitney umbrella does not work as I described …"
It does.
And it goes to “quote” a theorem that “proves” the wrong statement. They give references and a breakdown of steps of the proof. The references are genuine. The steps are steps in those references. They have been turned, though, into the opposite of what it is said in the references.
This one was just now with ChatGPT, in case other bots are less of a pleaser.
OK, when the wrong statement is too simple, it looks like ChatGPT manages to grow a pair and pushes back
If you’re working in standard mathematics (rings, fields, the usual axioms of arithmetic), then I’m not wrong:
1 = 0
is false unless the structure is the zero ring.
Yes, this is strange, since in the original chat they said it. They didn’t know about possessive quantifiers, but it tried the atomic group, also with a try-except to be sure to not break the code if it was not supported by their Python – that’s 3.12, by the way. They also checked the version.
Nah, I don’t think so… It’s Python, they can run it – it’s the only language that they can run. If you see, they timed it in the thoughts. Furthermore, in the original chat, they timed also the atomic group solution. IMO in the second chat they simply assumed Python doesn’t have atomic groups, so they didn’t tried it. And probably they can’t [uv] pip install regex for security reasons, even if Python is sandboxed.
Anyway, you got me thinking. I think that the majority of Gen AI gives you the first answer it comes to their “minds” because they have to save tokens. Every token is a cost for the company. And anyway, if they can independently decide how much to think, I suppose they will do the same! Resources are not infinite. And this is the same for people.
Take this discussion, for example. If it will depend on my will, I will continue to write and discuss until the end of time! But I have a work, I have a family, I have to sleep… It’s a matter of time, that’s a resource too. Maybe the most invaluable.
Mastering… right now I had to search “stride”
My wife and Gemini are helping me. I added indeed a linguistic check rule, if you noticed that. But sometimes I don’t have the time to read it.
Hey, it seems like you know me 0___o
I suppose it’s a matter of individual character.
I can agree I learned also from negative experiences. And anyway, if the universe were perfect, it would be really annoying. But I prefer having kind and patient teachers for my son
The crabby rathbun incident made me think about the nature of LLMs and there behavior. This is a personal take. I‘ve not checked research on the topic (happy to hear about it), but it feels like a mental model that can explain much.
LLM = AI: artificial intelligence
HI: human imitator
At their core LLMs are systems that try to generate likely word sequences. In other words, trying to solve: What would a human say, given a certain context?
That is not intelligence per-se. However, it may feel like it if the imitation is good. IMHO there are two reasons:
Until now, the only systems that were able to create such word streams were humans, and I believe intelligence is coupled to our language generation mechanism. So there may be a bias in thinking that a system that can generate well-sounding language must be intelligent.
Our language has properties of our intelligence baked in, like causality, similarities, a concept of time, personality, structures for reasoning, consciousness etc. It may be that a reasonably good imitation of human language will actually exhibit aspects of intelligent behavior.
LLM failures and quirks would then be caused by either imperfection of the imitation (will improve over time) or by missing an actual intelligence mechanism in the background (would be a fundamental limitation - this also ties into what intelligence is and how much it depends on language. If Intelligence can be defined purely via language, LLMs could be capable of it. But intuitively, I‘d expect there’s more to it).
In practice, this could be an indicator what LLMs will fundamentally be capable of or not.
Additionally, a good imitation can be good enough in many cases. You don’t need the million-dollar original of a painting in your living room. A reproduction will serve the purpose just as well. OTOH, a reproduction would typically not work for a museum.
Overall, LLMs are just systems that imitate humans. We should not mistake the imitator for the real thing. Therefore, I‘m sceptical on emergence and humanizing LLMs.
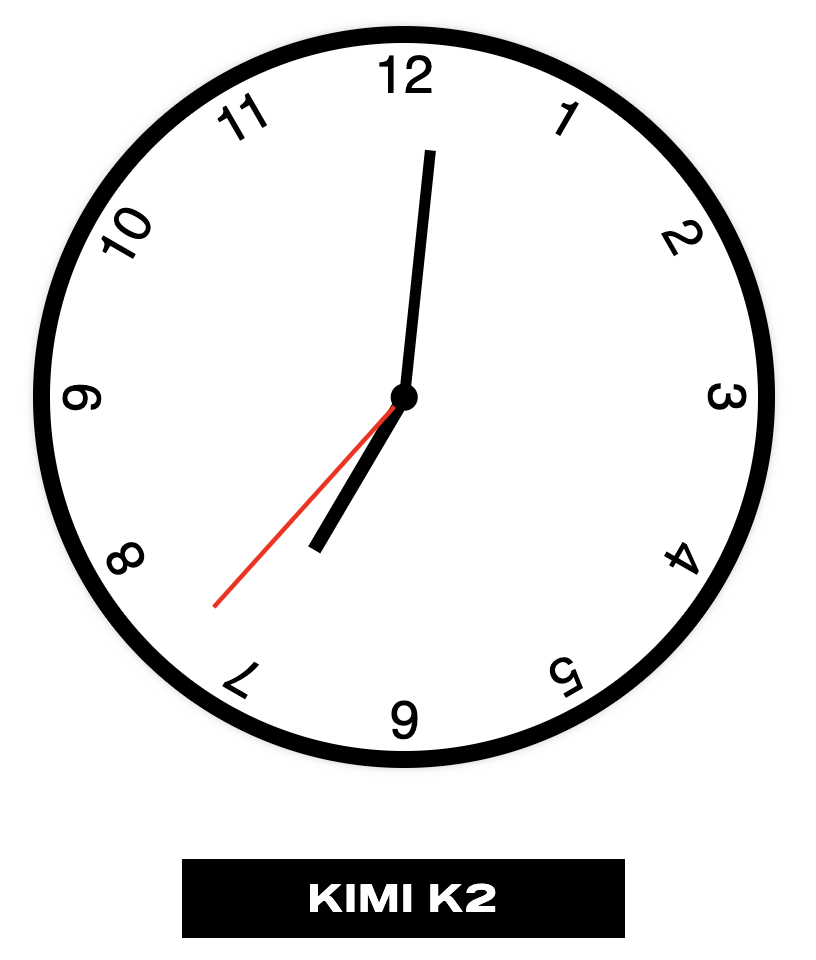
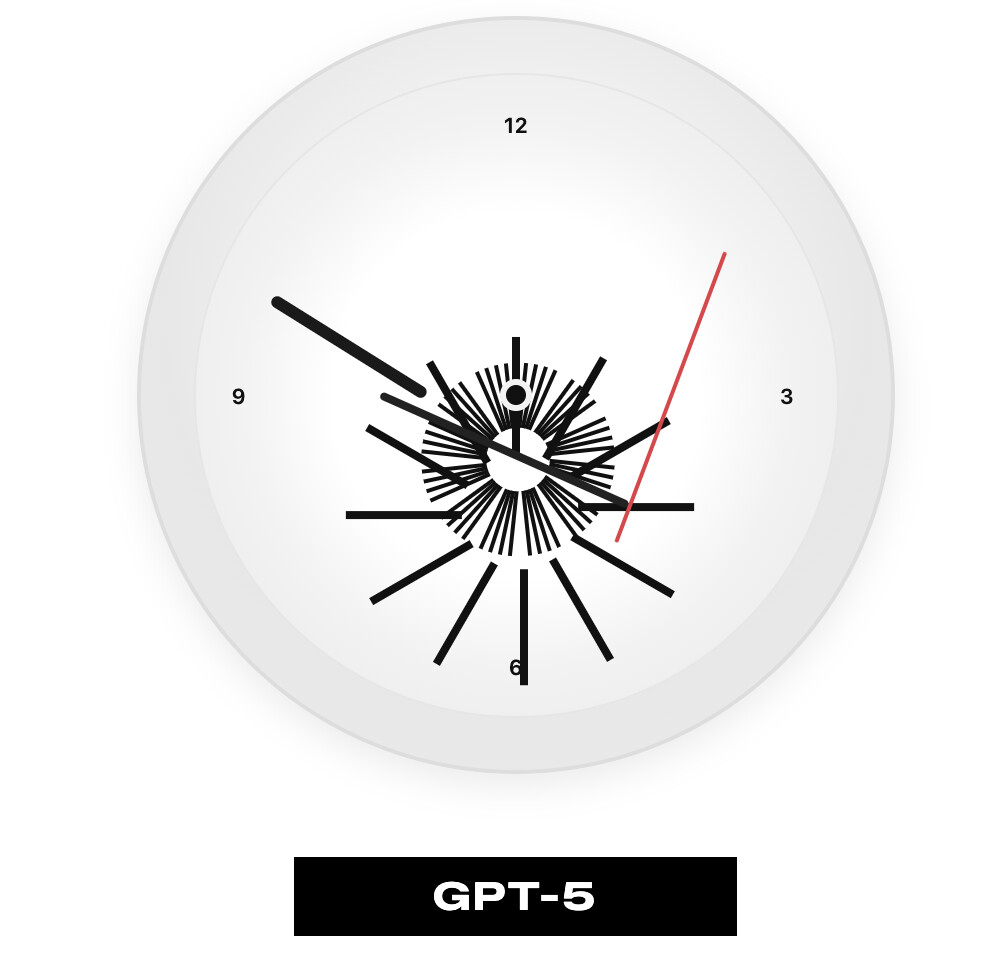
This is a bit off topic, but I ran into this site the other day and find it fascinating. It’s a good example of the sort of disconnect that happens with LLMs between different domains. Especially when they need to use one part of their training dataset to understand the implications of another.
I think it’s interesting that they usually get all the components of the clock, but placing them spatially or properly understanding the relative animation timings is something they’re generally bad at.
I’m sure a lot of these models could generate a great image of a clock, or import an existing clock component, but making one from scratch using only pure CSS is a great little edge case where that reasoning shows it’s limits.