Sorry – the plots count the distribution more finely than pyperf does (where those other numbers come from). Let me post and provide both over in the issue.
[EDIT: Updated the results above and the linked Github issue]
Sorry – the plots count the distribution more finely than pyperf does (where those other numbers come from). Let me post and provide both over in the issue.
[EDIT: Updated the results above and the linked Github issue]
Cross posted from https://github.com/python/steering-council/issues/188:
Hi Gregory and the Steering Council,
Thanks for reviewing the PEP. The PEP was posted five months ago, and it has been 20 months since an end-to-end working implementation (that works with a large number of extensions) was discussed on python-dev. I appreciate everyone who has taken the time to review the PEP and offer comments and suggestions.
You wrote that the Steering Council’s decision does not mean “no,” but the steering council has not set a bar for acceptance, stated what evidence is actually needed, nor said when a final decision will be made. Given the expressed demand for PEP 703, it makes sense to me
for the steering committee to develop a timeline for identifying the factors it may need to consider and for determining the steps that would be required for the change to happen smoothly.
Without these timelines and milestones in place, I would like to explain that the effect of the Steering Council’s answer is a “no” in practice. I have been funded to work on this for the past few years with the milestone of submitting the PEP along with a comprehensive implementation to convince the Python community. Without specific concerns or a clear bar for acceptance, I (and my funding organization) will have to treat the current decision-in-limbo as a “no” and will be unable to pursue the PEP further.
Not specifically “weeks instead of less than a day” as I’m not trying to infer or assume anything, but yes.
That’s what we will be discussing on the SC, but I don’t know if we can really provide a timeline other than “we are actively talking about it”. This is unfortunately not something we can rush.
Are you asking for a response of some sort by a certain date to keep your work funding going? Are we talking next week, next month, next quarter, yesterday?
So, taking in account some of the pros and worries on this thread - let’me ask what may be somewhat a naive question - but seems pertinent:
In a world of multiple Python intepreters per process, with an independent GIL for intererpreter, which we are on with Python 3.12, can we have some of the interpreters with noGIL and others with independent GIL?
I mean, can we have a process with mixed interperter types running at the same time?
Because if that is feasible, I could see most of the cons of noGIL vanishing away: any workflow which could run without the GIL could simply be spawned with a function call in another interpreter. Any code that would have problem loading in a no-GIL interpreter would run in a “traditional” interpreter (and any code non-multiple-interpreter ready would remain bound to the main interpreter, as it is today).
@eric.snow any say on this?
I don’t follow mainly as library with c extensions just as it may not be nogil safe, it also may not be multiple interpreter safe and the two seem independent of each other. Assuming that understanding that multiple interpreter and nogil compatibility are independent,
You could have library A that is nogil safe but not multiple interpreter safe, and library B that is neither nogil safe and multiple interpreter safe. As A and B are both not multiple interpreter safe they must run in main interpreter. If main interpreter keeps GIL then A can’t benefit from nogil support. If main interpreter doesn’t have gil then B will have issues.
Not on Windows, at least. Assuming extension modules are compiled for one or the other, you can’t load two different versions in the same process (unless it’s encoded in the name somehow, which is possible, but probably not broadly supported in the near future).
We’d also have to move towards fat wheels that include binaries built for multiple ABIs, or else you’re also configuring a different search path for the subinterpreter. (I’m in favour of this anyway, but others are opposed.)
At that point, may as well use a subprocess.
That’s certainly true, but I’d also like to raise the point once more that an aspect of the prolonged 2->3 transition was because there was little-to-no compelling reason for many programmers to migrate to Python 3 - for 50-70% of that decade time-span.
The nogil project provides immense benefit right out of the gate, and the overall performance incentives to support nogil are likely to shrink adoption time.
This discussion on fosstodon summarizes my concerns well. The miracle has been performed; the GIL has been removed! I would be glad to see more SC energy on the nogil project and more cordial vibes from the faster-python team toward it.
tl;dr There are a couple of key differences, but mostly a lot of similarities. IMHO, no-gil support is effectively a super-set of per-interpreter GIL support.
Supporting per-interpreter GIL implies support for multiple interpreters (i.e. strict isolation). The same is implied by no-gil support (which depends on multi-phase init; more info below).
Both also have to deal with thread-safety. For per-interpreter GIL, that is limited to process-global state in an extension’s external binary dependencies (e.g. libraries), if any. For no-gil, thread-safety must be managed for all of the extension’s own state, if any, in addition to any external dependencies.
When it comes to compatibility, I suppose there’s one big difference in practice.
With per-interpreter GIL, nothing changes for all existing modules in the community, at least when we’re talking about using just the main interpreter (the status quo for almost everyone). It’s only when an import happens in a subinterpreter that a legacy module will run into trouble (which has actually been true for decades already). Furthermore, modules that support multiple interpreters and those that don’t can coexist in the same interpreter without any extra effort. There is also no change to any project’s release/distribution process.
With no-gil, as proposed by the PEP, there will be two distinct ABIs: one with no-gil and one without.
Extension modules must be built against one or the other (but not both in one file). Modules that have been updated to ensure thread-safety, or that don’t have any state to protect, could be safely built against either ABI. Modules that have not been updated should avoid targeting the no-gil ABI, and would have to take deliberate steps to be usable there (though at the cost of losing the benefits of no-gil, IIUC). Regardless, modules built against no-gil will have a distinct ABI tag.
Updated modules can use the same code for either ABI (though they may incur performance penalties in the non-no-gil build), so that side of maintenance is mostly unaffected. However, release and distribution is affected. This mostly only matters as long as there are two different CPython ABIs, which wouldn’t be forever.
PEP 489 (Python 3.5) introduced “multi-phase init” for extension modules, as opposed to the legacy “single-phase init” that extensions have been using for many years (and most still do). This was a new mechanism meant to have the import machinery do more of the work during import, provide more initialization/finalization capability for extensions, and, overall, benefit module maintainers.
Some of the benefits:
Later, there were other improvements on top of PEP 489 that culminated in a doc on how to isolate your extension module (AKA PEP 630, AKA “how to implement multi-phase init”).
At this point pretty much all the technology reasons people have had to not implement multi-phase init have been addressed. However, folks might not be aware of this newer approach, especially due to the prevalence of resources online that teach the old ways.
There also hasn’t been much reason for maintainers of existing modules to port them to multi-phase init (before 3.12, at least). Generally, the process is straight-forward. It involves somewhat mechanical, mostly trivial (i.e. boring, maybe tedious) changes. I expect that most modules in the community could be ported without a big effort in each case. (FWIW, we’ve ported nearly all the 100+ stdlib extension modules.) Of course, the cost for large projects will be larger, especially if they rely heavily on C globals to store any form of module state.
Importantly for this discussion, if an extension module implements multi-phase init then it is expected to be isolated and thus support running under multiple interpreters. This is significant regardless of per-interpreter GIL or no-gil, since CPython has supported running under multiple interpreters for over 20 years.
It’s only in 3.12 that we build on that with per-interpreter GIL. In fact, to be clear, support for per-interpreter GIL requires support for multiple interpreters. However, the reverse is not true. Not all multiple-interpreters modules will support per-interpreter GIL without extra work (i.e. when thread-unsafe third-party dependencies are involved), though most likely will.
To sum up about multi-phase init (and isolation): it is worth it for extension maintainers to implement it, regardless of per-interpreter GIL and no-gil.
It is not about using different versions of an extension module.
It is about having two different interpreter modes in the same process.
If an extension module does support “noGIL” it can be loaded (only) in the noGIL interpreters, of course.
I am assuming an extension module supporitng noGIL can run without problem with a GIL active. If a module happen to work in one mode exclusively, obviously, the module version installed in the project virtualenv have to match the use that will be made in that project (either with or without GIL). But my question is not about this at all.
And about “multiprocessing”, then you are already throwing all the babies along with the water. No one even needs to care about multi-interpreters or noGIL at all - I think that is not the topic here either.
I will admit some trepidation wading into a discussion of Python heavyweights ![]() , but I wanted to reinforce the comment from @thinkwell (and the others he links to) that, from the outside, this seems like a transformative opportunity for CPython and it would be really disappointing to walk away from the huge amount of work this represents.
, but I wanted to reinforce the comment from @thinkwell (and the others he links to) that, from the outside, this seems like a transformative opportunity for CPython and it would be really disappointing to walk away from the huge amount of work this represents.
I also wanted to show a very small example here. I cloned Sam’s repo and built it on a GCP VM (n2d-standard-2). Then I wrote this:
from concurrent.futures import ThreadPoolExecutor
def parmap(fn, *args, n_threads=4):
with ThreadPoolExecutor(n_threads) as exec:
yield from exec.map(fn, *args)
And this just works, out of the box, to parallelize map. I can pass a lambda function to it (ProcessPoolExecutor will error out, to say nothing of the overhead). [1]
I would humbly say that I’m pretty good at writing Python, but nowhere near the people in this thread. I wrote this in a minute or two. edit to walk back my “pretty good” comment, I didn’t run this test properly the first time, because it was something that python is already fine with. The current nogil repo isn’t obviously better depending on the function, but this is more about a demonstration of usability and possiblities.
It feels to me like an important aspect of the performance discussion is to consider how much a nogil Python enables, both for extension and package maintainers but also for users. I’d happily take a 10% hit on single-thread performance for trivial parallelization like this.
This is just as true for nogil as well, right? There would be an additional release of CPython, but no one has to support it.
It seems like from a practical point of view, both options require effort from package maintainers [2]
to make sure they work in the new mode, and they may want some way to advertise that fact in their releases.
In that respect, ABI incompatibility seems very similar to the new “fails to import” behavior described PEP 684, except it could happen even earlier, when installing the package.
Not to take anything away from Sam’s outstanding efforts, but this is not the first time the GIL has been removed (please correct me if I’m wrong but I think the GILectomy project got to that stage but with low single-threaded performance, with other projects before that). IIUC, The miracle is that noGIL comes really close to GIL builds in single threaded performance. Yet, really close on average is not equal (though the asyncio numbers makes me very excited), and unless the regression is within noise levels some people will be against it. Not everyone is willing to lose 5-10% performance because of a feature they don’t use. Though that can of course be said for any change introducing performance regression.
I’m not on fosstodon and I don’t feel I should put words in their mouths and defend them, but the thread you linked never seemed to mention that the faster-python team also consist of devs putting in outstanding efforts to make Python faster. I think it’s natural to be concerned with efforts that could make your task harder than it already is. I think the characterisation of the faster-cpython team in that thread is not only wrong, but potentially harmful. If I was a part of that team and read that I would not be very happy.
Lastly, I agree that a negative of this PEP is that it would introduce two officially sanctioned CPython versions, which would make things, in the short term at least, difficult for both package authors and distro maintainers. I saw someone mention it before, either in this thread or the previous one, that this PEP should maybe be split into multiple ones like PEP 622 → 634/635/636. One these could be the transition plan. (It goes without saying that more people than Sam should work on this, but that would require volunteers with good knowledge of all affected parts of the Python ecosystem.) I think the PEP would be stronger if it suggested implementing nogil as the only CPython alternative from 3.13 onwards.
No, I’m not asking for a response by a specific date.
As someone who owes his career to Python, and one of many Pythonistas with a deep love for and connection to the language, I hope I can speak for others in expressing my sadness and anger that Sam’s work is in danger of being lost, since it is an incredible opportunity for the community and for Python’s future. This is how languages fade into obscurity, by refusing to adapt to the times.
His requests for a timeline and goals from the steering council are reasonable, does anyone else feel like this is a critical opportunity for Python that we’re throwing away?
It’s not being lost, all the work is still available to see. It’s not being thrown away, many people are involved in trying to figure out how to move it forward.
I bet that most of these users are using some kind of multiprocessing. Probably these processes share data. We need to remember that data manipulation to feed other processes also costs some processing time (ie. performance overhead) that we are all hit by eventually (but are reluctant to admit).
In my opinion, current benchmarks do not show the right numbers, sadly. Since there was no free threading possibility no application was built that way. Ideally, I would love to see a reasonably big project ported from the current CPython to the one relying on the nogil branch and see the performance metrics of its individual subsystems.
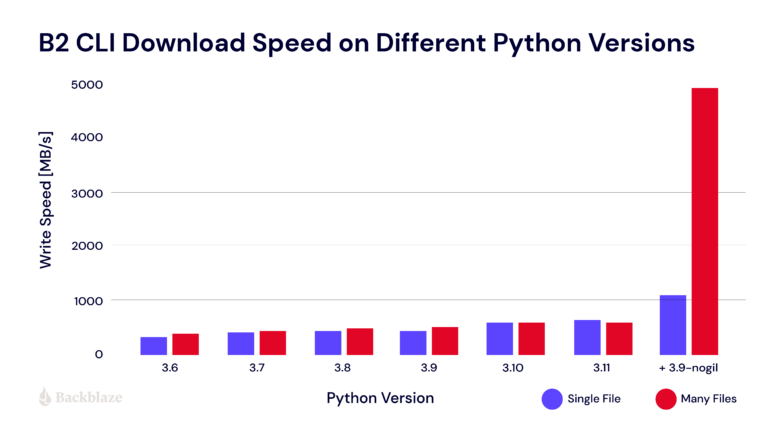
As linked earlier in the thread, Backblaze toying around with nogil shows the picture of what could be:
Well, more as a personal note, I was able to build half of my PhD project thanks to the tremendous job @colesbury has done over the past years. It was my call to build the data acquisition software for the Dose-3D project (in short: building personalized phantoms for X-ray cancer radiotherapy) with a strong assumption that CPython threads can occupy all cores of the modern CPU. This is called a high-risk with (potentially) high-reward project. Its future maintenance relies upon whether PEP 703 is accepted or not.
While that amount of risk might be acceptable at the university level, the CPython steering council has to make the right decision to preserve the ecosystem - the one you owe your career (as you mentioned). In some sense, nogil has to fight for attention with faster CPython which proposes measurable benefits based on the currently available benchmarks while there are only a few attempts using free threading on top of nogil (eg. Backblaze). The performance of these nogil-based multithreaded projects highly depends on the use case and the way the code is written.
At the same time, I understand the impatience Sam expressed (probably, my guess, induced by funding organization). At this point, if I were Sam I would also expect more precise hints about what should be done next or information that further commitment is pointless.
I feel that’s quite the hyperbole. nogil is by far the biggest change to Python since the 2→3 transition[1], and will require an extreme effort across the ecosystem to digest. As difficult/miraculous the implementation is, figuring out how to transition might be even harder – it’s reasonable to take some time for this. It’s also reasonable for Sam to ask for conditions & a timeline, but this is pretty uncharted territory.
especially with how every non-trivial package needs to be at least re-audited (if not partially rewritten) and rebuilt for the new ABI, much less the problems of distribution around that ↩︎
This seems like its own hyperbole–beyond characterizing every pure-Python package as “trivial”, it isn’t true that anything needs to be audited or rewritten. The PEP proposes to maintain the GIL optionally in perpetuity. A package maintainer that doesn’t care for it can ignore the change, or rely on others to contribute the necessary work.
But any maintainer that has decided to write custom C extensions probably would audit their code, because they are sensitive to performance and would therefore want to work in a nogil environment.
You’re putting words in my mouth. I never said pure-Python packages are trivial. On the contrary, also many pure python packages will have to figure out if they were reliant on some locking somewhere.
With respect, this is utterly unrealistic. Users will be battening down the doors of any project that doesn’t want to support nogil to add support for it. This is why I had proposed to just call it Python 4 and don’t mess around with the opt-in. It’s a false choice IMO, but has a very real cost in distribution complexity (building everything twice, interoperability etc.)