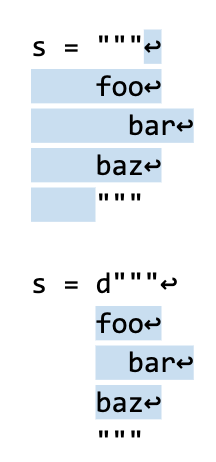This is a wonderful PEP, thank you for your hard work.
I have to say that I don’t find the trailing ‘\n’ intuitive at all, even after reading more of the posts in this thread (and having read the original thread a while ago).
Obviously this is steeped in personal taste, but I also think It will be easier to compose blocks of text together if the trailing line is remove.
def hello_paragraph(name):
"""assuming no trailing"""
return df"""
<p>
hello {name}!
</p>
"""
hello_world = hello_paragraph('world')
body = df"""
<body>
{hello_world.replace("\n", "\n ")}
</body>
"""
assert body == "<body>\n <p>\n hello world!\n </p>\n</body>"
print(body)
<body>
<p>
hello world!
</p>
</body>
I think referring to POSIX line definition is not really relevant to most string processing in python: taking "a\nb".splitline() for example will give a length a list of length 2, and the common "\n".join(...) idiom doesn’t add a trailing “\n”. It’s only at the edge of the program, when writing to file, when POSIX lines is relevant.
Even then, writing "a\nb\n" with the trailing line, then opening the file in an editor (vs code) shows up as something like
1 a
2 b
3
So to me, and I’m guessing the majority of newer programmer, the “obvious” way do this with d-strings is to wrap the whole thing with triple quotes: They “look” almost like braces.
d"""
a
b
"""
I think in general it will be easier to explicitly write trailing newlines when needed than having to explicitly remove it when needed.
I think adding a supporting format specs for indentation-composition could solve this: If there is a definite, privileged “One obvious way” of making, indenting, and composing text blocks together, that would solve any personal preferences issue.
Even/especially if all the format spec does is some trivial function like .strip().replace()
hello_world_block = ...
# Exactly one of this is the correct way
body = df"""
<body>
{hello_world_block:indentation spec}
OR
{hello_world_block:indentation spec}/
OR
{hello_world_block:indentation spec}
OR
{hello_world_block:indentation spec}/
</body>
"""
Or maybe even just a few more examples in the PEP would work? IDK I can’t un-read it and it’s late