Informationally, like most metadata. It’s impossible to use it for security purposes, it’s provided by the package that might be malicious. As long as you trust it to the extent of trusting metadata provided by a package, it’s acceptable. (ie. user could accidentally omit something)
There’s no requirement that distribution package name is the same as import name, or that distribution packages don’t provide multiple top level import names, this is just standardizing a way to show this info. Any package masquerading/providing a different import name was already capable of doing so, both intentionally, non-maliciouslly, such as with packages that are fork/continuation and want to be drop in (see audioop-lts providing audioop), or maliciously. This changes nothing there, only provides a good standard for well-behaved packages to declare this in a way tools can reliably discover it.
I could imagine pip or uv responding to [tool] install sklearn[1] with
I think a malicious package like skleam would be discovered pretty rapidly. Nothing is guaranteed to be trustworthy and nobody should automatically install packages based on the metadata, but it is still useful.
they already have a deprecated package squatting on this name, but just as an example ↩︎
(not really on topic since it’s a tool UX question: I think tools and IDEs shouldn’t even suggest packages that aren’t very[1] popular - it’s very unlikely someone is going to try to import it/install it unless they saw it somewhere else without searching for it, and that normally means it is already popular)
How would we get the PyPI download statistics? The data itself is tucked away in a Google BigQuery SQL database which would require client libraries, tokens, a Google Cloud project and your credit card details to access. pypistats exists and has an API but this would presumably be quite a large workload to dump on what’s effectively someone’s pet side project.
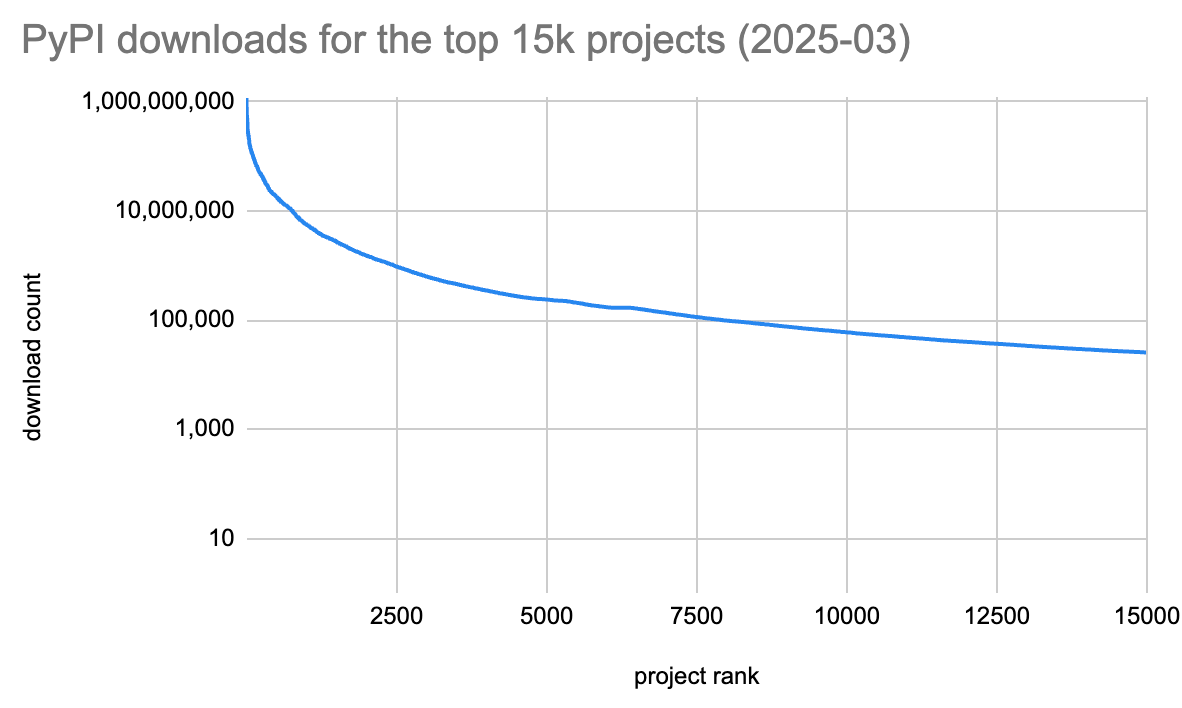
PyPI has such a long tail that functionally all you need, especially for a use-case like this, are the top N thousand projects. For this, a good resource is Hugo’s Top PyPI Packages: A monthly dump of the 15,000 most-downloaded packages from PyPI. The 15,000th project only has 25,000 downloads/month, and even at the 10,000th it’s only 60k downloads.
Replicating that example precisely would be a heavy a lift, but caching the results monthly (and restricting it to the top N packages) would still go a pretty long way. As @pf_moore said, perhaps this is an IDE feature rather than something an installer would do.
I’m not proposing a specific feature, just saying that this information could be useful and shortcircuit the standard web search/DPO post for “how do I import oddly_named_package???” It doesn’t need to be any more trustworthy than the packages themselves.
Maybe that’s not enough benefit to justify the effort here, I don’t know.
Are you talking about dependency groups? This is now standard and implemented in many tools
I wish conda implemented support for pyproject.toml and dependency groups but alas, I’m stuck with it. Indeed, I was thinking of dependency groups, which makes most of the tool I mentioned redundant, which is nice.
pip is easy to boostrap thanks to ensurepip in the stdlib, but is otherwise an external tool (from Python) as much as uv
Don’t worry, I have faith others will find a way …
Because someone has to set up that service. It’s way easier and less costly to download the metadata for every project on PyPI and parse it – which I did while developing packaging.metadata – than it is download via the HTTP range hack, find the RECORD file, and then set it up. Plus whomever decides to maintain that service has to keep it going compared to just getting the metadata directly from projects.
Considering how many times I have been privately asked about this exact list of project ↔ import name, it seems obvious to me to be just burdensome enough that no one wants to set it up and maintain it (at least for public consumption).
I’m not tied to the name, but you need more support to make me put in the effort to do a find-and-replace.
Correct, I didn’t want to go down that road, especially after the licensing discussion of project versus distribution. Plus if you look at the link to the previous discussion you will find a comment from @takluyver suggesting only build back-ends provide the metadata. That was enough for me to make the first step be the easiest for me to get a PEP accepted while still being useful.
Sure, I will update the opening post shortly.
Yes as they also take up a name.
You’re looking at the full PEP (sans a PoC and it being in reST); I don’t have more words hiding in a corner.
Sure, but that’s a bit more complicated to do if you’re avoiding downloading e.g. PyTorch, or costly if you do download every wheel out there.
Pylance from VS Code is planning to use this for the suggested use case.
For this use case, “import name” fits, since the metadata field value will match __name__ in the importable module/package being listed.
“Import path” is more for either sys.path style lists of import locations, or else resolvable references to names within modules (such as project.cli:main script entry point references)
s/full PEP/edited PEP with a Background section or expanded Motivation section/
Having index servers pull RECORD out of the uploaded artifacts with a defined mechanism for sharing that full file list should be listed as an alternative improvement that isn’t considered as being as helpful as the proposed metadata enhancement (we might decide to define a content listing API for other reasons, but it isn’t the best answer here)
Strictly speaking, they just don’t include the __init__.py in that particular package, but have dependencies on the packages that do include it. So they won’t be implicit namespace packages once installed (correctly).[1]
Another alternative would be adding a feature to the index spec (in effect, to PyPI) to expose top-level importable names in data- elements. Which I’m sure can be clearly rejected on technical reasons (size of the index probably being the biggest pain), but on the surface it looks like the same solution only easier, so it ought to get a mention.
Did we resolve the debate on whether “what the publisher claims” outweighs “what files are actually in the package”? I still lean towards the latter (even though it would hurt cases I’m [somewhat] responsible for, such as the Azure package mentioned above).
My preference here is for installers to support reference counting identical files that overwrite each other, so each of these subpackages could contain empty __init__.py files without worrying about stomping on each other or being prematurely uninstalled. But the dependency approach works today. ↩︎
In practice, it’s less fragile than letting Python do its implicit namespace search. There are other parts of the “core” libraries that need to be there anyway, so if it’s broken, it’s broken. But if you’re relying on no directory having an __init__.py, then it only takes one to break everything.
~FWIW one “correct” installation could be “one directory per package” (with sys.path adjusted accordingly) so I’d argue this is just a broken namespace package structure.~
~(We have this issue with packages when doing the packge-per-directory thing in PEX)~
I’d argue that “correct (for this package)” doesn’t include that structure.
Any more flexible structure would involve a complicated and dynamic runtime search to find the rest of the library. It’s easier to just not support scenarios that don’t actually exist right now
It is extremely important that every distribution that uses the namespace package omits the __init__.py or uses a pkgutil-style __init__.py. If any distribution does not, it will cause the namespace logic to fail and the other sub-packages will not be importable.
And we use that structure so I can confidently say that scenario does actually exist. (Our use case is build systems which use immutable cache directories per-package, which can then construct a Python env by simply having the right PYTHONPATH. I suspect tools like uv could, or maybe even have, tried something similar, but they will also likely hit this thorn)
Any more flexible structure would involve a complicated and dynamic runtime search to find the rest of the library.
I’m not sure I follow what would needed here past letting the import machinery go brr. I’m guessing there’s something beyond importing it requires?
In practise (which for us means relatively uncontrolled circumstances), we don’t want the import machinery to see a similarly named directory somewhere else on the user’s path and use that to shadow the entire library. Basically the pkgutil-style that is referenced, but that’s also pretty unreliable.
Besides, there’s a critical core component to each one of these sets, which would also be the part doing the searching. It has a __init__.py, because it’s an importable module, and the subparts are separate because they are independently versioned. So the __init__.py exists, and we assume/require that the subparts be installed into the same directory as the core part.
And despite the existence of some systems which don’t install packages into the same location, we’ve had fewer real issues with this approach compared to others.
This is getting very off topic for this post, though. Let’s leave it as “the Azure SDK is a poor example of namespace packages in this PEP”, which was my original feedback on the PEP text.