How would the iterator keep track of which items have already been yielded so that it does not yield the same item twice?
1 Like
that is part of the algorithm that would remain unchanged. there would still be a pool of numbers that are excluded.
the current algorithm creates an empty results list of size k then populates it one at a time from start to finish and i could be wrong but this seems like a perfect opportunity to drop in an iterator as a direct replacement instead of creating a list of size k full of None.
Wouldn’t scientific applications use a numeric library like PyTorch or Jax?
1 Like
well it depends i suppose but since ‘random’ exists i am hypothesising that people use it to a significant degree. whether that is on scientific or machine learning or wherever. do those libraries call into the ‘random’ module?
it seems like a no brainer.
from memory it would require:
- exact same algorithm
- remove the results list initialisation
- change the recursive call to a ‘yield from’ (edit: also there is a list comprehension that will need to be altered to be an iterator)
- change each of two for loops to yield the value instead of assigning to the list.
- remove the return statement returning the list
supposing this is correct and is done as an ‘isample’ method, the ‘sample’ method could just return list(isample()).
edit: in the case of shuffle which could hypothetically be done with isample(pop, k=len(pop)), modelling a deck of cards would make more sense as an analogy because only one card would be revealed at a time. seems like an iterator makes more sense over all.
i ran sample versus isample with n=10e18 and k ranging from 1 to 2e24 and these were the timing results (at bottom are the average latencies to get the first item across all values of n and k).
PS C:\Users\kevin\source\code> python .\sample.py
n = 1000000000000000000, k = 1
n = 1000000000000000000, k = 2
n = 1000000000000000000, k = 4
n = 1000000000000000000, k = 8
n = 1000000000000000000, k = 16
n = 1000000000000000000, k = 32
n = 1000000000000000000, k = 64
n = 1000000000000000000, k = 128
n = 1000000000000000000, k = 256
n = 1000000000000000000, k = 512
n = 1000000000000000000, k = 1024
n = 1000000000000000000, k = 2048
n = 1000000000000000000, k = 4096
n = 1000000000000000000, k = 8192
n = 1000000000000000000, k = 16384
n = 1000000000000000000, k = 32768
n = 1000000000000000000, k = 65536
n = 1000000000000000000, k = 131072
n = 1000000000000000000, k = 262144
n = 1000000000000000000, k = 524288
n = 1000000000000000000, k = 1048576
n = 1000000000000000000, k = 2097152
n = 1000000000000000000, k = 4194304
n = 1000000000000000000, k = 8388608
n = 1000000000000000000, k = 16777216
avg sample time: 0.7411836338043213
avg isample time: 2.3326873779296876e-05
the way the pool works, it is dependent on both n and k whether it runs out of memory.
with n=10e18, the program isample crashes on my machine with k=2e57. this is because list(population) is called in the algorithm (conditional on n and k), so changing to an iterator would not fix that.
i can’t test sample using the same parameters (viz. n=10e18, k=2e57) because it is too slow.
I don’t think so since their fast path is Jitted.
1 Like
i have found in the source of PyTorch and Jax that they use their own.
interestingly, when looking in numpy, they have a note to use a “generator” version of sampling.
looking into it though, it appears it fills the array entirely. i am not smart enough to figure out what is going on with the numpy code. link below if you’re interested:
so it seems like Python’s random is not being used as widely as i hoped.
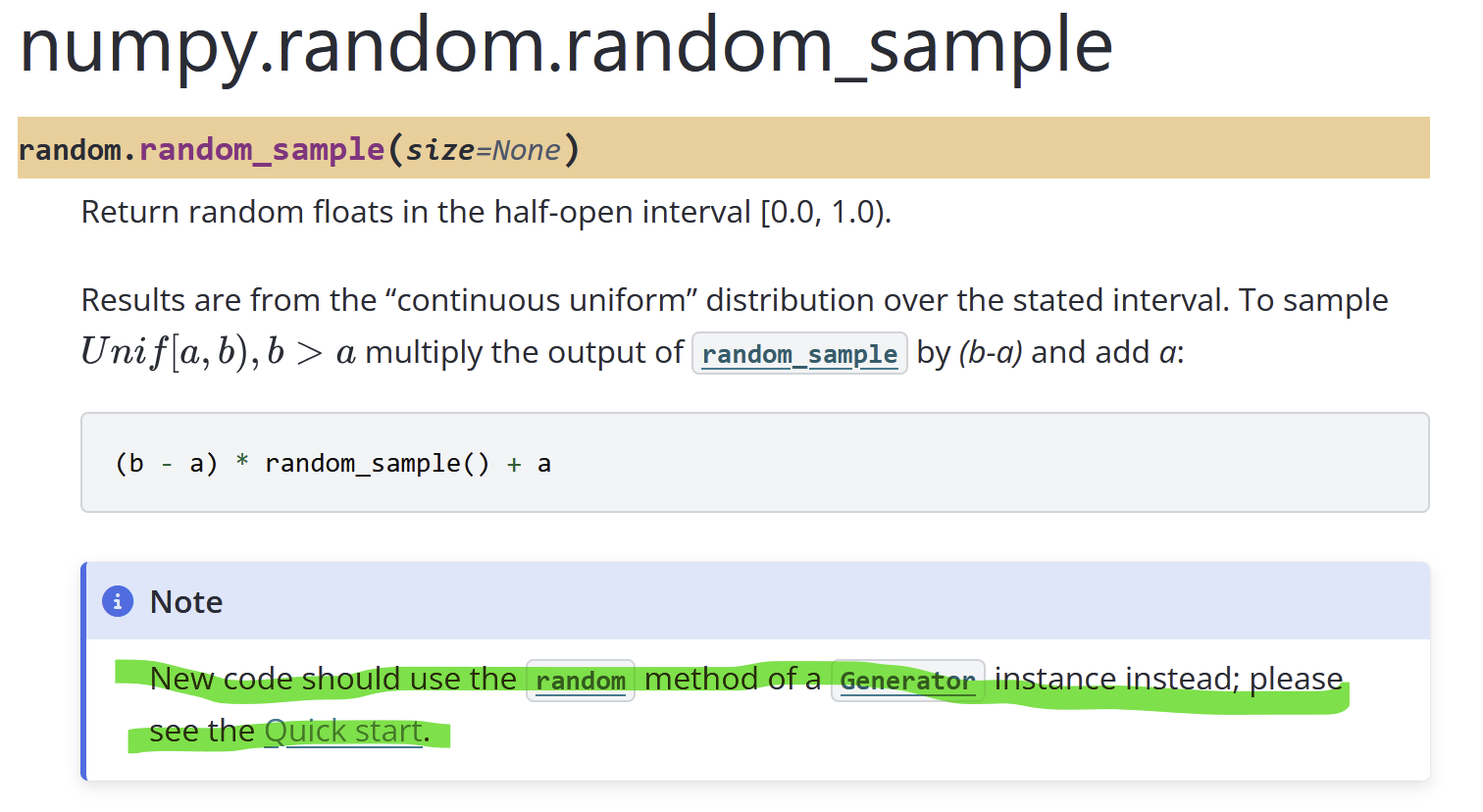
They’re not referring to Python generators there, but to numpy’s collection of different underlying random number generators. CPython’s only build on the Mersenne Twister, or os.urandom, numpy supports several others, some better suited for parallel processing. It’s involved.
It’s not really surprising that they “fill the array entirely”. Taking a sample is already reducing (sometimes vastly) the original data size, and they want to compute on the sample. Mean, variance, to drive another function, whatever.
You’re keen on “latency” (by which I assume you mean the time elapsed before the first of the random representatives is made available to the caller), but nobody else here seems to care about that.
People do, however, care about the total time to get the entire sample. That’s generally (not always) minimized by not using generators (in the Python sense) at all. Each yield costs machine cycles too.
i am going to make the modifications as a personal project to put on pypi for the learning experience.
the timing i did is the same whether one calls list(isample()) or sample() (viz. a difference of +0.05% for isample on average over 30 calls with n=10e18 and k=2e20), so there is no apparent downside in total latency (or bandwidth), only upside in the initial latency.
all items as list:
avg sample time: 0.5721232970555623
avg isample time: 0.5724258899688721
first item:
avg sample time: 0.5189786911010742
avg isample time: 3.3688545227050784e-05
I can see a situation where an iterator would be beneficial here (and I’m sure you can too). It just hasn’t been mentioned and I was waiting for @boniest to say it.
There are two potential advantages to having an iterator rather than generating all values up front and returning a list:
- You can avoid needing to store all of the yielded values simultaneously in memory.
- You might not want to consume the whole iterator and maybe you could avoid generating all of the values.
My comment above about remembering which values were previously yielded shows that the first case does not apply at least for the proposed implementation. The second case can apply:
for item in sample(population, k):
if some_func(item):
break
It is the break here that makes an iterator potentially useful. Generating all values up front might have generated more than were needed by the consumer iterating over the values.
I don’t think I’ve ever used sample so it probably does not mean much for me to say that I have never needed an iterator version of it. Having now seen the code that implements sample though I don’t think it is doing anything special that I would not get from implementing my own iterator version if needed and the use case for an iterator seems niche.
The random module provides good implementations of some important primitives that would otherwise be hard to implement. The sample function does not fall into the primitive category and neither do variations on it like an iterator version.
1 Like
thanks for pointing this out. i was working under the assumption that it was clear from the conversation thus far that both the space taken up by the list and the time taken to populate the list would be saved with an iterator.
What would be remembered isn’t the values but their indices. And the values can take a lot more memory.
Consider sample(range(2**1000000, 2**1000000 + 1000), k).
here is the github repo for irandom where both isample and ichoices returns iterators.
(i think i maybe could do an iterator for shuffle but can’t be bothered at the moment.)
(i am working on publishing to PyPI but the process is way more complicated than i anticipated.)
i ended up doing the following:
- added
ichoiceswhich returns an iterator. - made
choicesto callichoices. - retained Python’s
choicesasold_choices. - added
isamplewhich returns an iterator. - made
samplesto callisamples. - retained Python’s
samplesasold_samples. - added
ishufflewhich returns an iterator and modifies a list in place. - made
shuffleto callishuffle(and discard the iterator). - retained Python’s
shuffleasold_shuffle.
i will be honest. i would be unsurprised to learn some finance applications are pulling random samples and iterating over them (doing some work on each in turn), and that latency is of the essence. i can’t be sure but this exact use case sounds like something that might happen a lot in high-frequency trading. just seems like it.
Publishing to PyPI and then getting people using it is the best way to push the ecosystem forward and perhaps even get a change to the standard library. Changing the standard library is not easy and only done with great care. Your idea can live in PyPI and be useful to the people who want it.
3 Likes
i won’t be marketing it at all, because it isn’t worth my time.
i’ll put it up there for the experience and then move on to the next thing.
the lesson i am getting here is to just do it then post the pypi link on this forum and see what happens.
I think you have taken the right lesson: new ideas are best worked out first on PyPI. Usually, that is the right place for them in the long run.
When you started this post, I thought you were aiming to change the standard library. This seems like a good outcome. You may not get people using your code, but you’ve learned things along the way.
5 Likes