GitHub does indeed have this this feature, and I’ve found it extremely useful over the years when making, reviewing and suggesting changes on documentation, website and other prose-related content. Unfortunately, as you might expect, it doesn’t go so far as to parse and dynamically reflow reST content in order, so the reflows resulting from arbitrarily hard-wrapping text makes it almost useless for such documents, whereas it is far more useful with content with OSPL and moderately useful with SemBr (though it essentially equalizes what would otherwise be SemBr’s nominal advantage over OSPL in terms of diff granularity).
I usually try to do this, but unfortunately it requires digging into the commit history when reviewing, which also means that GitHub’s suggestion feature, which I make extensive use of in PEP, docs, etc. PRs, doesn’t work at all. It also doesn’t solve the increased likelihood of merge conflicts, the final squashed commit diff is still equally noisy, and it still means one needs to do the work of reflowing at some point.
From now I am starting to always split a line between sentences in a new text. For example:
``*+``, ``++``, ``?+``
Like the ``'*'``, ``'+'``, and ``'?'`` quantifiers, those where ``'+'`` is
appended also match as many times as possible.
However, unlike the true greedy quantifiers, these do not allow
back-tracking when the expression following it fails to match.
These are known as :dfn:`possessive` quantifiers.
For example, ``a*a`` will match ``'aaaa'`` because the ``a*`` will match
all 4 ``'a'``s, but, when the final ``'a'`` is encountered, the
expression is backtracked so that in the end the ``a*`` ends up matching
3 ``'a'``s total, and the fourth ``'a'`` is matched by the final ``'a'``.
However, when ``a*+a`` is used to match ``'aaaa'``, the ``a*+`` will
match all 4 ``'a'``, but when the final ``'a'`` fails to find any more
characters to match, the expression cannot be backtracked and will thus
fail to match.
``x*+``, ``x++`` and ``x?+`` are equivalent to ``(?>x*)``, ``(?>x+)``
and ``(?>x?)`` correspondigly.
It will save souls of future editors and reviewers.
I think that’ll certainly help, but I also think there are good arguments to be made for breaking it up more semantically. For example (with annotations):
``*+``, ``++``, ``?+`` # (1)
Like the ``'*'``, ``'+'``, and ``'?'`` quantifiers, # (1)
those where ``'+'`` is appended also match as many times as possible.
However, unlike the true greedy quantifiers,
these do not allow back-tracking
when the expression following it fails to match.
These are known as :dfn:`possessive` quantifiers.
For example, ``a*a`` will match ``'aaaa'``
because the ``a*`` will match all 4 ``'a'``s, # (2)
but, when the final ``'a'`` is encountered,
the expression is backtracked so that in the end
the ``a*`` ends up matching 3 ``'a'``s total, # (3)
and the fourth ``'a'`` is matched by the final ``'a'``.
However, when ``a*+a`` is used to match ``'aaaa'``,
the ``a*+`` will match all 4 ``'a'``, # (4)
but when the final ``'a'`` fails to find any more characters to match,
the expression cannot be backtracked and will thus fail to match.
``x*+``, ``x++`` and ``x?+`` are equivalent to # (5)
``(?>x*)``, ``(?>x+)`` and ``(?>x?)`` correspondigly.
My reasoning:
Though I concede it’s not very likely, in the grand scheme of things, one of the possible changes that would force an edit to this text is the addition of a fourth form of +-expression to go with the existing three. If such an addition were made, the fact that there’s room to add it in without having to reflow either of the first two lines is a nice-to-have.
Having the fourth sentence (starts with “For example…”) broken up semantically calls attention to the fact that it’s, TBH, way too long.
Way, waaaay too long. It’s still going here, five lines from where it started, and the entire thing spans six lines. Because of that length, it’s a bit hard to follow, as you can easily get lost along the way from start to finish.
The semantic divisions help with that significantly. So they both call attention to the fact that it’s overlong, and help prevent that length from confusing the reader.
By the same token, IMHO the semantic breaks make it far easier to spot that the end of this line is missing a plural; it should read
all 4 ``'a'``s,
The same way the line at annotation (2) does. That’s glaringly obvious in the semantically-divided version, more so (at least to me) than in the original. So, the semantic breaks help with proofreading and copyediting.
The way this text is written, the three expression forms are always together at the start of a sentence statement, whether or not it’s the beginning of a sentence. In the semantic layout, they’re similarly always on the same line, and always at the start of the line. That holds in all four locations where they appear together. (First line, second line, and last two lines.)
In the original, the final group of three is broken across two lines by the line wrapping. Having them always together and always aligned to the left of the text makes it far easier to keep track of what exactly is being documented here, both in the text’s current form and certainly (circling back to point 1) if it ever had to be expanded.
Lines should usually not extend past column 79, excepting URLs and similar circumstances. Tab characters must never appear in the document at all.
PEP authors are free to use semantic line breaks, or use Emacs to reflow paragraphs, or do anything else – except use long lines (so text stays readable both with and without line wrapping).
I’m late to the game here, but I want to emphasize Ethan’s point. The original attraction of markup systems like reST and Markdown (maybe their raison d’être) was that the text with its light markup was readable as-is. As opposed to, say, LaTeX.
My recommendation is that instead of adopting a somewhat meaningless convention just to make diffs more readable on GitHub, that you separate content changes from formatting changes. If you need to add/delete/change some text, do it without reflowing the paragraph. After awhile, if the paragraph (or document as a whole) gets tough to read, then make an edit which is notion more than reformatting — no content changes. This is no different than the admonition to separate semantic and formatting changes in the C or Python source code.
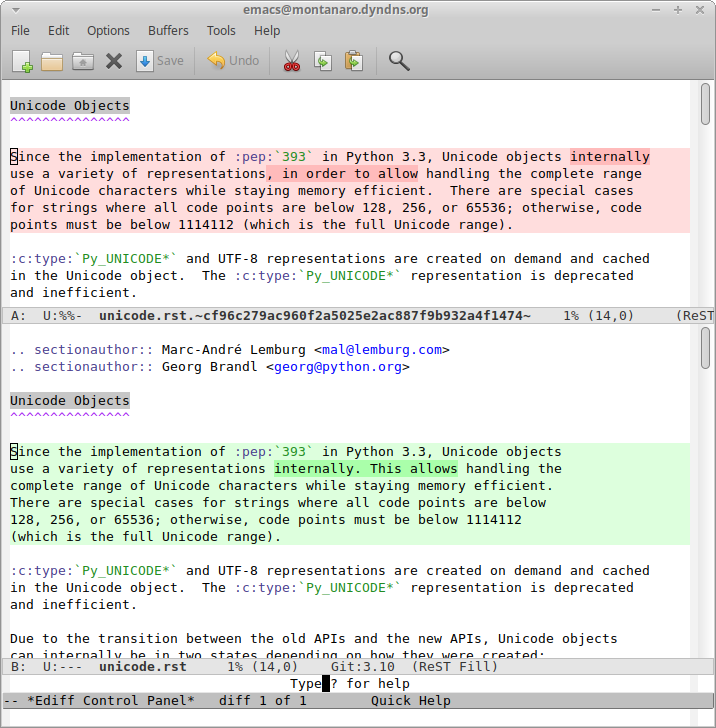
It also helps to have tools which do a better job presenting you with the actual changes. I happen to (lo, these many years) still be an Emacs user. It’s ediff system presents changes cleanly, identifying both the formatting bits (light green or red text background) and the content bits (somewhat darker green or red background). Here’s a simple edit of the C API’s unicode.rst file which demonstrates both.
I don’t normally use GitHub to compare differences between two versions of a file. Does it not do something meaningful like this? What other tools do people use to edit text that make it difficult to distinguish between semantic and formatting changes?
In the end, I hope it becomes a “to each their own” sort of thing. I wouldn’t want to see any particular editing style mandated.
I kinda hate to admit it, because I have been using semantic line breaks for years, but I recently started switching to single-line paragraphs, and it has made my life easier. Sure, sometimes diff tools do not help and show that the whole line changed, without emphasizing the only word within the line that actually changed. But at least I don’t spend my energy manually reflowing sentences everytime I modify a paragraph. If semantic line breaks were automatable without consuming tons of energy (LLM → GPU), that would be another story. But I don’t believe they are, or at least I’m not aware of any tool that breaks paragraph semantically (even just for the English language).