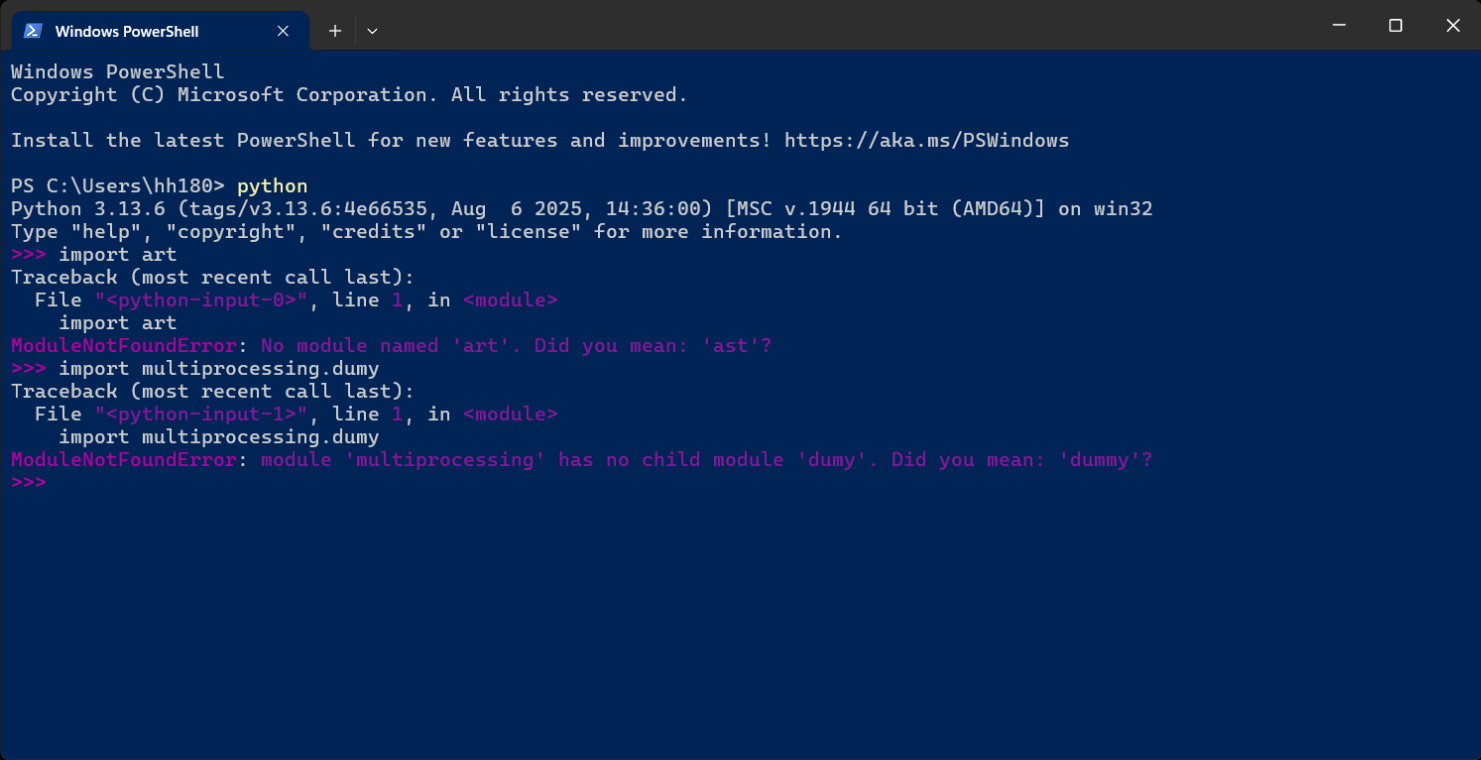
My idea that suggest to make suggestions in ModuleNotFoundError was reject that no way to get all of the modules. Then I wrote the code to make it below. However, I can only test it on Windows system. How will it behave on the other system? And how to initlizate the builtins_modules?
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#ifdef _WIN32
#include <windows.h>
#else
#include <dirent.h>
#endif
#include <sys/stat.h>
// gcc list_modules.c -DPYTHON_STD_PATH=\"/usr/lib/python3.11\" -o list_modules
// gcc list_modules.c -DPY_EXT_PREFIX=\"cpython-311-x86_64-linux-gnu\" -o list_modules
#define PY_EXT_PY ".py"
#ifdef _WIN32
#define PY_EXT_PYD ".pyd"
#else
#define PY_EXT_SO ".so"
#endif
// ===== builtins functions =====
const char* builtin_modules[] = {
"_abc", "_ast", "_bisect", "_blake2", "_codecs", "_codecs_cn",
"_codecs_hk", "_codecs_iso2022", "_codecs_jp", "_codecs_kr",
"_codecs_tw", "_collections", "_contextvars", "_csv", "_datetime",
"_functools", "_heapq", "_imp", "_interpchannels", "_interpqueues",
"_interpreters", "_io", "_json", "_locale", "_lsprof", "_md5",
"_multibytecodec", "_opcode", "_operator", "_pickle", "_random",
"_sha1", "_sha2", "_sha3", "_signal", "_sre", "_stat", "_statistics",
"_string", "_struct", "_suggestions", "_symtable", "_sysconfig", "_thread",
"_tokenize", "_tracemalloc", "_typing", "_warnings", "_weakref", "_winapi",
"array", "atexit", "binascii", "builtins", "cmath", "errno", "faulthandler",
"gc", "itertools", "marshal", "math", "mmap", "msvcrt", "nt", "sys", "time",
"winreg", "xxsubtype", "zlib",
NULL
};
int has_suffix(const char *name, const char *suffix) {
size_t len1 = strlen(name);
size_t len2 = strlen(suffix);
return len1 > len2 && strcmp(name + len1 - len2, suffix) == 0;
}
#ifdef PY_EXT_PREFIX
int match_ext_prefix(const char* filename) {
return strstr(filename, PY_EXT_PREFIX) != NULL;
}
#endif
// manager the modules list
typedef struct {
char **names;
size_t count;
size_t capacity;
} ModuleList;
ModuleList* create_module_list() {
ModuleList *list = malloc(sizeof(ModuleList));
if (!list) return NULL;
list->capacity = 32;
list->count = 0;
list->names = malloc(list->capacity * sizeof(char*));
if (!list->names) {
free(list);
return NULL;
}
return list;
}
void free_module_list(ModuleList *list) {
if (!list) return;
for (size_t i = 0; i < list->count; i++) {
free(list->names[i]);
}
free(list->names);
free(list);
}
int add_module_to_list(ModuleList *list, const char *name) {
if (!list || !name) return 0;
// Check if module already exists
for (size_t i = 0; i < list->count; i++) {
if (strcmp(list->names[i], name) == 0) {
return 1; // Already exists
}
}
// Check if we need to expand the array
if (list->count >= list->capacity) {
size_t new_capacity = list->capacity * 2;
char **new_names = realloc(list->names, new_capacity * sizeof(char*));
if (!new_names) return 0;
list->names = new_names;
list->capacity = new_capacity;
}
// Add the new module name (make a copy)
char *name_copy = strdup(name);
if (!name_copy) return 0;
list->names[list->count++] = name_copy;
return 1;
}
void print_module_list(const ModuleList *list) {
if (!list) return;
for (size_t i = 0; i < list->count; i++) {
printf("%s\n", list->names[i]);
}
}
void add_module_name(const char* filename, ModuleList *list) {
if (!add_module_to_list(list, filename)) {
fprintf(stderr, "Failed to add module: %s\n", filename);
}
}
void scan_dir(const char* path, ModuleList *list) {
#ifdef _WIN32
WIN32_FIND_DATA findFileData;
HANDLE hFind;
char searchPath[MAX_PATH];
snprintf(searchPath, sizeof(searchPath), "%s\\*", path);
hFind = FindFirstFile(searchPath, &findFileData);
if (hFind == INVALID_HANDLE_VALUE) return;
do {
if (strcmp(findFileData.cFileName, ".") == 0 ||
strcmp(findFileData.cFileName, "..") == 0) continue;
char fullpath[MAX_PATH];
snprintf(fullpath, sizeof(fullpath), "%s\\%s", path, findFileData.cFileName);
if (findFileData.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) {
char initfile[MAX_PATH];
snprintf(initfile, sizeof(initfile), "%s\\__init__.py", fullpath);
WIN32_FILE_ATTRIBUTE_DATA fileData;
if (GetFileAttributesEx(initfile, GetFileExInfoStandard, &fileData)) {
add_module_name(findFileData.cFileName, list);
}
} else {
if (has_suffix(findFileData.cFileName, PY_EXT_PY)) {
size_t len = strlen(findFileData.cFileName) - strlen(PY_EXT_PY);
char modname[256];
strncpy(modname, findFileData.cFileName, len);
modname[len] = '\0';
add_module_name(modname, list);
}
#ifdef PY_EXT_PREFIX
else if (has_suffix(findFileData.cFileName, PY_EXT_PYD) && match_ext_prefix(findFileData.cFileName)) {
size_t len = strlen(findFileData.cFileName) - strlen(PY_EXT_PYD);
char modname[256];
strncpy(modname, findFileData.cFileName, len);
modname[len] = '\0';
add_module_name(modname, list);
}
#endif
}
} while (FindNextFile(hFind, &findFileData));
FindClose(hFind);
#else
DIR *dir = opendir(path);
if (!dir) return;
struct dirent *entry;
while ((entry = readdir(dir)) != NULL) {
if (entry->d_name[0] == '.') continue;
char fullpath[1024];
snprintf(fullpath, sizeof(fullpath), "%s/%s", path, entry->d_name);
struct stat st;
if (stat(fullpath, &st) == -1) continue;
if (S_ISREG(st.st_mode)) {
// .py
if (has_suffix(entry->d_name, PY_EXT_PY)) {
size_t len = strlen(entry->d_name) - strlen(PY_EXT_PY);
char modname[256];
strncpy(modname, entry->d_name, len);
modname[len] = '\0';
add_module_name(modname, list);
}
#ifdef PY_EXT_PREFIX
#ifdef _WIN32
else if (has_suffix(entry->d_name, PY_EXT_PYD) && match_ext_prefix(entry->d_name)) {
size_t len = strlen(entry->d_name) - strlen(PY_EXT_PYD);
char modname[256];
strncpy(modname, entry->d_name, len);
modname[len] = '\0';
add_module_name(modname, list);
}
#else
else if (has_suffix(entry->d_name, PY_EXT_SO) && match_ext_prefix(entry->d_name)) {
const char* dot = strchr(entry->d_name, '.');
if (dot) {
size_t len = dot - entry->d_name;
char modname[256];
strncpy(modname, entry->d_name, len);
modname[len] = '\0';
add_module_name(modname, list);
}
}
#endif
#endif
} else if (S_ISDIR(st.st_mode)) {
char initfile[1024];
snprintf(initfile, sizeof(initfile), "%s/__init__.py", fullpath);
if (stat(initfile, &st) == 0) {
add_module_name(entry->d_name, list);
}
}
}
closedir(dir);
#endif
}
ModuleList* find_all_packages() {
ModuleList *list = create_module_list();
if (!list) return NULL;
// 1. First scan current directory
char current_dir[1024];
if (getcwd(current_dir, sizeof(current_dir))) {
scan_dir(current_dir, list);
}
// 2. Add builtin modules
for (int i = 0; builtin_modules[i] != NULL; i++) {
if (!add_module_to_list(list, builtin_modules[i])) {
fprintf(stderr, "Failed to add builtin module: %s\n", builtin_modules[i]);
}
}
// 3. Scan standard library path
#ifdef PYTHON_STD_PATH
scan_dir(PYTHON_STD_PATH, list);
#endif
// 4. Scan site-packages for third-party modules
#ifdef PYTHON_SITE_PATH
scan_dir(PYTHON_SITE_PATH, list);
#endif
return list;
}
int main() {
ModuleList *modules = find_all_packages();
if (!modules) {
fprintf(stderr, "Failed to create module list\n");
return 1;
}
printf("Found %zu Python modules/packages:\n", modules->count);
print_module_list(modules);
free_module_list(modules);
return 0;
}