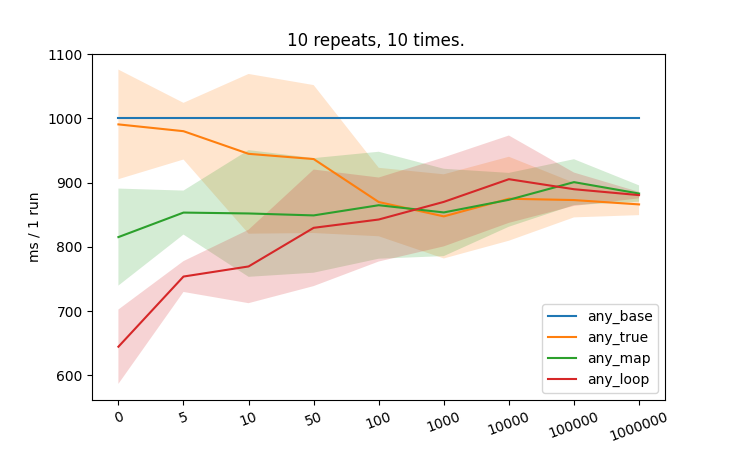
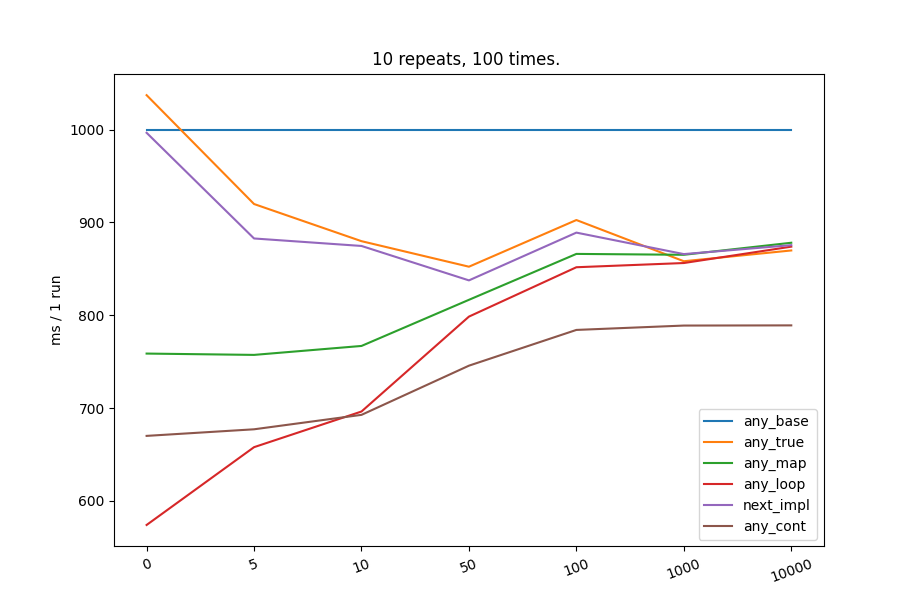
This is not an idea. I would just like to share some information and a graph. And find out what others think.
The reason why I chose to spend more time on this is that this is one of very few cases that I have seen where loop ends up to be the most performant solution.
I have done some comparisons of different approaches to use any on sequence which needs to be mapped with operation.
I was looking at ChainMap.__contains__ performance and I think it is a good example case where performance of any function for short sequences is important.
Tested functions:
def any_base(maps, key):
return any(key in el for el in maps)
def any_true(maps, key):
return any(True for el in maps if key in el)
def any_map(maps, key):
return any(map(contains, maps, repeat(key)))
def any_loop(maps, key):
for m in maps:
if key in m:
return True
return False
Benchmark numbers are relative to the base case. (Disregard time units)
Interesting fact. For 1M size any_true is most performant although it is almost as bad as the base case for small sizes.
So it is just a bit of food for thought. Is it possible to improve performance of any above solutions in C? Do they need to be improved at all? Is it possible to beat simple loop for small-size problems?
Added one more data point with 1M elements. Fewer repetitions, so not as accurate as the one above. It seems that any_true performs best for large sequences.
For the problem on stack any(el > 0 for el in iterable)any_true outperforms others for 100K, but is in line with others for 1M. So results are not conclusive for large sizes.
You call any() with different arguments. It is not surprising that it has different performance (and may have different result) for different input. The difference lies outside of any().
Of course, you can make any() detecting that the argument is an instance of GeneratorType, analyzing the bytecode of the corresponding generator function and creating a modified generator function and object. It will improve the performance by few percents for large input in this particular case. But it will make it slower in all other cases, not counting the maintenance cost and the risk of affecting other parts of the interpreter.
I recognise that. I am not emphasising any, but looking at possible ways to come up with more performant solution to the indicated problem (regardless whether it has anything to do with implementation of any or not).
Would it be possible to get performance of a loop if joint function was made out of map and any. With a signature of map but implicitly doing any?:
def any_map(func, *args):
Or alternatively, maybe using any(map()) is fine with more performant predicates?
e.g.:
a = [0] * 10 + [1]
%timeit any(map(bool, a)) # 279 ns
%timeit any(map(opr.gt, a, itl.repeat(0))) # 505 ns
Maybe there exists a way of pre-compiling gt_0=lambda x: x > 0 that would bring performance closer to the any(map(bool?
any and all are builtin function names, I don’t think there is a chance that they become keywords.
Personally, I don’t have issues with syntax of any of the above (except the loop ), more concerned with finding a way to improve performance of what exists.
Ohhhh right, “at each step” was the clue, there’s only ever one unnecessary comparison anyway so barely anything to save. Is it any significant win at the few-entries end of the scale where that cost isn’t amortised?
This feels more like it’s to do with the performance characteristics of ChainMap (which I imagine isn’t optimised for this use case). Do other containers show similar results?
Yes, it is very specific to ChainMap. But I am just using this example to look into performance of “predicated short-circuiting”.
It is not the first time I am replacing any with for loop. This becomes highly preferable for sequences of small sizes (up to 50 elements).
Just to give another example. Graph building. There is a node, which contains other nodes of different types. It is often needed to check if all sub-nodes are of the same type.
class Node:
def __init__(self, func, args):
self.func = func
self.args = args
...
if all(isinstance(a, Atom) for a in node.args):
#do something simple
....
Same as in case of a ChainMap, it has significant impact when such operation is done many times. Every time __contains__ is called in case of ChainMap and recursive operations on graphs in above example.
One thing I can think of: 2 steps that could improve performance of any_map solution, which I quite like as it does fairly ok for any size now:
Implement more efficient map with only 1 argument. So that there is less construction overhead.
Implement partial in C. Also argument skipping would be needed. I have implemented EMPTY placeholders for partial in python already - useful feature, which I got from partial · PyPI and some other package. From my experience EMPTY placeholder is much more useful than Ellipsis of partiell package.
Result:
pred = c_partial(opr.contains, EMPTY, key)
any(one_arg_map(pred, maps)
I don’t believe that. Doesn’t make sense. And I can’t reproduce it:
41.8 ms any(el > 0 for el in iterable)
18.7 ms any(True for el in iterable if el > 0)
40.4 ms any(el > 0 for el in iterable)
19.9 ms any(True for el in iterable if el > 0)
40.5 ms any(el > 0 for el in iterable)
24.4 ms any(True for el in iterable if el > 0)
from timeit import repeat
setup = 'iterable = [0] * 1_000_000 + [1]'
for code in [
'any(el > 0 for el in iterable)',
'any(True for el in iterable if el > 0)'
] * 3:
t = min(repeat(code, setup, number=1, repeat=25))
print(f'{t*1e3:4.1f} ms ', code)
Apologies for confusion, by “others” I meant all other solutions except base case - any(el > 0 for el in iterable), which I already assumed to be by far the worst for any size.
Anything is technically possible, but I don’t think this is likely to get accepted. At an absolute minimum you would need to:
Define the semantics much more precisely. At the moment all you have is a vague example. Imagine you were going to implement this and write the spec for what it would do and how it would work.
Research the history. There have been many discussions in the past about extending generator expressions and for loops. Read those, and understand why the various proposals didn’t get accepted. Work out why your proposal is different, and what about it addresses the problems that caused previous proposals to fail.
Find real world examples where your proposal would offer genuine benefits. Remember that the original post in this thread was explicitly presented as some interesting performance results, and not as an actual problem needing a solution.
Even if you do all of this (and it’s a lot of work - expect to spend days working on it before you have anything worth posting) the likelihood is that you’ll get very little enthusiasm for the idea, and it will ultimately not get accepted (especially if you are not able or willing to implement it yourself, which would involve getting familiar with the interpreter code). If that’s not something you are OK with, my advice is to drop the idea.
Also, remember that anyone who reads your proposal and comments on it is spending their free time on it. It’s not just your time that gets spent on a proposal.
Personally, I think you should drop the idea. The OP’s results sound more like an interesting exercise in optimising Python code, and not something that demands a new language feature.
Your graphs show a difference of about 10% between the worst and best variants. You can get rid of some overhead of Python interpretator by rewriting your code in C. It is boring and error prone (in your other example you forgot that PySequence_Contains() can fail), so it is better to use some Python compiler, like Cython or Nuitka.
But there’s no way a 10% increase is enough to add a new highly specialized built-in function to Python.
Yeah, I know, I saw that operator.contains has some overhead to address this.
That is for the large size iterables.
For iterable of size 1, max - min = 40%, size 10: 30%, size 50: 25% to base. And this is pretty much the area I am addressing.
Yeah, I am not offering to introduce specialized version for this. I have only checked its performance to see the theoretical lower bound.