Sooo, I’m not sure what’s going on but when i try to download a png ( or jpg, jpeg ) using this code.
import requests as req
import progressbar
from tqdm import tqdm
import time
from colorama import Fore, Style
import os
os.chdir('/Users/REMOVED/Downloads/') # file path
#url = "https://easyupload.io/lnqzpz"
#with open("NaturePictures.py", "w+b") as f:
# f.write(req.get(url).content)
Welcome_hub_question = input(f"""{Fore.BLUE} Welcome to picture/backround downloader, Please type 1, 2, 3 to select which you want to download
1 = Nature photos
2 = Dog photos
3 = Cat photos""")
if Welcome_hub_question == "1":
nature_question = input(" you like to download nature pictures? (yes, no)").lower()
if nature_question == "yes":
url_nature = "https://www.file.io/4i8g/download/jyNXAd3h12af"
with open("cat.jpg", "w+b") as f:
f.write(req.get(url_nature).content)
It won’t let me open the .jpg or .png file ( i tried both )
But when i go to the site directly to download the picture it works fine.
( yes i know i mixed up the cat picture with the nature picture downloading area but that’s besides the point. ( I’ll fix it after this.) ( Also ik i have a lot of module imports but that’s for code that isnt written yet )
What do the first few bytes of the file look like? JPEG and PNG files are easy to identify by their magic bytes. It could be that the file is an image in a different format (e.g. WebP or GIF), or not an image file altogether (e.g. an error page or an empty file). Did you check the return code from the request and make sure it was OK?
I found this code online that works perfectly fine, If you could read through this and tell me what this has that mine doesn’t? ( Note this downloads 21 “pet dog” photos"
import requests
from bs4 import BeautifulSoup
url = 'https://www.google.com/search?q=pet+dog&sxsrf=AJOqlzXsj8W5ThdduaqH3d4fYia4MkBe2A:1677900492082&source=lnms&tbm=isch&sa=X&ved=2ahUKEwjY6rG2qsH9AhVu8DgGHcUrDnQQ_AUoAnoECAEQBA&biw=1536&bih=796&dpr=1.25'
html = requests.get(url)
content = html.text
parse = BeautifulSoup(content,'html.parser')
img = parse.find_all('img')
def download_images(images):
count = 0
print(f"Total {len(images)} Image Found!")
if len(images) != 0:
for i, image in enumerate(images):
try:
image_link = image["data-srcset"]
except:
try:
image_link = image["data-src"]
except:
try:
image_link = image["data-fallback-src"]
except:
try:
image_link = image["src"]
except:
pass
try:
r = requests.get(image_link).content
try:
r = str(r, 'utf-8')
except UnicodeDecodeError:
with open(f"images{i+1}.jpg", "wb+") as f:
f.write(r)
count += 1
except:
pass
download_images(img)
I’m really new to python, I mean like really new so I wouldn’t even know where to check to find the return code. If you mean in the terminal then nothing happens, Code just ends, No errors or anything.
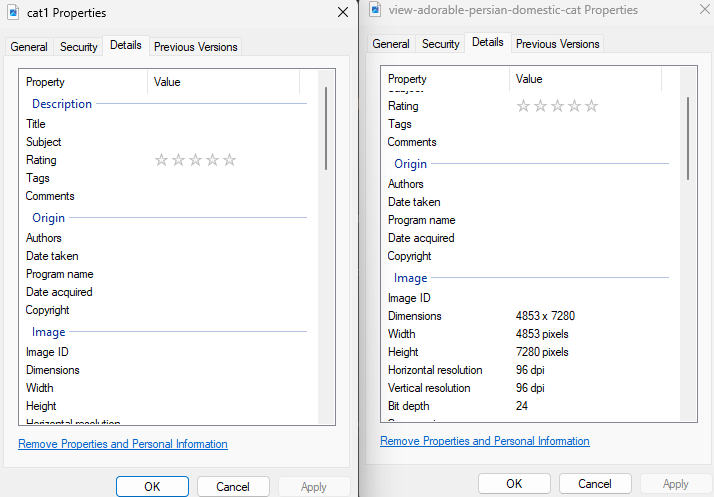
Left photo is the picture downloaded from the python file, Right picture is the one downloaded directly from the website. Surely this is something?
( left photo has no info under “image”, no width, height bit depth, etc. Which would imply this indeed isn’t downloading an image but rather downloading a blank .jpg file? )
You can check the documentation for requests for how to check the return code. As it happens, the first example on the welcome page shows you how to check it:
It’s progress. It means the server sent you what it thinks you asked for. But what you asked for may not be what you wanted.
Can you show us the first few bytes of the file? You can do that in your code with something like print(r.content[:20]) where r is the response object returned by requests.get, or by reading the file you saved with something like
with open("cat.jpg", "rb") as fd:
print(fd.read()[:20])
Looks like you downloaded an HTML document (a web page). Presumably one that contains an image tag somewhere. If you want to download that image with Python, you can try one of the following approaches.
Manually search the HTML for an img tag (either by opening the file you downloaded in a text editor of your choice, or by visiting the URL with a browser and pressing F12 to bring up the DOM inspector). Find the URL of the image, and use that instead of the current web page URL.
Use Python to parse the HTML document using an HTML parser like beautifulsoup, extract all the img tags, and make a new request for each image URL. This is what the script in your second post is doing.
Well well well, Looks like I’ve figured it out.
I tried using a different website and copying the link of the image it self ( which i tried doing on the other website and it didn’t work )
and with this new website it works!
Though I am going to try what you showed me so I can learn.
One thing though, Is there anyway I increase the resolution of the image? Maybe pass it through a resolution increaser ( if that’s even a thing…?? ) before it downloads?
Yes and no. You can’t create information that isn’t there to begin with. The best you can do is make guesses as to what the missing pixels would have looked like if they existed