Below i am trying to mention my requirement.
In the below screenshot, the yellow columns are the columns which i have to create dynamically based on response in other columns.
Q1_SL is corresponding to Q1_1, Q1_2, and Q1_3.
Q1_SL should be set as 1 only in case all the three columns have same response else will be set as 0.
What do you mean by “a column”? When you show us this data, what actually is it? Do you have a CSV file? A spreadsheet in a proprietary format such as .xlsx? An SQL database? Something else?
Aside from that, what actual help do you need? What do you imagine are the logical steps involved in solving the problem, and where do you get stuck when you try to write the code?
This data is a survey data present in CSV file. Data does not include the columns which are highlighted in yellow in my screenshot and actually we need to add those columns in data frame from our side.
If data at all the columns corresponding to Q1 will be same then Q1_SL value should be set as 1 else it will be set as 1.
i am thinking of merging the three Q1 columns with values merged with “;” as delimiter.
As a second step i can check these values, if they are having all the values same after split, if yes then will set Q1_SL as 1 else 0.
Same treatment i can apply on Q2 as well later on.
But for now i m struggling to dynamically merge Q1_1 to Q1_3 and Q2_1 - Q2_2.
Thanks for showing interest in my query and just wanted to inform you that i am a novice in Python right now.
I am able to read the data and store the data.
In my dataset there are columns corresponding to Q9/Q10/Q11/Q12/Q13/Q14, and corresponding to each question I need to create a separate column and set it’s value for each row either as 1 or 0 depending upon if all the answers are same for a question or not.
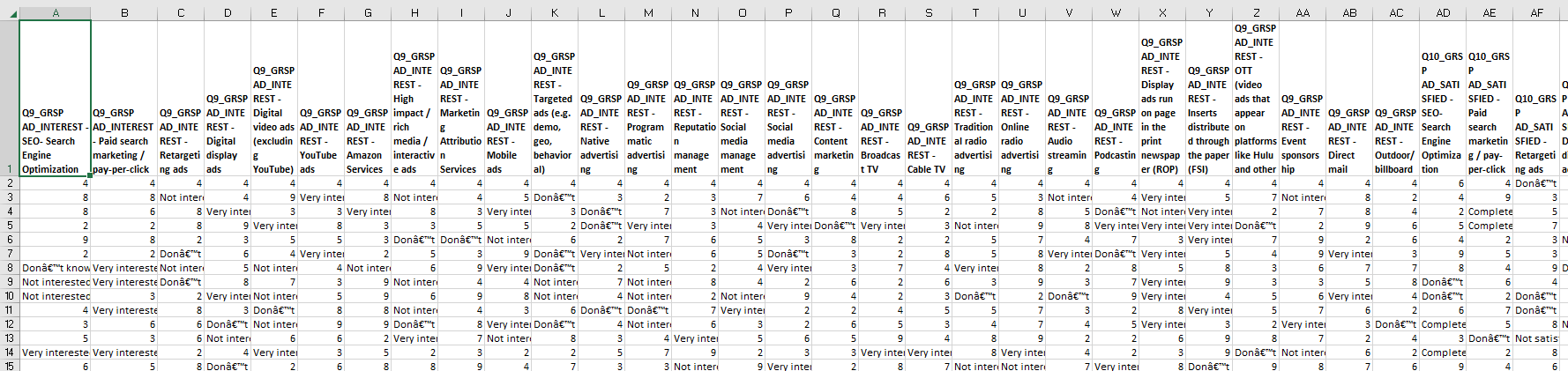
I was not able to attach dataset but below is the screenshot of Q9 and Q12 questions from dataset for your reference.
I tried two ways to achieve my requirement, so below are the details of the first way which i tried.
In first way, i tried to execute two loops for rowS/columns, access the values, compare them and then accordingly set the new column value.
Code is partially working, so for example, if you will review dataset row 1 and Q9 question, you will find that all responses are 4 and I am successfully able to create column STLINEQ9 and mark it as 1.
However, for row 2 we have all the responses for Q12 are 9 but code is not working properly to mark STLINEQ12 as 1.
After debugging, i was able to find out the issue but below are the two reasons that i am not invested time to fix the issue.
I was not able to identify a way that how to fix the issue.
And i think that this is not the efficient way to achieve the goal as with large set of data this code might not perform well.
Below is the code snippet for your reference which i applied in which df_Final is holding data.
prev=""
clname = ""
for row in range(len(df_Final.index)):
temp = ""
for i in df_Final.columns:
STLINE = 1
if i.find('_GRSP')!=-1:###Checking for SP GRID
if (i[:i.index("_GRSP")]+"_GRSP")!=prev:
temp = df_Final.loc[row,i]
print((i[:i.index("_GRSP")]+"_GRSP"), "----",row)
print(temp)
if i.find(i[:i.index("_GRSP")]+"_GRSP")!=-1 and df_Final.loc[row,i] != temp: #### Column with Q9_GRSP format compare
STLINE = 0
prev = (i[:i.index("_GRSP")]+"_GRSP")
print(STLINE)
if i.find('_GRSP')!=-1:
clname = 'STLINE'+i[:i.index("_GRSP")]
#df_Final.at[df_Final.index[row],clname] = STLINE
df_Final.loc[df_Final.index[row],clname] = STLINE
#df_Final.iloc[row,df_Final.columns.get_loc("STLINE")] = bool(STLINE)
#df_Final.loc[df_Final.index[row],clname]
df_Final
I will send the second way which i am trying as a next comment.
As a second way i thought of picking the column names first and then mergin them in a column.
After that referring to that single column, i can perform my checks to set new column for each question.
i am able to pull column names and merge them as well, but the merge happened row wise and for all the questions at once.
Not able to think of the way to have a separate merged column for Q9, Q10, Q11 and so on, that too column wise and not row wise.
Below is the code which i have written for this till now.
COL_GRSP = []
df_SL = []
for i in df_Final.columns:
if i.find('_GRSP')!=-1:
COL_GRSP.append(i)
for i in COL_GRSP:
df_SL.append("---".join(df_Final[i]))
To be clear: you are using the Pandas library? And you use that ahead of time to read the file and create a Dataframe? It’s important to make this kind of thing clear, because there are other possibilities. We should not have to guess based on your variable names.
COL_GRSP = []
df_SL = []
prev = ""
for i in df_Final.columns:
if i.find('_GRSP')!=-1:
if prev != i[:i.index("_GRSP")] and len(prev)>0:
COL_GRSP.append('-')
COL_GRSP.append(i)
prev = i[:i.index("_GRSP")]
COL_GRSP.append('-')
# COL_GRSP
for row in range(len(df_Final.index)):
for i in COL_GRSP:
if i=='-':
df_Final.loc[df_Final.index[row],"STLINE"+prev] = st_line
temp=""
st_line = 1
continue
if len(temp)==0:
temp=df_Final.loc[row,i]
if df_Final.loc[row,i]!=temp:
st_line = 0
prev = i[:i.index("_GRSP")]
I am sure that it might be not the best way to achieve the goal but for now it’s working.
Let me know if this code sounds good to you or you have any suggestions to make the code efficient considering that in future we can have thousands of rows in data set.