For some reason unknown to me EasyOCR will or will not at times read clearly legible Japanese text at random and I need help getting to the bottom of why? Can anyone help?
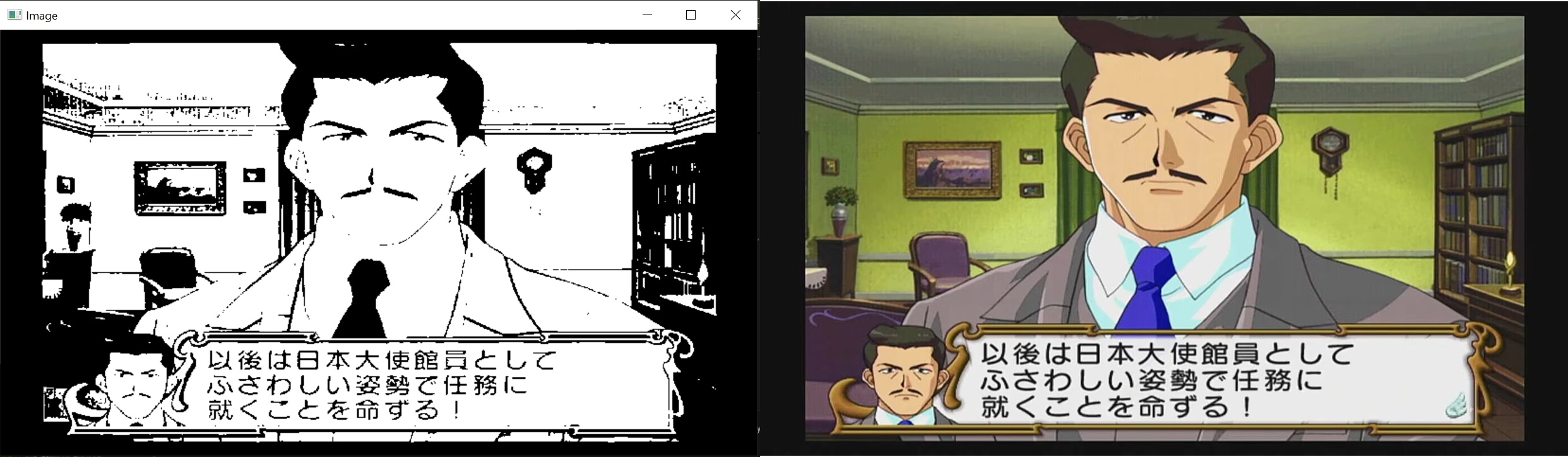
img = cv2.imread(imgap)
if img is None:
print("Image not found at path")
# Increase contrast
contrast = cv2.convertScaleAbs(img, alpha=1.5, beta=1)
# Greyscale
gray = cv2.cvtColor(contrast, cv2.COLOR_BGR2GRAY)
# Denoise the image with Gaussian Blur
blurred = cv2.GaussianBlur(gray, (3, 3), 0)
# Threshold the image (binary)
_, threshold_img = cv2.threshold(blurred, 128, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU)
# Calculate the percentage of black pixels
import numpy as np
black_pixels = np.sum(threshold_img == 0)
total_pixels = threshold_img.size
black_ratio = black_pixels / total_pixels
# Invert the image if black pixels dominate
if black_ratio > 0.75:
processed_img = cv2.bitwise_not(threshold_img)
else:
processed_img = threshold_img
# Perform OCR on the processed image
reader = easyocr.Reader(['ja'], gpu=True)
result = reader.readtext(processed_img, text_threshold=0.6, low_text=0.2)
print(result)