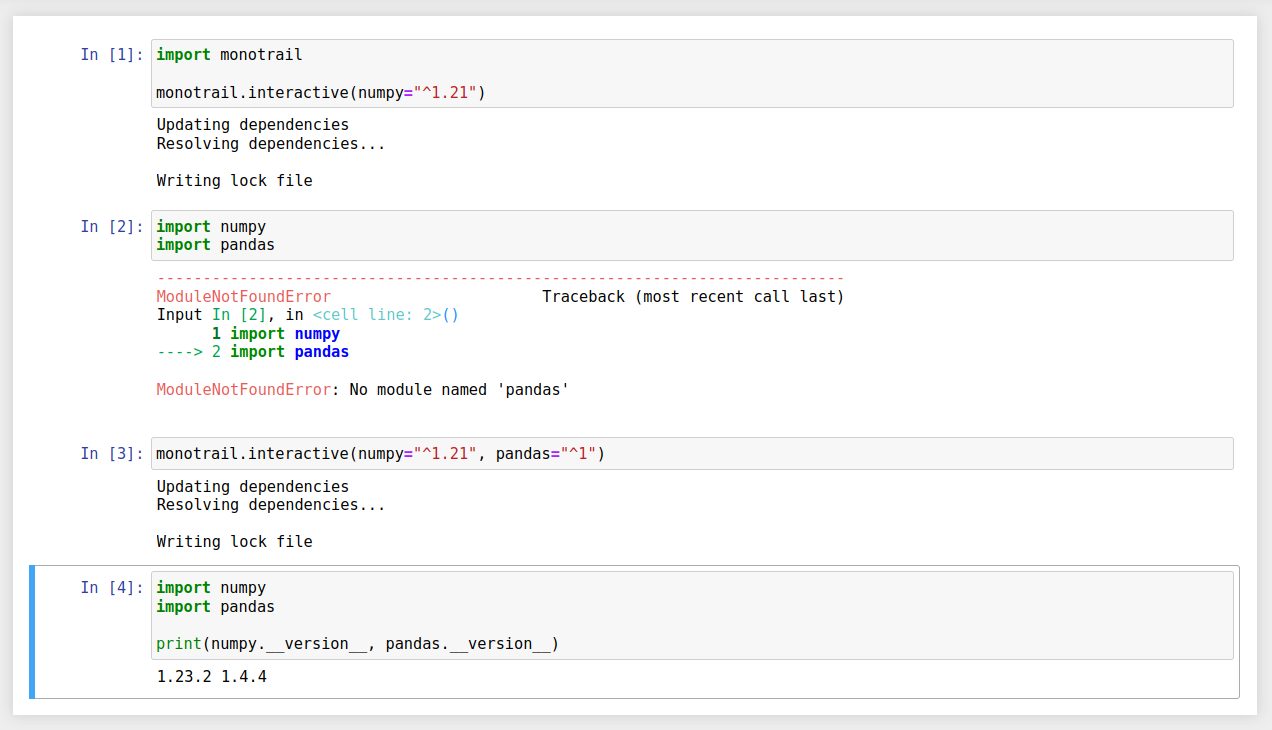
One-sentence summary: “The aim is to have multiple package versions installed side-by-side, and select which ones are importable at run time, based on a lock file.” (thanks @takluyver!)
This writeup got a bit too long so TL;DR at the top: as a proof of concept, I implemented a basic wheel installer which installs packages to .../multi-site-packages/{package_name}/{version} to allow for multiple package versions to be stored in a single environment; also made a basic importlib PathFinder which reads a requirements specification file (in this case a Poetry lock file) to decide which package versions to import.
With this you no longer need to create a virtual environment to have isolated dependencies for projects, all that is needed is a poetry lock file in a directory to specify which version of a package should be loaded from multi-site-packages/{package_name}/{version}.
IMO this potentially has a lot of benefits, main one being removing the need to have multiple venvs with duplicated packages installed inside them, but before spending more time on this I’d be curious to get some feedback from the community.
The repository for this proof of concept can be found here: GitHub - RobertRosca/pipm at feat/initial-dev (note the branch is feat/initial-dev)
My aim was to achieve this with as few changes as possible and in as simple of a way as possible, I’m aware that there are a lot of caveats and issues with the implementation, it is just a proof of concept for storing multiple versions of packages in a central location and deciding which package to load from a lock file.
For anybody interested here’s some more details:
This is a proof of concept implementation of a Julia-like approach to packaging in Python. For those not familiar, here is a summarised version of the background to the Julia package manager (I recommend reading the page fully for those interested):
- Pkg is designed around “environments”: independent sets of packages that can be local to an individual project or shared and selected by name
- The exact set of packages and versions in an environment is captured in a manifest (lock) file
- Since environments are managed and updated independently from each other, “dependency hell” is significantly alleviated in Pkg
- The location of each package version is canonical
- When environments use the same versions of packages, they can share installations, avoiding unnecessary duplication of the package
To illustrate this better, here are some comparisons between current behaviour and a theoretical Julia-like implementation:
Installing a package without an environment (e.g. pip install --user):
- Currently for python:
-
pip installcommand without a virtual environment activated - the package is installed under
~/.local/lib/python3.10/site-packages/{package_name} - python looks through
site-packagesfor imports
-
- For Julia-like package system:
- install command adds the package to a pyproject file, creates/updates a lock file
-
pip install --userequivalent command would add the package to a ‘user level’pyprojectfile and update thelockfile (e.g. Poetry, Pipenv, etc…), these files are stored in a user-level directory, e.g. under~/.local/state/python3.10/envs/default/{pyproject,lockfile} - package(s) installed under
~/.local/lib/python3.10/multi-site-packages/{package_name}/{package_version} - python reads the pyproject/lock files and uses that information to decide which package versions to import
Now, when installing a package with an environment:
- Currently for python:
-
python3 -m venv .venvto create a new virtual environment -
source .venv/bin/activateto activate it -
pip installto install packages into the environment - the venv is (ignoring
--system-site-packages) completely isolated and all packages are installed in it independently of whatever else is on the system
-
- For the Julia-like approach:
- environments are only defined by a
pyprojectfile andlockfile existing in a directory or parent directory, so ‘creating’ one just means having those files theredetails on local/global environments
In Julia you have the concept of local environments which are what I describe above, where the project/lock files are in a directory, but you can also have environments stored in a central location which make activating environments anywhere you want possible, in a similar way to how conda works
-
pip installequivalent command would add the package to thepyprojectfile and update thelockfile (e.g. Poetry, Pipenv, etc…) - package(s) installed under
~/.local/lib/python3.10/multi-site-packages/{package_name}/{package_version} - python reads the pyproject/lock files and uses that information to decide which package versions to import
- environments are only defined by a
In both cases the key difference is that packages would continue to get installed under ~/.local/lib/ instead of into a virtual environment directory, with which package to use being specified in the pyproject.toml file.
There are a lot of benefits to this approach, but IMO the main ones are:
- Always have a file that specifies what your current environment is, even when just using user installs
- Avoids unnecessary duplication of package installs, lowering the space used on user devices and the time taken for installs
- No overwriting of packages during updates
As a proof of concept I implemented this in the most basic way I could think of doing, it’s pretty hacky but works alright as a rough proof of concept to demonstrate the idea. The PoC works by:
- Using installer to implement a basic wheel installer that installs packages to
multi-site-packages/{package_name}/{package_version} - Using Poetry to manage the
pyproject.tomlandpoetry.lockfiles - Adding a custom
importlibfinder which reads a lockfile and inserts the path to the requested version of the package intosys.pathbefore importing - Importing this finder and prepending it to
sys.meta_pathin thesitecustomize.pyfile - Adding a very crappy
pipm(meaning ‘pip multi’, I am not creative) CLI call which just runspip download . -d ./tmp-wheelhousein a Poetry-managed project, then runs the custom wheel installer on all files in the wheelhouse, this is what actually installs dependencies tomulti-site-packages
I tend to use Poetry for all of my projects so to test this out I ran pipm in a few different repos to populate the multi-site-packages directory and played around a bit, surprisingly enough this basic approach sort of works:
~/.../pipm ❯ python3 -c 'import click; print(click.__file__)'
/home/roscar/.cache/pypoetry/virtualenvs/pipm-p7aS5F8W-py3.10/lib/python3.10/multi-site-packages/click/8.1.3/click/__init__.py
~/.../beanie ❯ python3 -c 'import click; print(click.__file__)'
/home/roscar/.cache/pypoetry/virtualenvs/pipm-p7aS5F8W-py3.10/lib/python3.10/multi-site-packages/click/8.0.4/click/__init__.py
~/.../starlite ❯ python3 -c 'import click; print(click.__file__)'
/home/roscar/.cache/pypoetry/virtualenvs/pipm-p7aS5F8W-py3.10/lib/python3.10/multi-site-packages/click/8.1.3/click/__init__.py
~/.../starlite ❯ python3 -c 'import httpx; print(httpx.__file__)'
/home/roscar/.cache/pypoetry/virtualenvs/pipm-p7aS5F8W-py3.10/lib/python3.10/multi-site-packages/httpx/0.23.1/httpx/__init__.py
~/.../beanie ❯ python3 -c 'import httpx; print(httpx.__file__)'
Traceback (most recent call last):
File "<string>", line 1, in <module>
ModuleNotFoundError: No module named 'httpx'
Above you can see:
- In
pipmdirectory,clickis version 8.1.3 - In
beaniedirectory,clickis version 8.0.4 - In
starlitedirectory,clickis version 8.1.3 - In
starlitedirectory,httpxis version 0.23.1 - In
beaniedirectory,httpxis ‘not installed’
Which is the desired behaviour.
I’d be interested in hearing feedback for this approach, both in the context of a standalone tool and on the potential of something vaguely like this being included in Python.
Caveats
I have found some similar discussions on having multiple packages installed at the same time (Installing multiple versions of a package - #13 by PythonCHB, Allowing Multiple Versions of Same Python Package in PYTHONPATH), however they were mostly centred around the idea of being able to import incompatible versions of packages in the same environment, which this does not attempt to do or enable. You would still have one and only one version of a package available.
There has been a lot of discussion on this topic in the past and there is ongoing discussion on topics like PEP 582, but I didn’t find anything too similar to this apart from a few suggestions like optimize package installation for space and speed by using copy-on-write file clones ("reflinks") and storing wheel cache unpacked · Issue #11092 · pypa/pip · GitHub.
Also I am aware that the proof of concept implementation has a great deal of flaws, but my goal with it was to keep it simple and minimal not complete.