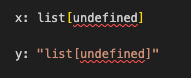
The type system allows encosing annotations in strings in cases where the annotation would not evaluate successfully at runtime (e.g., when the annotation contains a forward reference).
But Python has many kinds of strings. How should the following program be type checked?
def invalid_strings(
raw: r"int",
fstring: f"int",
bytestring: b"int",
uprefix: u"int",
implicit_concat: "in" "t",
unicode_name: "\N{LATIN SMALL LETTER I}nt",
backslash_escape: "\x69nt",
):
reveal_type(raw)
reveal_type(fstring)
reveal_type(bytestring)
reveal_type(uprefix)
reveal_type(implicit_concat)
reveal_type(unicode_name)
reveal_type(backslash_escape)
- Pyright: raw, bytestring, and uprefix are allowed; the others produce errors, some of which have room for improvement (reported Incorrect error when quoted type annotation is an f-string · Issue #7640 · microsoft/pyright · GitHub)
- Mypy: only raw and fstring are rejected
- Pyre: only fstring and unicode_name are rejected
- Pytype: only bytestring is rejected
My thoughts:
- f-strings are too dynamic and should not be allowed in annotations. All type checkers should reject them. Pytype currently allows them, at least in this simple example.
- bytestrings should be rejected because bytestrings are conceptually a different type than text strings, and type annotations are text, not binary data. Pyright and pyre currently allow them.
- unicode strings with the
uprefix should be accepted because in Python 3 they are completely equivalent to non-prefixed strings. All type checkers already allow them. - raw strings may be allowed. I can envision use cases involving Literal where a raw string may be useful. All type checkers currently allow them. However, use cases are very limited and they may be difficult to support correctly, especially for type checkers written in languages other than Python. Support for raw string annotation can be made optional.
\Nand\xescapes in strings are similar: they could conceivably be useful in some cases involving literals, but they may also make life harder for type checker maintainers for little gain. Support should be optional.- implicit concatenation may also be allowed as it can be useful with very long annotations. The spec already explicitly allows triple-quoted strings for this case, but Python the language provides multiple ways to build up long string literals, and I don’t see a strong reason why the type system should be more restrictive. Pyright currently rejects this case; Eric Traut brought up concerns about character ranges for error messages. I am OK with making support for this feature optional.
I started looking at this because @erictraut brought up a few of these cases in Basic terminology for types and type forms - #43 by davidfstr. The situation seems tricky enough that I’m splitting it out of that thread (which is about definitions of basic terms in the type system).
In summary, my proposal is:
- Type checkers must support string annotations that do not contain any backslash escapes and that have either no string prefix or the
uprefix. - Type checkers must reject string annotations that are byte strings or f-strings.
- Type checkers may support raw strings and backslash escapes in string annotations.
This aligns best with mypy’s current behavior.