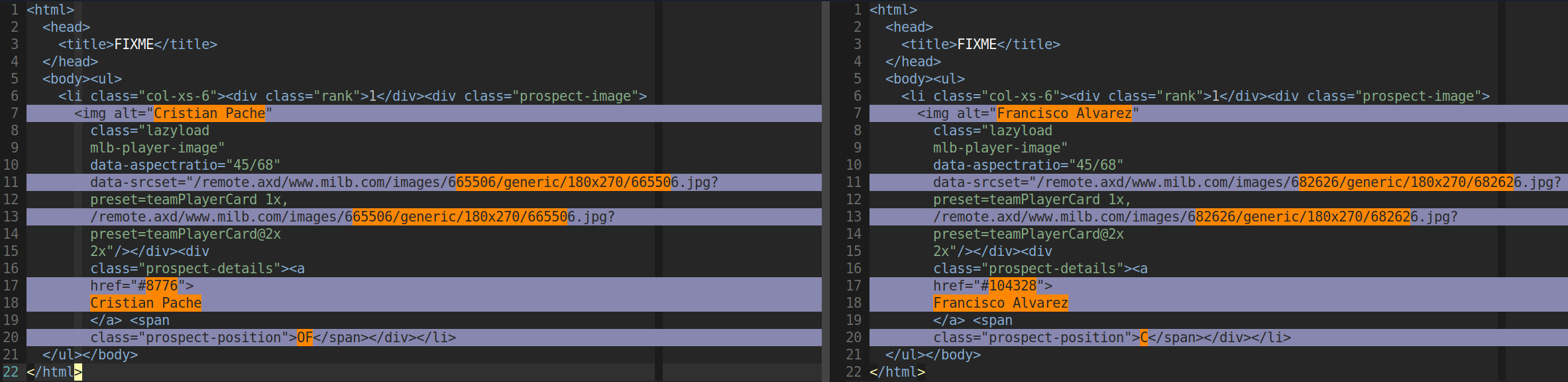
I probably didn’t ask the right question. The IMG tag is a bs4.object that was extracted as part of a list. There are 30 list elements. This is one of the elements:
I have been working on the code and this is what I’ve come up with:
for first_player in my_list:
rank = first_player.div.text
ranks.append(rank)
name = first_player.a.text.strip()
names.append(name)
position = first_player.span.text
positions.append(position)
player_id = first_player.find('img').attrs['data-srcset'].split('/')[4]
player_ids.append(player_id)
This has worked on 27 of 30 webpages. I’m stumped as to why it doesn’t work on the other 3. The pages are the same but with different players on them. On the ones that it doesn’t work I get this error:
Traceback (most recent call last):
File "C:/Users/HP/PycharmProjects/CTCBL/NYN.py", line 54, in <module>
player_id = first_player.find('img').attrs['data-srcset'].split('/')[4]
KeyError: 'data-srcset'
You can use a try … catch statement to filter out tags without the data-srcset attribute:
try:
player_id = first_player.find('img').attrs['data-srcset'].split('/')[4]
except KeyError:
pass # put any error handling here
else:
player_ids.append(player_id)
Thanks for the reply. Why does the code work on other pages? There are 30 team pages and it works on 27 of them. This is an object in the list that it does work on:
Marco, THANK YOU. I have learned something here. It doesn’t necessarily do the operations up till it finds an error it just errors. There was one element that didn’t have the data-srcset attribute. Because I’m not adept yet enough to do the code to handle errors, I just put a line of code in to remove item from the list and then inserted another one with corrected data in the spot. Now I will inspect the other 2 pages and find which element is causing those to error out.
Pleasure to help. Do consider the suggestion you got from another user of
wrapping your metadata extraction logic in a try/except block so that you may
process the items you can and disregard those you can’t without halting.
You could also log information about items you could not process to study them
or process them with another strategy later. Useful topics: “Python logging”,
“difference between stdout and stderr”.
Yes, that definitely is on my agenda. This was my first attempt at getting some baseball data for my personal projects. I plan on doing some more reading and expanding my programs. It is all a learning process.