this gives me the below to get the min date for the duplicates but I am not sure how to get the oldest date ‘number’ into new column ‘Required Output’ for the newest date of the duplicate with an ‘a’ at the end
I have updated above but am using the below but not sure how to advance to get the ‘number’ of the row with the min date with an ‘a’ into the newer date row.
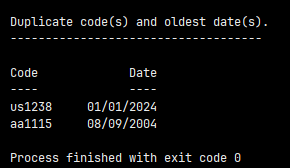
here is a script that satisfies the first two bullet points as stated above:
There is enough here to work from that you can work out the last two bullet points.
from pathlib import Path
FILE_PATH = Path('/Users/myComp/AppData/Roaming/JetBrains/PyCharmCE2024.1/scratches/temp_search_duplicate.txt')
def obtain_oldest_date_code(filename):
with open(filename) as file:
data = file.readlines()
data_pairs = {} # Create dictionary for date / code pairs
codes = [] # Duplicate code list
for line in data: # iterate through each line
columns = line.split() # Separate each data column
try: # Only read non-string values in first column
if type(int(columns[0])) is int:
data_pairs[columns[1]] = columns[2]
codes.append(columns[2])
except ValueError: # Ignore if a string value (i.e., column titles not part of analysis)
pass
duplicate_codes = list({x for x in codes if codes.count(x) > 1}) # Create list of duplicate values
print('\nDuplicate code(s) and oldest date(s).')
print('------------------------------------')
print('\nCode Date')
print('---- ----')
for code in duplicate_codes:
dates_list = []
for key, value in data_pairs.items():
if code == value:
dates_list.append(key)
oldest_date = min(dates_list)
print(code, oldest_date, sep=' ')
obtain_oldest_date_code(FILE_PATH)