Hello everybody. I was testing free-threaded Python on my Mac (through uv’s cpython-3.13.0+freethreaded-macos-x86_64-none) and noticed that multi-threaded access to collections was VERY slow. I did a quick comparison of different benchmarks that include simple operations like appending/adding elements, removing elements, etc and ran them both in Linux and Mac and the difference is astonishing.
For reference, I own a 2019 Macbook with an 8-core i9 32GB RAM. For the Linux benchmarks I used a GCP instance (c4-standard-4, 4vCPUs, 15GB RAM).
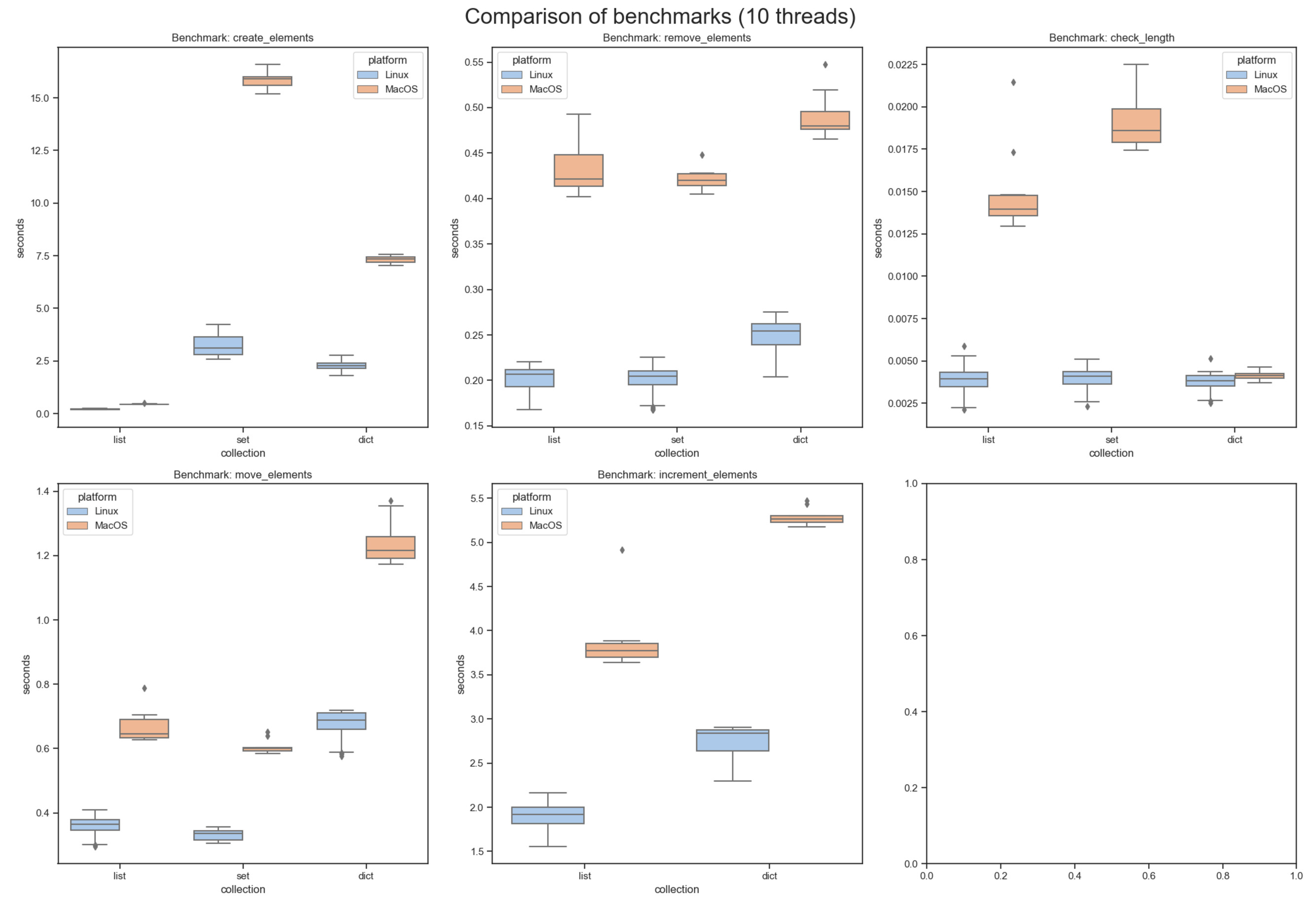
I ran these benchmarks using 100 threads, and here are the results:

(slowdown is computed as time in seconds Mac / time in seconds Linux)
As you can see the performance on my Mac is considerably worse.
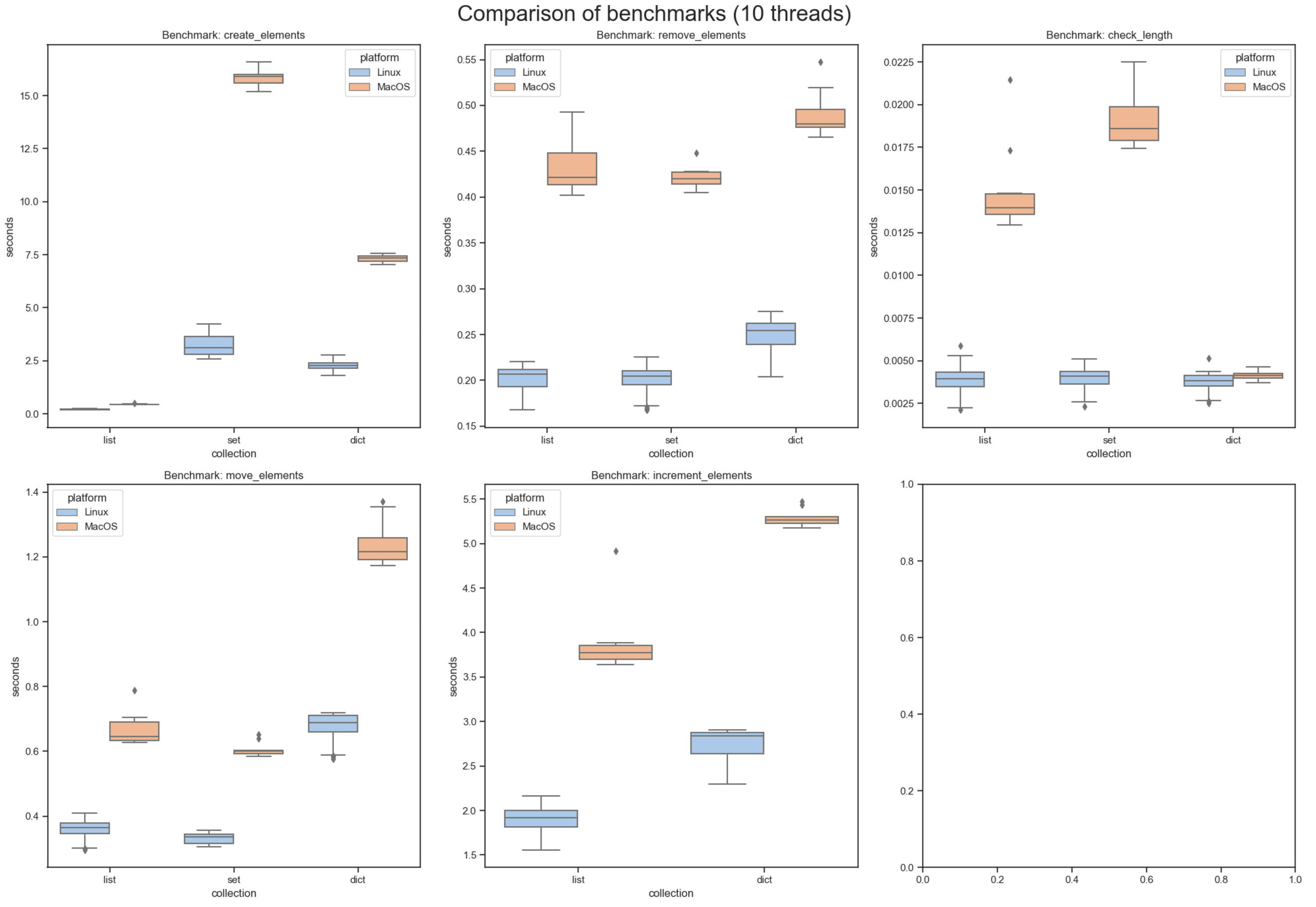
For something less extreme, only 10 threads, there’s also a considerable penalty:
(image removed because I can post only one image as new user)
Is there any implementation detail in the locking mechanisms to make collections thread safe on freethreaded python that is maybe causing this?
For reference, I created the benchmarks for each different type of collection. For example:
Create elements
# For lists
a_list = []
def target(n_iters):
for _ in range(n_iters):
a_list.append(1)
# for sets
a_set = set()
def target(n_iters):
for i in range(n_iters):
a_set.add((threading.get_ident(), i))
# for dicts
a_dict = {}
def target(n_iters):
for i in range(n_iters):
a_dict[(threading.get_ident(), i)] = 1
And always ran the benchmarks in this way:
# 100 threads, 1000 iterations each
threads = [threading.Thread(target, args=(1_000,)) for _ in range 100]
start = time.monotonic()
[t.start() for t in threads]
[t.join() for t in threads]
print(f"Total time: {time.monotonic() - start}")