Hi,
Assume there is a data from external api (means I cannot change the shape of it).
# data from 3rd party API call.
data = {
"AUTHOR": "guido",
"TITLE": "python",
"PUBLISHED": 1991,
"QRCODE": "...",
}
I have Book dict for internal use (within application boundary).
from typing import TypedDict
class Book(TypedDict):
author: str
title: str
In order to fit the external data into book for internal use, I wrote as follows:
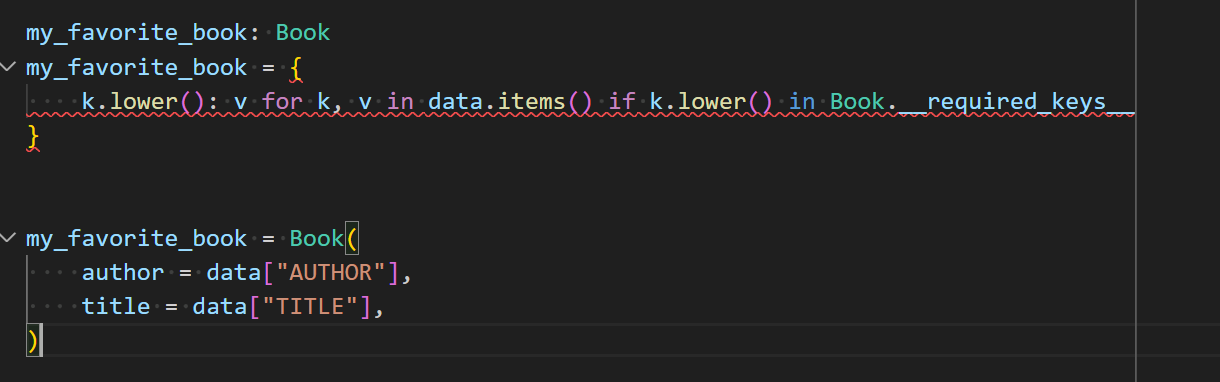
# availble approach 1.
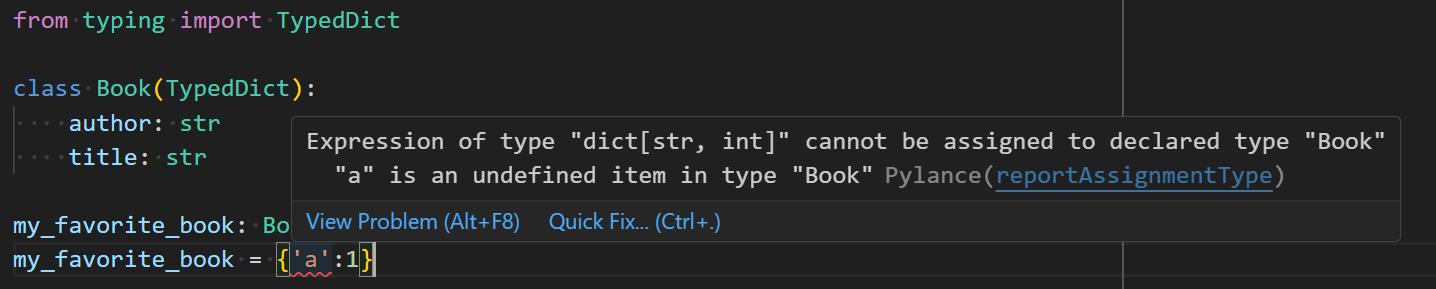
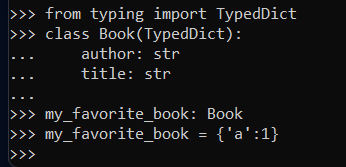
my_favorite_book: Book
my_favorite_book = {
k.lower(): v for k, v in data.items() if k.lower() in Book.__required_keys__
}
# available approach 2.
my_favorite_book = Book(
author = data["AUTHOR"],
title = data["TITLE"],
)
The Book only has 2 keys (author, title) in this example. However, there are cases where number of keys is between 10 and 30. I chose approach 1 but I am not sure it’s readable or idiomatic… Just put every key mappings manually (approach2) is better? Or any other suggestions?
The situation where I am in is that I have to convert many fileds with uppercase in partial fields with lowercase keys. For example:
{PRICE: ..., RISK: ..., RATIGING:...} -> {price:..., rating: ...} .
Thanks for reading!!