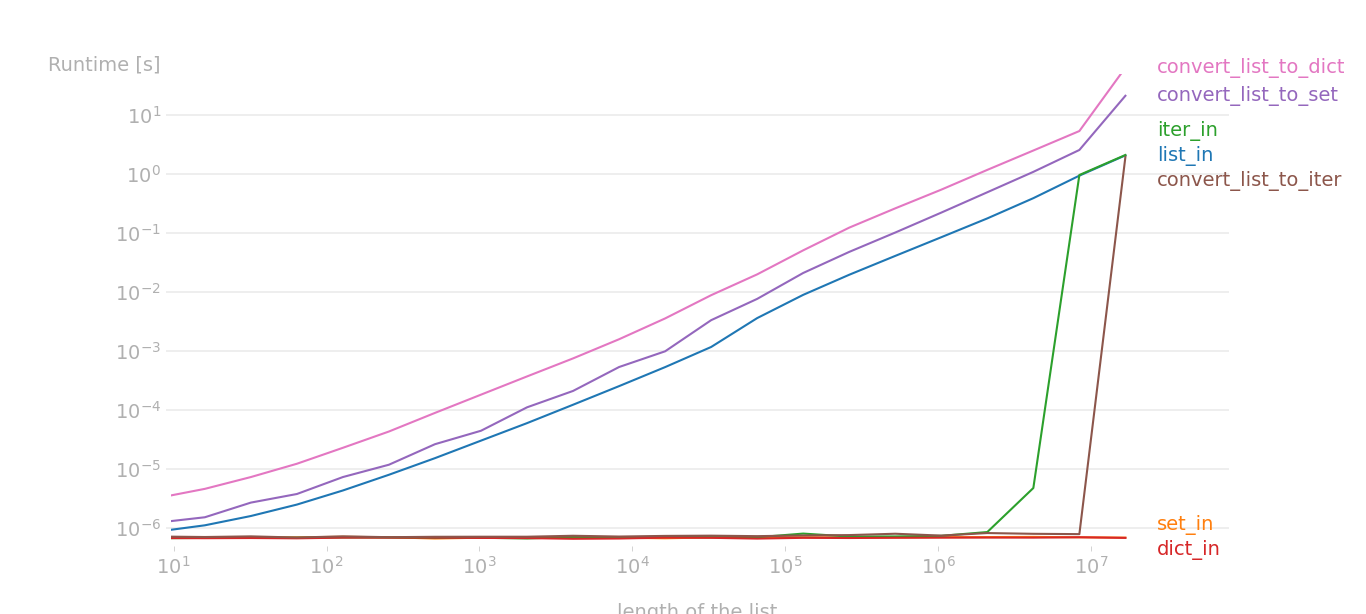
We can actually write a handy script to help us understand what timeit was trying to accomplish:
import time
list_ = list(range(10**3))
iter_ = iter(list(range(10**3)))
list_time_samples = []
iter_time_samples = []
for _ in range(100):
start = time.perf_counter_ns()
_ = -99 in list_
end = time.perf_counter_ns()
list_time_samples.append(end - start)
for _ in range(100):
start = time.perf_counter_ns()
_ = -99 in iter_
end = time.perf_counter_ns()
iter_time_samples.append(end - start)
print(sum(list_time_samples)/100, sum(iter_time_samples)/100, sep="\n")
print(iter_time_samples)
Output:
30687.56
1081.99
[53969, 629, 551, 573, 561, 539, 539, 644, 531, 544, 537, 516, 526, 548, 549, 539, 661, 539, 644, 581, 674, 534, 542, 531, 572, 536, 554, 586, 566, 707, 544, 700, 527, 546, 551, 536, 542, 553, 564, 534, 476, 514, 566, 1043, 511, 529, 514, 504, 499, 504, 509, 486, 507, 511, 516, 511, 509, 528, 509, 486, 506, 624, 506, 506, 546, 501, 516, 608, 524, 504, 509, 513, 508, 506, 586, 564, 511, 519, 682, 506, 572, 516, 557, 514, 514, 519, 596, 514, 624, 511, 521, 508, 516, 531, 544, 519, 514, 496, 514, 503]
That’s how timeit tricked me to make iter looks faster, it was measuring StopIteration all the time. Good to know! That sneaky little time watcher!