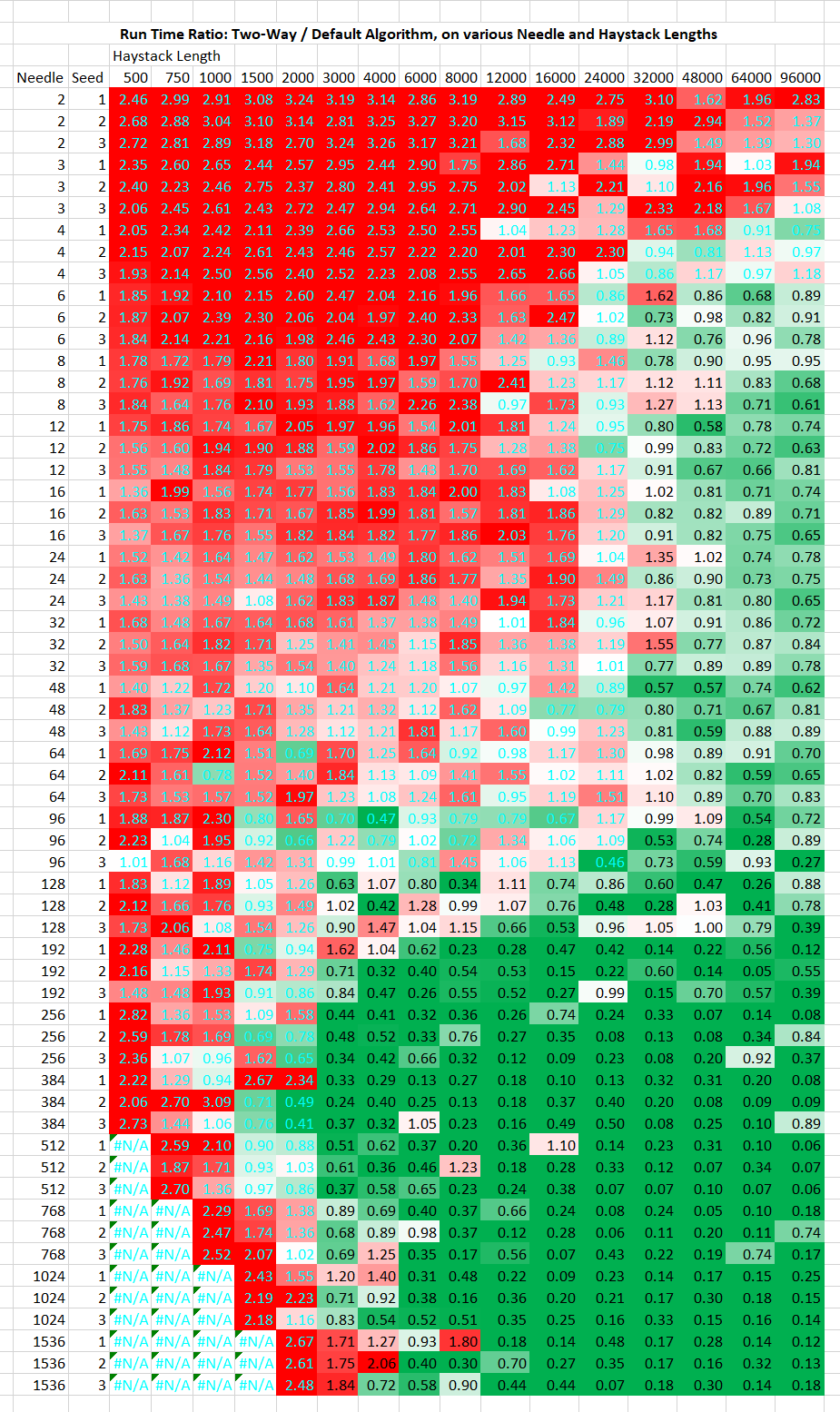
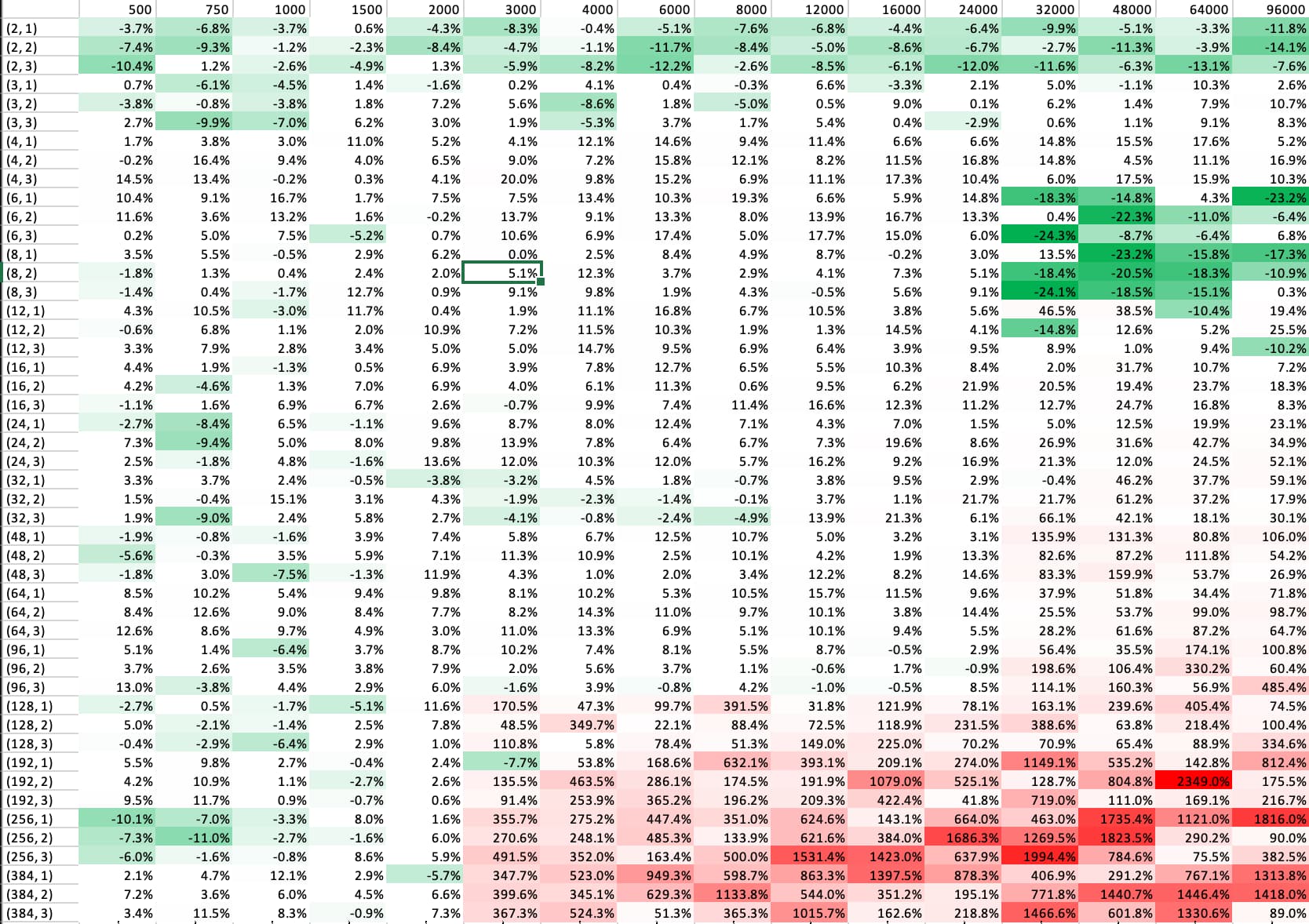
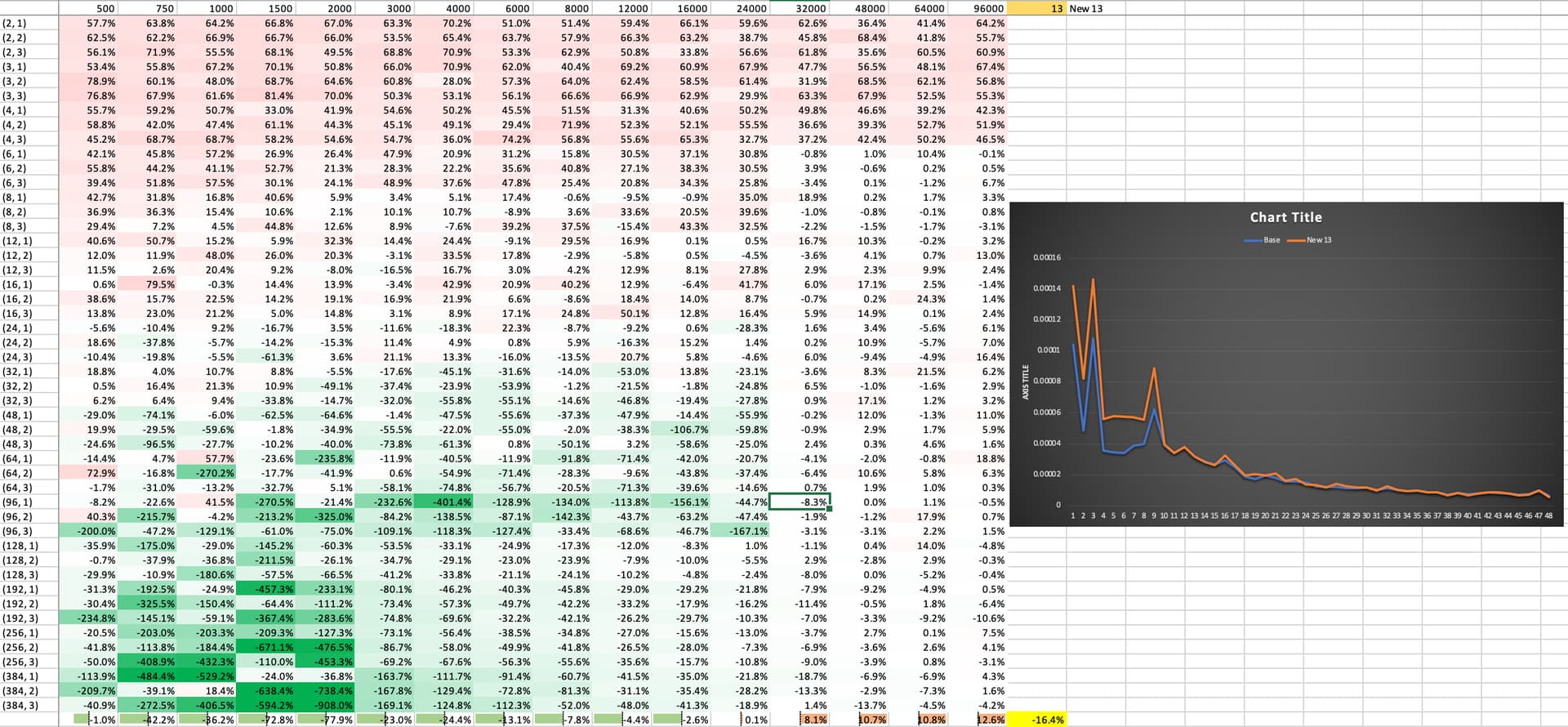
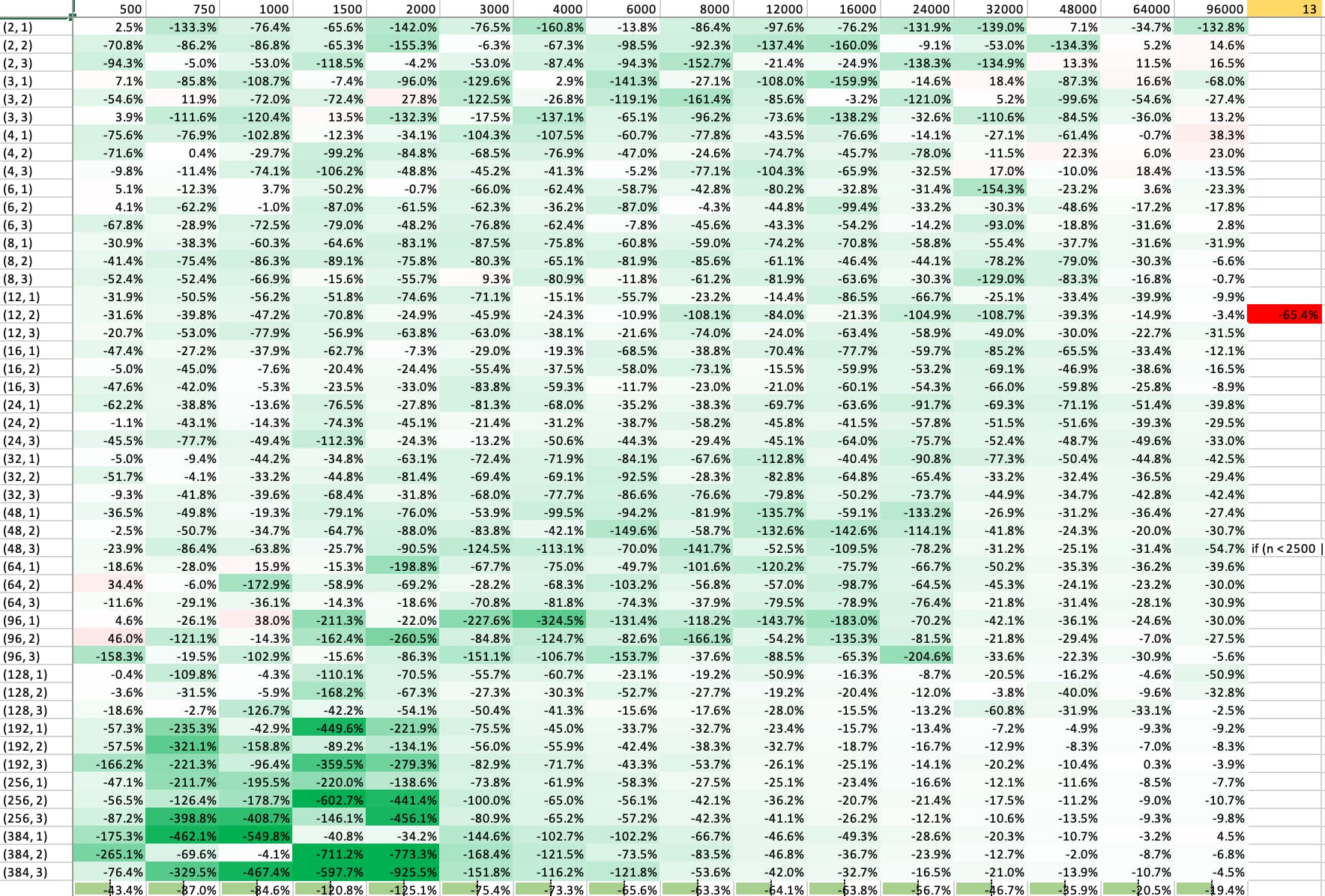
Benchmark
Notes:
- There is a constant overhead of ~
160ns
- Some small optimizations are still to be made, but nothing that would change below results by much.
Set-up
s = '_' * N
if best:
ch = '.'
elif worst:
ch = '_'
ss = ch * (m - 2) + '1' + ch
def test_func():
s.find(ss)
Results
OS-11.7.10-x86_64-i386-64bit-Mach-O | 3.14.0a0
macOS-11.7.10-x86_64-i386-64bit-Mach-O | 3.14.0a0
------------------------------------------------------
N=10 Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 286 | 366 | 224 | 221
3 | 224 | 225 | 211 | 222
4 | 218 | 249 | 212 | 226
5 | 238 | 225 | 248 | 231
6 | 285 | 232 | 213 | 227
7 | 222 | 258 | 215 | 250
8 | 360 | 245 | 242 | 237
9 | 222 | 248 | 215 | 224
------------------------------------------------------
N=100 Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 376 | 398 | 314 | 468
3 | 317 | 422 | 304 | 448
4 | 350 | 444 | 311 | 417
5 | 269 | 372 | 251 | 461
6 | 246 | 409 | 236 | 424
9 | 235 | 456 | 229 | 476
10 | 232 | 491 | 226 | 439
30 | 238 | 825 | 236 | 687
40 | 252 | 1,061 | 452 | 663
90 | 279 | 620 | 377 | 726
------------------------------------------------------
N=1K Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 1,098 | 1,525 | 1,094 | 1,798
3 | 872 | 1,725 | 856 | 1,877
4 | 769 | 1,765 | 733 | 2,245
5 | 657 | 1,871 | 849 | 2,289
6 | 597 | 1,835 | 617 | 2,081
9 | 491 | 2,845 | 484 | 2,097
10 | 467 | 3,144 | 453 | 2,050
100 | 296 | 23,885 | 278 | 2,387
300 | 403 | 47,235 | 378 | 2,828
400 | 441 | 57,311 | 434 | 3,105
900 | 884 | 19,768 | 720 | 4,250
------------------------------------------------------
N=10K Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 9,262 | 13,309 | 9,023 | 15,964
3 | 6,951 | 13,907 | 6,889 | 17,373
4 | 5,574 | 15,146 | 5,774 | 18,952
5 | 4,789 | 16,044 | 4,989 | 20,035
6 | 3,845 | 16,172 | 4,482 | 18,943
9 | 2,904 | 26,679 | 3,036 | 19,452
10 | 2,677 | 28,419 | 2,570 | 18,721
100 | 894 | 18,799 | 544 | 18,462
1000 | 3,459 | 21,939 | 753 | 20,564
3000 | 10,670 | 23,477 | 1,821 | 24,998
4000 | 2,827 | 28,243 | 2,389 | 27,754
9000 | 4,935 | 1,722,265 | 4,973 | 38,100
------------------------------------------------------
N=100K Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 91,451 | 136,300 | 96,473 | 166,890
3 | 73,523 | 149,025 | 71,222 | 182,560
4 | 57,877 | 160,103 | 59,756 | 185,634
5 | 50,188 | 163,632 | 46,594 | 183,795
6 | 57,090 | 198,212 | 41,886 | 194,464
9 | 36,564 | 185,232 | 30,860 | 195,669
10 | 33,569 | 199,484 | 26,517 | 194,941
100 | 6,013 | 186,479 | 4,410 | 190,645
1000 | 4,994 | 205,996 | 1,105 | 191,947
10000 | 40,565 | 214,843 | 5,619 | 213,163
30000 | 105,320 | 232,888 | 17,065 | 267,391
40000 | 21,611 | 274,259 | 23,156 | 282,290
90000 | 55,079 | 402,467 | 47,837 | 372,822
-----------------------------------------------------
N=1M Current Proposed
units: ns | best | worst | best | worst
------------------------------------------------------
2 | 941,007 | 1,448,639 | 954,215 | 1,719,287
3 | 717,159 | 1,566,532 | 722,924 | 1,666,423
4 | 568,244 | 1,652,256 | 552,982 | 1,870,495
5 | 489,075 | 1,617,497 | 446,916 | 1,871,483
6 | 561,883 | 2,024,259 | 406,523 | 1,841,601
9 | 382,779 | 1,992,450 | 288,651 | 1,805,480
10 | 343,236 | 1,988,768 | 256,256 | 1,822,459
100 | 50,959 | 1,903,812 | 42,702 | 1,884,445
1000 | 34,911 | 1,879,474 | 7,173 | 1,807,063
10000 | 68,449 | 1,868,857 | 5,844 | 1,822,787
100000 | 339,663 | 2,060,019 | 53,211 | 2,016,727
300000 | 951,868 | 2,208,496 | 158,703 | 2,446,954
400000 | 212,162 | 2,681,579 | 215,990 | 2,668,347
900000 | 495,428 | 3,989,225 | 479,384 | 3,810,628