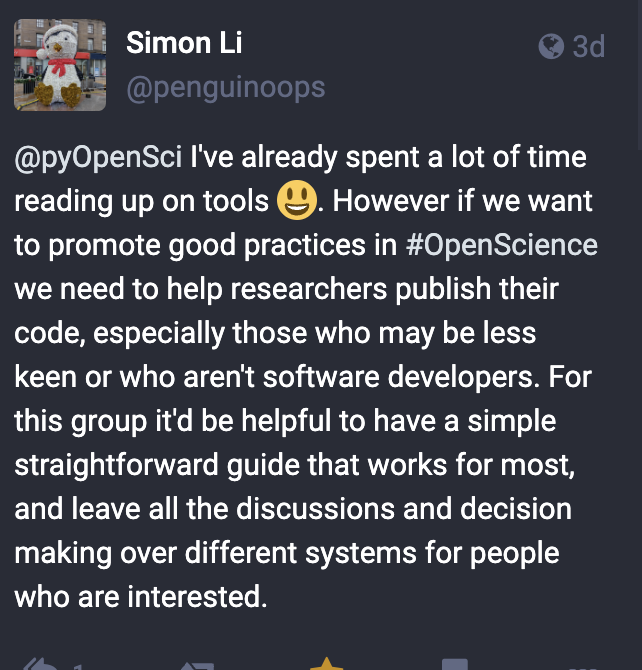
Hi everyone! i just wanted to chime in here. i do agree that understanding user needs is the most important starting place as those requirements will define the requirements for any tooling that supports packaging.
I am not sure if this is helpful but i have been working on a review of the existing packaging ecosystem for pyOpenSci. I’ve been asking people what their questions are about packaging and what would be useful (not formally but consistently). i’ve also taught python and R to people for gosh over 11 years now and understand the pain points of someone new entering an ecosystem like this.
Through our peer review process i see packages come in and often they aren’t sure of what best practices are - they are also often happy to adjust their package structure with guidance (but where is that guidance coming from?!).
The most common questions i get are things like
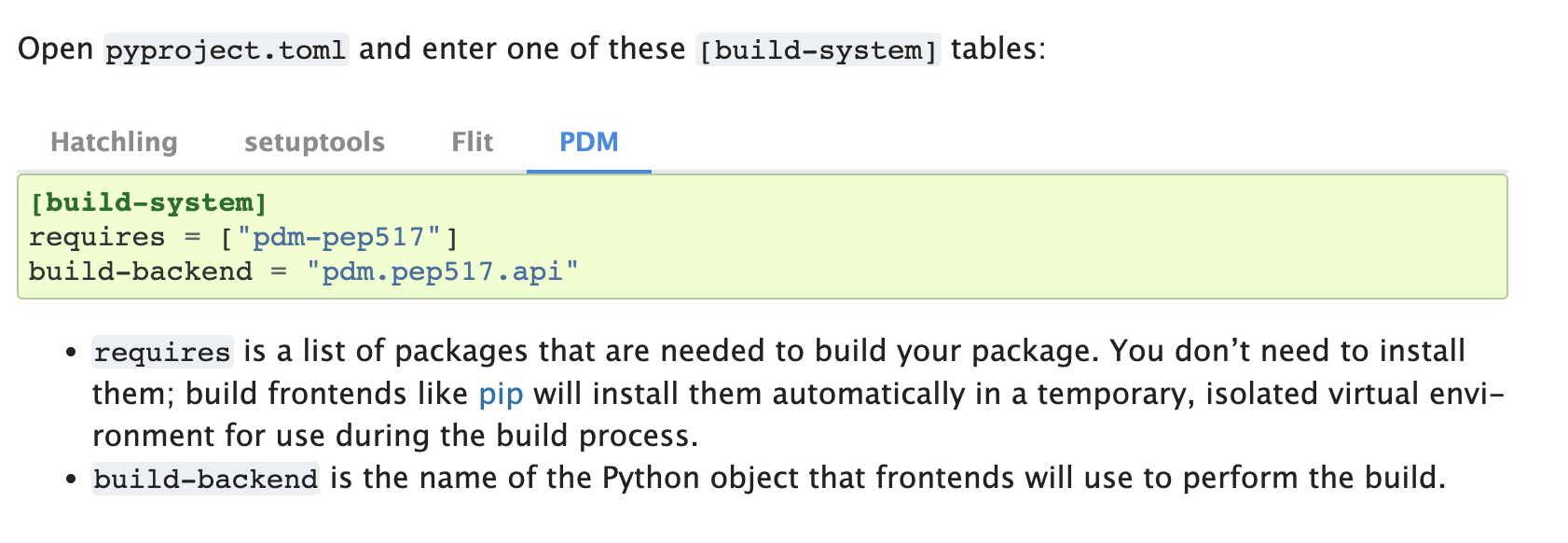
- should we use pyproject.toml for metadata or setup.py or setup.cfg
- where should we look for answers in terms of packaging? (there are many guides out there and cookie cutters and blog posts) i can assure you MOST of these are very dated. it’s a confusing user experience.
- how do we pick a tool to create a python package?
- what does a python package look like (should we use src/ etc?)
These are core common questions. and ones we don’t have to impose but can suggest. most people would appreciate those suggestions - they just want to build a package!
i’m just wondering if a list of requirements is the place to start aligned with an overview of existing tools (i have some summary data on hatch, pdm, flit, setuptools, poetry and some of the build back ends as well to contribute to this overview - to be published next week. i’ve also talked to maintainers in some cases to understand where the tools are headed.
the requirements can look something like a list of features the tool offers
front end features
- can it support different build backends?
- can it publish to pypi, do editable installs, setup a structure for your package for you (eg PDM init, hatch init)
- environment support (yikes!)
etc…
back end features
- does it support non pure python builds etc
- what files are included by default in the SDist /wheels etc
etc…
i also like to look at what the maintainer team looks like (bus factor) and can that maintenance be supported over time.
And maybe it’s a draft document that people can comment on?
Then perhaps a second survey goes out that is focused on the various tools and needs of the community but also that somehow categorizes the types of users (i think the science community for instance has specific use cases that need to be considered). there are likely others.
So after this work you have a list of what we want a tool (or tools) to do and be.
And you have specific feedback from users about their biggest pain points, what communities they are involved with, what their needs are. (separating front and back end tools out)
i think there are some real pain points in this community but one of them i think is related to good clear documentation with beginning to end examples for new users. we CAN build packages now. but users do NOT know where to go to figure out how. And i think many want to look to PyPA - it would be nice if that was the trusted source but people don’t know what PyPA is in many cases!
And also dealing with complex packaging needs is unclear. many don’t even know about tools like meson-python being available! or what build is.
I also wonder - would existing maintainers be willing to team up and work together (is that a dream that can’t happen given the competitive nature)?
id be happy to help on the survey end of things if that becomes of interest to build on top of the survey work already done. we will continue to evaluate existing tools in hopes of finding a single workflow that we could suggest to users NOW while all of this other important work is happening here too and am happy to contribute what we find if its useful!
i hope this very long post is somewhat helpful. i just want to users to have a bit of clarity and if we can support this effort with the work we’ve been doing (which is a huge effort!) i’d like to !