I noticed some strange behavior when searching string with diacritics using regex.
Fortunately in Python I get the results right, without any extra setting.
(So perhaps it’s wrong forum to write here, but still, I’d like to get some insight. )
Also in my text editor Notepad++, results are right.
import re
# sample text from ChatGPT:
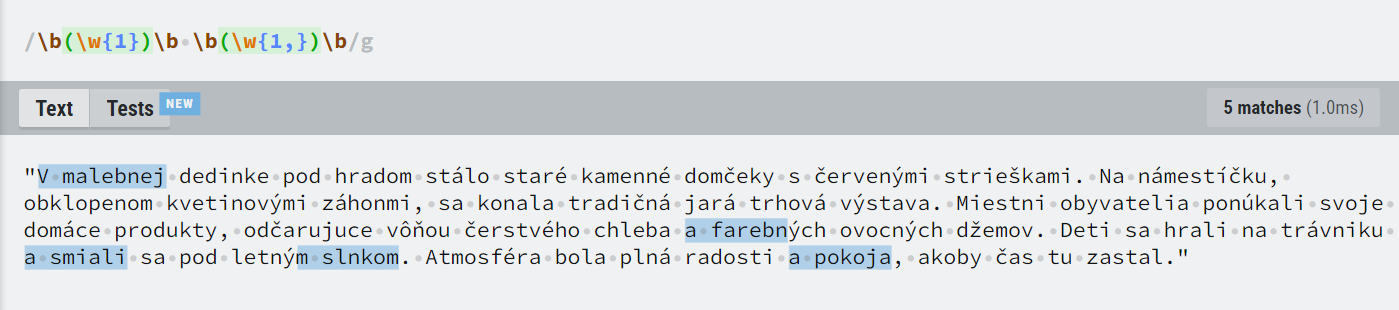
s = '"V malebnej dedinke pod hradom stálo staré kamenné domčeky s červenými strieškami. Na námestíčku, obklopenom kvetinovými záhonmi, sa konala tradičná jará trhová výstava. Miestni obyvatelia ponúkali svoje domáce produkty, odčarujuce vôňou čerstvého chleba a farebných ovocných džemov. Deti sa hrali na trávniku a smiali sa pod letným slnkom. Atmosféra bola plná radosti a pokoja, akoby čas tu zastal."'
pattern = r'\b(\w{1})\b \b(\w{1,})\b'
re.findall(pat,s)
But in other environments I get the results wrong.
It occurs in this web site: https://regexr.com/ and also in my VSCode editor.
It seems like ý is counted as word boundary!?
Why are the results here different?
Your code fragment is not entirely correct. Should be:
s = "V malebnej dedinke pod hradom stálo staré kamenné domčeky s červenými strieškami. Na námestíčku, obklopenom kvetinovými záhonmi, sa konala tradičná jará trhová výstava. Miestni obyvatelia ponúkali svoje domáce produkty, odčarujuce vôňou čerstvého chleba a farebných ovocných džemov. Deti sa hrali na trávniku a smiali sa pod letným slnkom. Atmosféra bola plná radosti a pokoja, akoby čas tu zastal."
# there was an extra single quote around s
pattern = r'\b(\w{1})\b \b(\w{1,})\b'
re.findall(pattern,s) # pattern, not pat
I’m not able to reproduce the issue in VSCode - When I run it there, it also generates the correct result. So perhaps you’re running it with a special locale (language) setting?
The regexr.com editor appears to to be limited to ascii characters only. It’s not just that the “ý” character (U+FD) is not treated as regular character, but no non-ascii code points (including any of the accented characters in extended ascii) are handled as regular characters. The site gives you a choice between PCRE (unclear if this is PCRE1 or 2) and Javascript as engines. So by default \w only supports ascii, I think. To make \w also recognize non-ascii, you have to change the PCRE regex to:
(*UCP)\b(\w{1})\b \b(\w{1,})\b
See: pcre2pattern specification (Unicode support section)
But the site you link to doesn’t support that…
Btw, I just found another site (https://regex101.com) that supports comparing different regex engines (including PCRE and Python). Seems to be working correctly there (also supports the (*UCP) prefix).
Note that this (*UCP) prefix is PCRE-specific. It’s not valid and not needed in Python since the default regex flag is re.UNICODE. If you run with the flag re.ASCII, then Python will also see the accented characters as word boundaries.
It’s possible your Unicode normalization is different. With the correction of pat/pattern, I was able to get the same result as you expected in NFC normalization, but in NFD, an incorrect result:
Unicode normalization can also be relevant - as shown in Chris’s example. For instance, what is rendered as “ý” might be either be one codepoint (extended ascii) or two codepoints (ascii “y” + codepoint for accent aigue). But in this case I don’t think that explains the behavior on the regexr.com site, since with PCRE/ascii-only matching the match includes “‘a’, ‘farebn’” (stopping before the accented y), while with NFD normalization the corresponding match is “‘a’, ‘farebny’” (stopping before the accent codepoint, and similar for other accented chars).
When I visited the site, I also wondered at first if perhaps it was using a different char encoding (different fom UTF-8) or applying some unicode normalization of extended ascii, but as far I could determine, it does not.