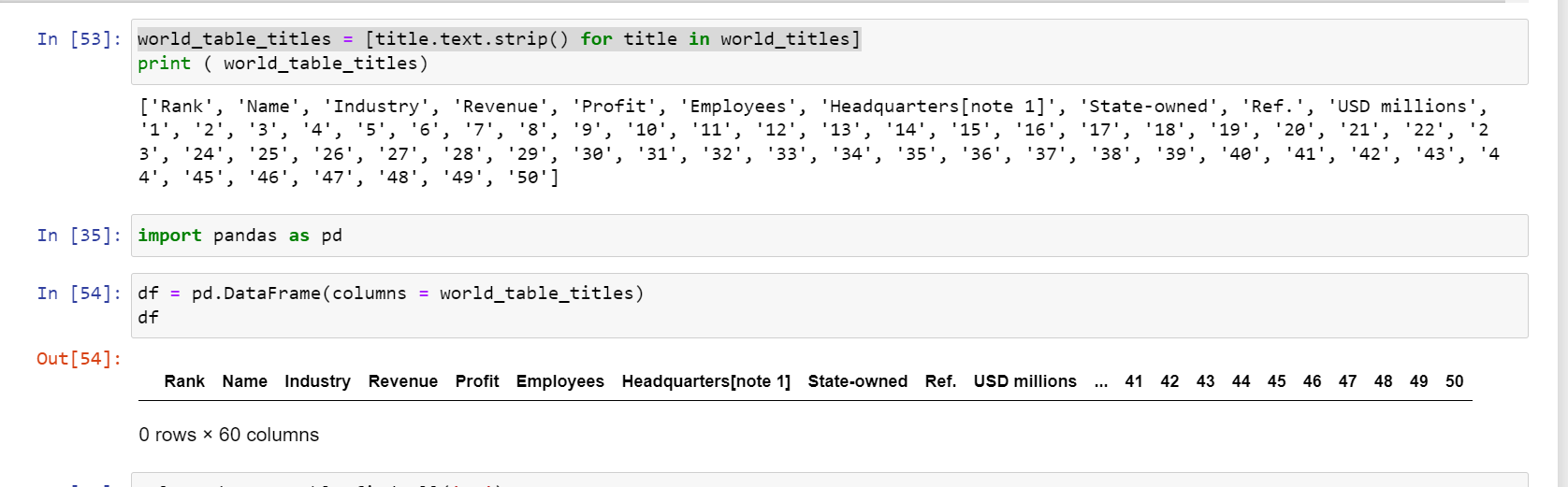
Hi, I am trying to learn Scraping Data from Website with python and i tried extract that list ( List of largest companies by revenue - Wikipedia) but it shows 60 columns instead of 8. I added the picture where i confused. ( ‘USD millions’ should be the last column but it continues like 1, 2, 3…). and i added the code. How should i fix it?
This means every th element in the table. If you look at the HTML source for the page, you can see that the “rank” column of the table also uses th elements to label the rows. HTML is more complex than most people realize, even when they try to take that into account
Scraping HTML is a last resort. For sites like Wikipedia that display user-generated content, there’s often a way to get the raw source of what the “users” edited, and that’s generally much easier to work with. As Chris showed, Wikipedia allows access to the wikitext simply by adjusting the URL. It can actually be even simpler than that: MediaWiki sites like Wikipedia offer an API, and there is an wrapper for that API on PyPI.