Greetings Pythonistas!
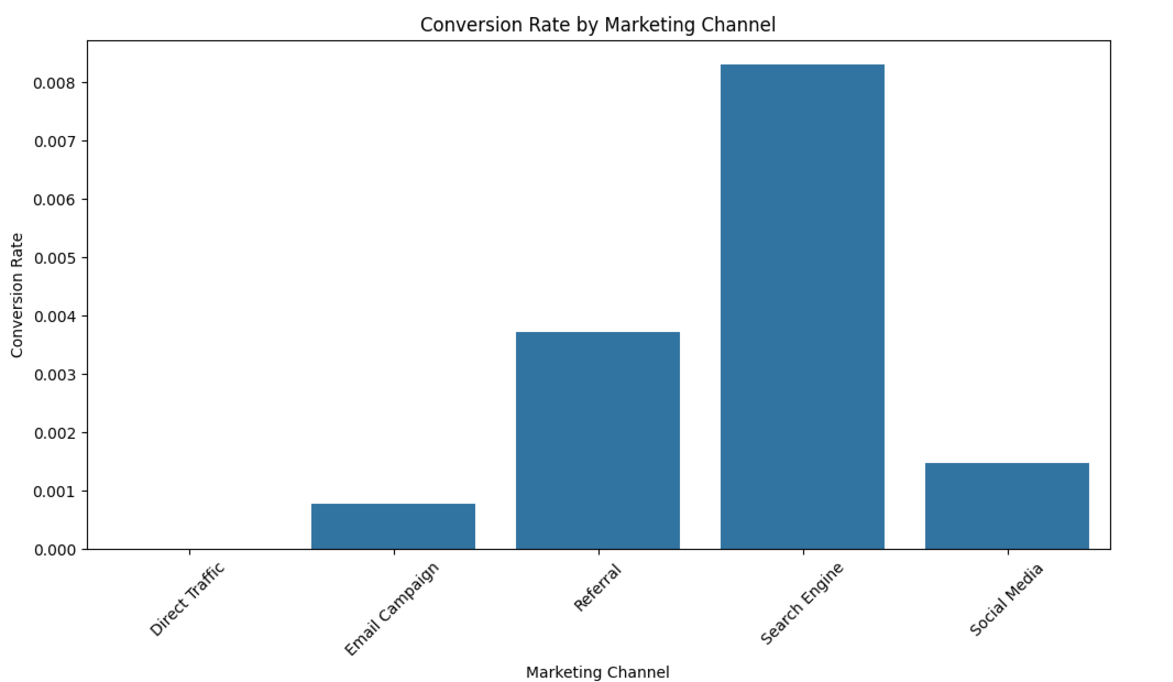
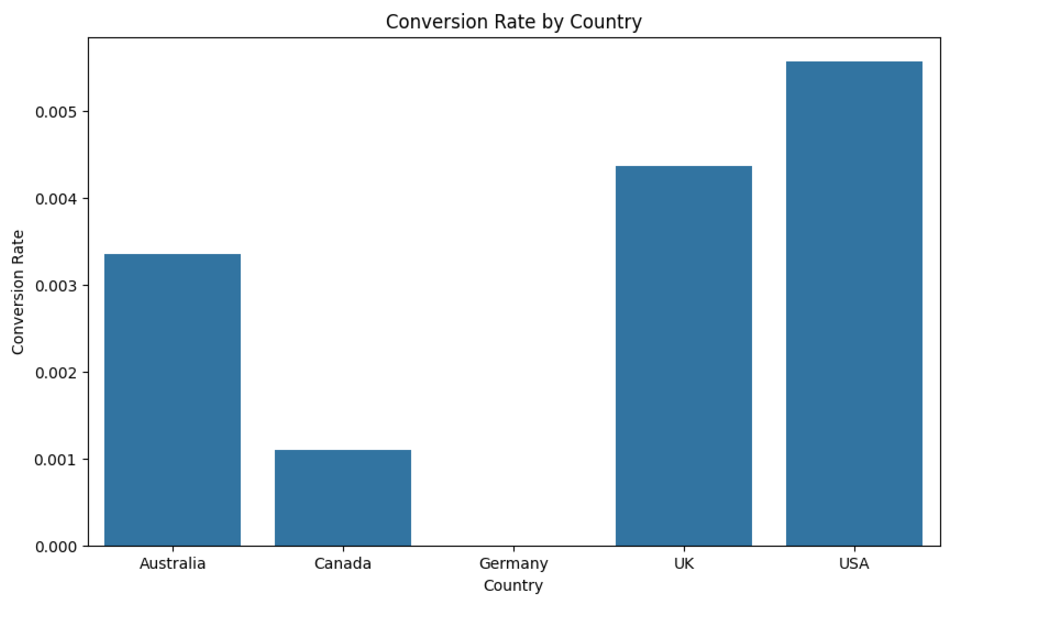
I am learning statistics with Python. The current topic I am focused on is Binomial Random Variables (and Distributions). I’m working with an e-commerce website CSV dataset. It contains 5,000 website visitors, of which 16 vistitors made a purchase (“conversion”) meaning the average conversion rate is 0.32% or approximately ~3 purchases for every 1000 visitors.
Here is the official SciPy doc on the binom module which describes the pmf:
https://docs.scipy.org/doc/scipy/reference/generated/scipy.stats.binom.html
Here is my Python code snippet:
import numpy as np
import scipy.stats as stats
from sklearn.linear_model import LinearRegression
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
df = pd.read_csv("e_commerce_conversions.csv")
n = 5000 # Number of website visitors
k = (df['converted'] == 1).sum() # Number of visitors who converted
p = df['converted'].mean() # Probability of a visitor making a purchase
p_norm = p*100 # Normalize p variable
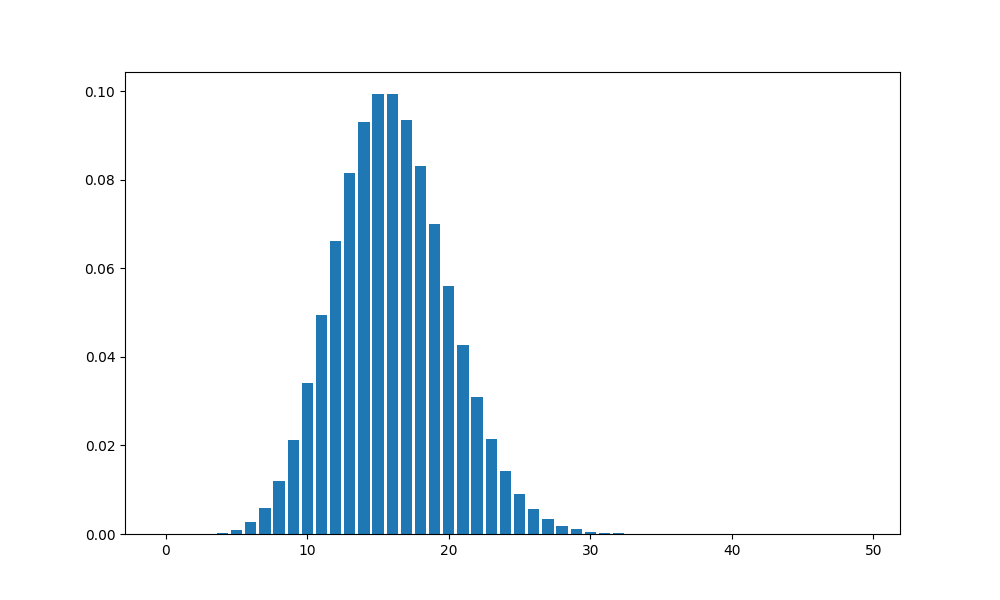
binomial_prob = stats.binom.pmf(k, n, p)
print(f" Number of website visitors: {n}")
print(f" Number of visitors who made a purchase: {k}")
print(f" Probability of a visitor making a purchase: {p_norm:.2f}%")
print(f"{binomial_prob: .6f}")
Output:
Number of website visitors: 5000
Number of visitors who made a purchase: 16
Probability of a visitor making a purchase: 0.32%
0.099377
Here is my question: What is the difference between the probability of a visitor making a purchase (p) paramter passed into stats.binom.pmf() and the output of the probability mass function?
I understand that the conversion rate p of each visit doesn’t change for individual visitors. It’s constant. If another variable were to change such as number of website visitors (less or more), there would be a decrease or increase to p. stats.binom.pmf() then is the calculation that considers the whole dataset of 5,000 visitors. But as you can see in the output above, it says: 0.099377. I don’t know why or how that is the result. When I experiment by adjusting the k (conversion) variable integer by (increasing or decreasing), the output changes. But I don’t understand why. Can someone elaborate or provide some further clarity?
Below are the details of all 16 visitors who converted in my data set of 5,000 enries. The remaining 4,984 are very similar, the only difference is that their data point under the conversion column is 0 instead of 1.
<<< counted = df[df["converted"] == 1].value_counts()
<<< counted
visitor_id date country marketing_channel converted
109 2024-10-16 UK Search Engine 1 1
313 2024-10-13 USA Referral 1 1
461 2024-10-10 UK Email Campaign 1 1
526 2024-10-30 USA Referral 1 1
1038 2024-10-18 USA Referral 1 1
1247 2024-10-11 UK Search Engine 1 1
1323 2024-10-11 Australia Referral 1 1
1541 2024-11-05 Australia Social Media 1 1
1738 2024-10-31 USA Search Engine 1 1
1802 2024-10-22 USA Search Engine 1 1
3037 2024-10-11 UK Referral 1 1
3512 2024-10-16 UK Search Engine 1 1
3606 2024-11-05 USA Search Engine 1 1
4222 2024-10-29 USA Referral 1 1
4228 2024-10-25 Canada Search Engine 1 1
4711 2024-11-05 USA Search Engine 1 1
Name: count, dtype: int64