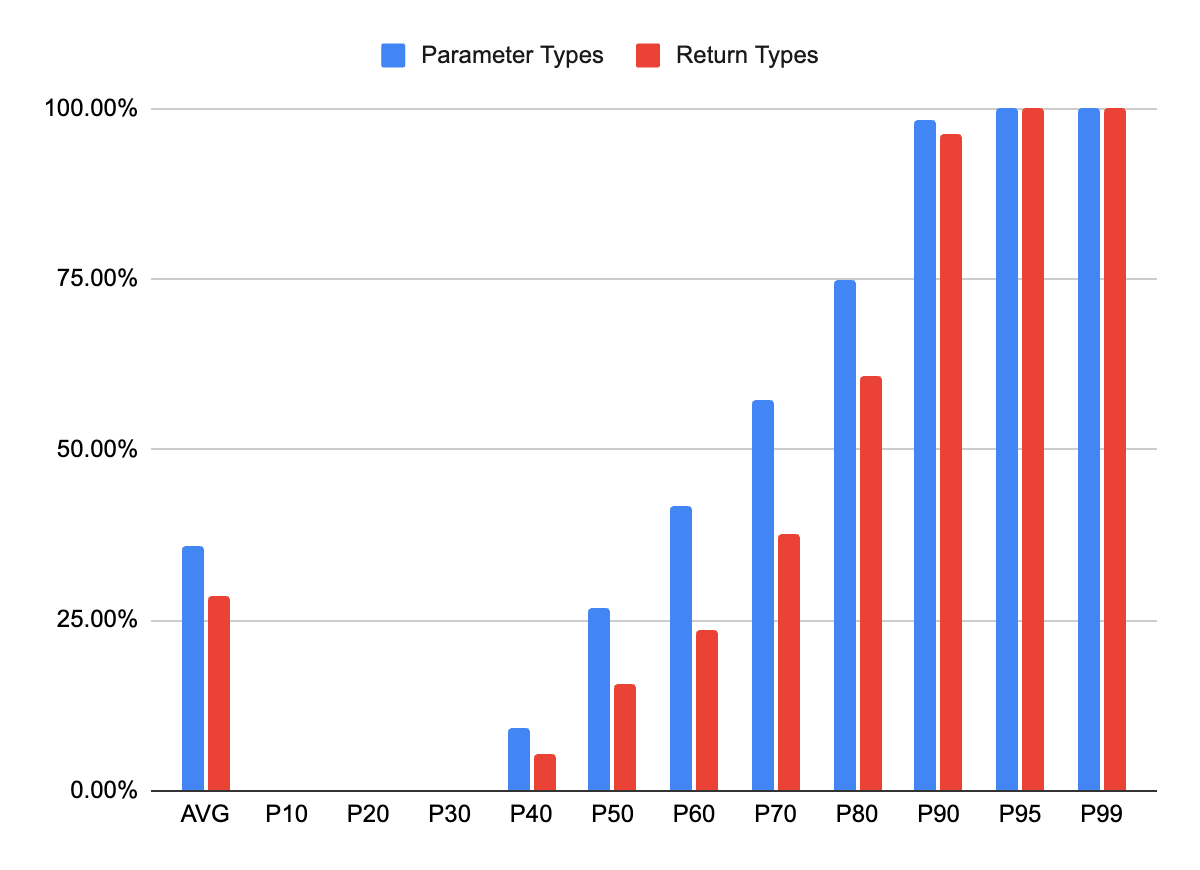
I wrote a script to analyze Type Coverage across the most downloaded pypi packages. There are a few gaps in the analysis for some packages that I couldn’t parse. Feel free to submit changes if folks would like to measure other stats or find bugs
Here are a few stats if folks are interested:
70% have at least some coverage or typeshed stubs added
I’m not sure the results are 100% accurate. I say this only because I have a package on your list (soupsieve) with full parameter and return type coverage on mypy with strict mode, but your script seems to show that not all parameters are covered and that only 25% of return types are covered. Are you scanning test folders of libraries?
Also, are you considering that __init__ functions don’t have return types annotated in a lot of code?
Edit: If I am reading your code correctly, the answer is no. Also, if I am reading your code correctly you are not considering the full qualname of a function but just its basic name, leading to weird handling of multiple classes in the same file.
A missing return type isn’t missing type coverage if the function is typed at all, type checkers understand this to be an implicit return None
This doesn’t seem to account for typing stub use (clarifying edit: I don’t see a discovery method for stub libraries, only for typeshed)
This doesn’t really mean much for users of the library (the people reading a badge stating type coverage) as it doesn’t correspond to how much of the library’s public API is typed.
One alternative way to measure this pyright verifytypes flag. That does care only about public functions and I think handles init case for you (not sure there). I think that one does still expect return types as even though pyright is smart enough to infer them, no explicit return type for public api can still be ambiguous/too specific. Maybe public api returns list in one version and set in next and return type should be something like Iterable[int] instead of more precise type inferred.
You still need to be careful to exclude test code. Unit tests often don’t have typing and really shouldn’t need it especially for return types when for most pytest cases the return type is just None anyway.
I think it’s also worth noting that mypy ships with its own type coverage analysis, which can output several formats including the standard Cobertura XML format which is for measuring code coverage. Although some of the other formats may provide more details. It might be easier/more reliable to build something on top of those reports, rather than try to write your own analysis.
Yes, my thought was to include every python file although pulling out test, tests* etc could make for some interesting data to look at.
Also, are you considering that __init__ functions don’t have return types annotated in a lot of code?
…full qualname of a function but just its basic name…
Good points.
A missing return type isn’t missing type coverage if the function is typed at all, type checkers understand this to be an implicit return None
Is that always the case?
def foo():
x: str = 'hello'
return x
t: int = foo()
Pyright infers the return type produces an error: Expression of type "Literal['hello']" cannot be assigned to declared type "int"
This doesn’t seem to account for typing stub use (clarifying edit: I don’t see a discovery method for stub libraries, only for typeshed)
Yeah, looking for “./typings” make sense. If not there, would have to parse typecheck config to find where the types are stored?
One alternative way to measure this pyright verifytypes flag.
I think tracking the presence of this makes sense.
This doesn’t really mean much for users of the library (the people reading a badge stating type coverage) as it doesn’t correspond to how much of the library’s public API is typed.
From user perspective and in service of a type coverage badge, then I agree public APIs are the main coverage stat to track. I do think it’s interesting to look at the whole project’s type coverage.
Thanks all for the great feedback! I want to consider the cases mentioned here and also compare against mypy and pyright analysis.
That’s incorrect. Mypy assumes Any if a return type is omitted (with the exception of __init__). Pyright attempts to infer the return type from the implementation if possible. I don’t know of any type checker that assumes a return type of None if the return type annotation is omitted.
Yes, pyright’s --verifytypes feature looks only at the public interface (including functions, classes, methods, variables, and type aliases), and it handles the __init__ case (exempts it from requiring a return type). It excludes symbols exported from private modules or directories (those that start with an underscore). If library authors want to distribute test code for some reason, they’re encouraged to put it in a directory named _tests or something like that.
I didn’t realize mypy treated this differently, haven’t used it in a while, and I, unfortunately, did not catch that I had worded that poorly, the intent was something like “If a return is omitted and the only return is an implicit None…” Thanks for pointing this out.
I would avoid this as this is not exposed to the users. Some projects may even have build/development tools that are not included in the installed wheel (I do this sometimes too). I for one have no need for such things to be typed and I think it sends a misleading message saying a project is not providing typing when they very much are. These are things that are often configured in the toml file which you are ignoring. Just my 2 cents.
I do typecheck tests and regularly find real bugs that way. Type errors in tests can often mean that the test isn’t testing what you think it should be testing.
I do agree that type coverage of tests isn’t too important if you want to investigate the type coverage of libraries; types in tests don’t directly affect users of those libraries.
I haven’t looked at how you do this, but want to point out the strategy we have taken with pandas that might affect your analysis. The pandas source is “partially” typed, in the sense that the internal typing of parameters and return types is meant to be used by pandas developers to ensure their code is correct. Not all methods are typed - it’s an ongoing project.
We separately ship pandas-stubs that is meant for end users. Our stubs are incomplete - there are methods without parameter annotations and/or return types. But from a user perspective, the “completeness” of types for pandas should be evaluated using the pandas-stubs package, and not the pandas source.
Types (i.e. the static analysis) and unit tests have exactly opposite purposes: tests are pointless until they are run, while the types are only analysed statically and not at runtime (except explicitly).
In my experience, getting the test code to pass a static analysis (without essentially having everything as Any) is extremely difficult, especially when using mocks and other dynamic doubles. So there is very little point in even trying to do it.