I want to make some language processing. my code work properly when I used dataframe that “yor1” or “yor2”. but unfortunately when I merge these dataframe in 1 dataframe , which is “yorumlar”, my code gives this error
File "D:\BELGELERİM\programing\4_Datascience\havlu dil işleme\nlp.py", line 44, in <module>
yorum = re.sub("[^a-zA-Z]"," ", yorumlar["Body"] [i])
File "C:\Users\oby_pc\anaconda3\lib\re.py", line 210, in sub
return _compile(pattern, flags).sub(repl, string, count)
TypeError: expected string or bytes-like object
and moreover to this, shape and type of “yorumlar” is true. there is something wrong with pd.concat operation but i could’n solve it. all files ,that i try to concat, is same format. my code is. in the and you can see my variables type and size.
import numpy as np
import pandas as pd
import re
import nltk
from nltk import FreqDist
yor1=pd.read_csv("Amazon Brand.csv")
yor2=pd.read_csv("American Soft Linen.csv")
yor3=pd.read_csv("GLAMBURG.csv")
yor4=pd.read_csv("Hammam.csv")
yor5=pd.read_csv("Hotel.csv")
yor6=pd.read_csv("Luxury Hotel.csv")
yor7=pd.read_csv("Luxury White.csv")
yor8=pd.read_csv("Qute.csv")
yorumlar = pd.concat([yor1,yor2,yor3,yor4,yor5,yor6,yor7,yor8], axis=0)
print(yorumlar)
from nltk.stem.porter import PorterStemmer
ps=PorterStemmer()
from nltk.corpus import stopwords
#Preprocessing
derlem = []
allwords=[]
for i in range(yorumlar.shape[0]):
yorum = re.sub("[^a-zA-Z]"," ", yorumlar["Body"] [i])
yorum=yorum.lower()
yorum= yorum.split()
yorum=[ps.stem(kelime) for kelime in yorum if not kelime in set(stopwords.words("english"))]
for kelime in yorum:
allwords.append(kelime)
yorum= " ".join(yorum)
derlem.append(yorum)
my variables
Processing: New Bitmap Image.bmp…
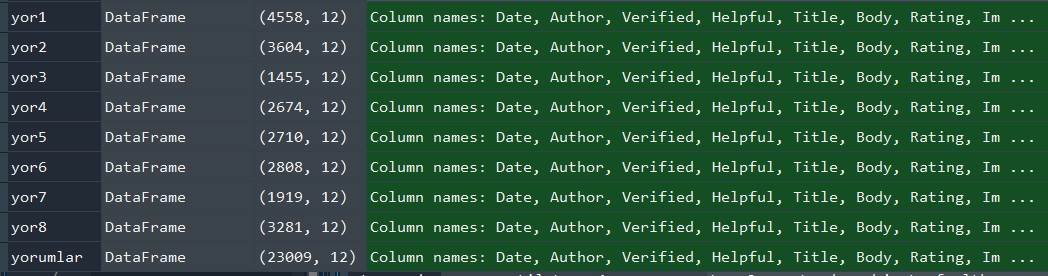
probably i do some easy mistake, could you help me ? thank you