Hello ![]() ,
,
I’ve been working on a side project over the last few months with the aim to make the corpus of Python code uploaded to PyPI more accessible to people. The project is essentially done, and I wanted to share it here because one of the use cases I had in mind was helping with the development of Python itself.
With this project anyone is able to download nearly the entire corpus of code uploaded to PyPI to their machine, parse and examine the AST of every Python file within it, completely locally in only ~6 hours.
Details: I’ve put all the information I can on a project website: https://py-code.org/. It has live statistics on the contents of PyPI, a searchable index of projects and instructions on how to use it.
The project has two main components: The code from PyPI is mirrored to Github where anyone can download it. Git is particulalrly great at compressing this kind of code, so the total download size is less than 370GB.
There are also a series of Parquet datasets indexing file metadata (size, lines, hash, etc), which lets you run some analytical queries without needing all the data.
Is this useful? I’m not really sure - I built it to see if I could, but I’d really like some feedback on if it is actually useful in any way outside of a curiosity. If it’s not, any feedback on how it could be would also be fantastic.
I’m not a core developer but some ideas I had in my head for ways this could be used are:
- Seeing how new language features are being adopted, and by what segments of the community
- Be able to quantity the impact of changes to the language (adding new keywords for example)
- Seeing how standard library usage evolves over time and spot improvements
- Test any parser changes on all the code
For example I looked at the use of various language features when parsing. 50% of project releases uploaded to PyPI now have type annotations and nearly 60% have f-strings, making them both the most popular and quickly addopted Python language features.

We can also see that pyproject.toml usage has taken off and looks like it will soon overtake setup.py usage:

Some more random fun facts
The longest Python file ever uploaded to PyPI is within this project: EvenOrOdd · PyPI
It’s 20,010,001 lines long, and is… just this:
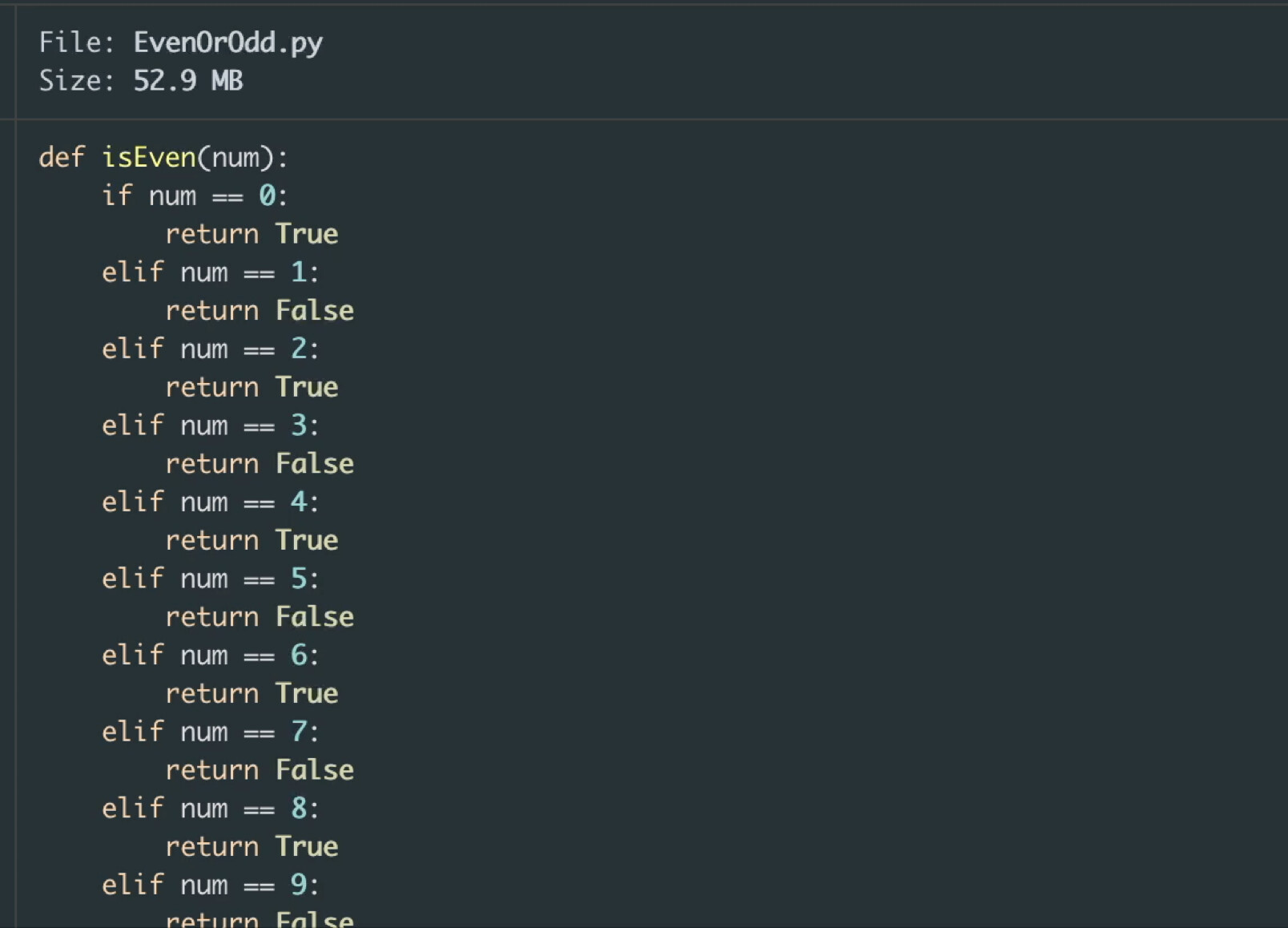
The most complex Python file ever uploaded can be found here: The most complex Python file on PyPI · GitHub
It contains an expression that has 54,188 components and predictably stack overflows anything that parses it, Python included.
You can find more stats and information on the project website
