While this topic is pretty important to me, due to huge the amount of time, stress, cognitive load and sub-optimal content-relevant choices its saved me over the years in docs/website/etc repos that switched to OSPL, and the amount of the same it costs me every day as a PEP writer and editor with those that don’t, I was intending to wait to consider and potentially propose the detailed case for it (at least in the context of the PEPs repo) once I’d established some credibility as a PEP editor and in the community. Unfortunately, it seems my OT aside that sparked off @encukou 's the SemBr thread let the cat out of the bag, and on a day when we were dealing with a severe weather situation too.
Abstract
Presently, the arbitrary 79-character line length limit for prose text in PEPs imposes an outsize burden of mechanical effort and cognitive overhead on PEP authors, editors, and community members when writing, editing and reviewing PEPs, due to the need to constantly reflow text, its lack of compatibility with common tools and editing/reviewing workflows, and greatly increased line noise in Git diffs, blame and other output.
We propose recommending the One Sentence Per Line (OSPL) approach for prose text in new PEPs, which features line breaks after each sentence, with a 1:1 mapping of sentences to lines and a soft length limit (based on reasonable sentence length) instead of a hard one.
By matching the physical structure of the file to its logical hierarchy, this is a straightforward, simple-to-implement solution to the all problems above, without the much greater complexity for both humans and machines to understand, implement and enforce introduced by “semantic breaks” or other more complicated approaches.
Motivation
At present, a maximum line length of 79 characters, and a minimum length of 70 characters, is nominally required for PEPs. However, many PEPs don’t keep to this nominal length limit for all lines, and even fewer are consistent about following the minimum. This lack of consistency can lead to confusion about conventions and expectations by PEP authors and dilutes the value of a nominal standard. Likewise, there is wide inconsistency in separating sentences; some by one space, some by two, and others by a line break.
However, such relatively modest issues are but the tip of the iceberg of the problems hard breaks cause for prose text. These include:
-
A substantial burden of time, tedious effort and stress on PEP authors, editors and reviewers to constantly reflow the physical text to fit a 79 column limit whenever changes are made, or else try to coerce their prose to conform to these arbitrary restrictions.
Given that soft wrapping is readily available in all modern editors/IDEs, as well as in most common contexts on GitHub for prose documents, whereas tools to automatically reflow reST (or in many cases, even indicate the hard-wrap width) are not, this does not seem to still be justifiable.As far as the authors are aware, only the RST extension for Emacs offers full support for automatically reflowing reST prose. Per the latest Python Developers Survey 2020, the most recent as of this writing, only 2% of Python developers currently use Emacs. Therefore, it is likely that most PEP contributors do not regularly use an editor with an extension that reliably supports this.
Furthermore, regardless of a contributor’s choice of primary editor/IDE, a substantial amount interaction with PEPs typically takes place outside of it, such as on GitHub, where soft-wrapping is usually available (at least on desktop), but even minimal assistance for hard wrapping (e.g. a column count, or a vertical rule at 79/80 characters) is not.
-
It increases the difficulty in parsing and manipulating the text, as the physical units as seen by the editor do not align with the logical units to be manipulated (phrases, sentences or paragraphs).
-
It also makes it easier to make many classes typographical and editing mistakes at hard-wrap boundaries, and substantially more difficult to catch them.
In particular, repeated, missing, extraneous and non-matching words/phrases can be present on both sides of an arbitrary hard break, as can happen during editor or reflowing, but require a careful eye to catch.For example, on python/peps#2164, multiple passes of manual and regex searching discovered and fixed many such mistakes, but some were only caught by a careful read-through by reviewers, and likely others yet not detected. Additionally, the reflowing process itself results in much more frequent mechanical edits, increasing the probability of mistakes and requiring more frequent and extensive proofreading passes to be assured of the text’s quality.
-
Git/GitHub diff, blame, patch, review and suggestion output is much more noisy and less meaningful.
As the basic unit of text considered by Git, the line, has no syntactic or semantic meaning in such files, and even a relatively small change to a single line can propagate to entire paragraph. This results in git diff and git blame output, and their GitHub equivalents (particularly on pull requests), alongside patches and GitHub suggestions, being long, noisy and difficult to read and parse for the actual meaningful changes. It also interferes with GitHub's word-level change highlighting, making it much less useful. -
Arbitrarily split lines make review comments and suggestions significantly more difficult and less useful, with a higher chance of merge conflicts.
Multi-line comments/suggestions, which are more tedious and don't always work as desired, must used far more often even for small changes in a single sentence, as not only will they often span multiple lines (often with deleted lines in the way, that block suggestions completely), but also require reflow of many succeeding ones, or even an entire paragraph, which is often not possible at all, and otherwise must be done manually with no aids. Finally, given this results in more lines being changed, it also increases the probability of merge conflicts even between logically independent changes.
Rationale
The One Sentence Per Line (OSPL) structure for prose text in new PEPs, coupled with relaxing the nominal hard line length minimum and maximum with soft limits based on reasonable sentence length, is a straightforward approach to neatly resolve the above issues. Conceptually, it means a 1:1 mapping between physical lines and logical sentences, and practically, is simple to implement, as contributors would just use a line break instead of (one or two) spaces after each sentence. This makes writing, editing and reviewing text much easier and less painful by matching the physical to the logical structure of the prose.
In particular, for authors and editors, it:
- Avoids the constant need for tedious, disruptive reflows upon most changes, which is a large drain on author, editor and reviewer time.
- Makes it harder to commit and easier to notice many common writing and editing mistakes spanning multiple lines (e.g. repeated, missing, spurious or non-matching words).
- Results in it being much easier to spot sentences that are too long, too short or vary too much in length, as well as repetitive/redundant patterns or breaks in valid ones.
- Allows easily swapping, moving, commenting and deleting sentences with the commands and shortcuts in nearly any common source editor, and makes it simple to split and join paragraphs.
- Neatly sidesteps debate over one versus two spaces after sentences, while having the benefits of both.
It also benefits reviewers and Git workflow; specifically, it:
- Enables shorter, cleaner and more logical and semantically meaningful diffs, blame and patch output, and allows GitHub’s per-word diff display to work properly
- Allows reviewers to comment/make a suggestion on a sentence in one click, instead of using more involved and often flaky multi-line selections
- Prevents having to constantly guess and check or roundtrip from an editor when making GitHub suggestions to fiddle with line length
- Reduces the chance of merge conflicts by localizing changes to the specific sentence(s) modified
This could affect readability in certain cases for a minority of contributors, if using limited viewing/editing interfaces that still lack support for soft wrapping (such as parts of GitHub’s mobile interface). However, it is a substantially lesser impact than the status quo, which ultimately harms usability for nearly all editors, interfaces and tools (aside from those specifically supporting parsing and reflowing reST syntax, which is a very small fraction).
We also carefully considered alternates besides OSPL and the status quo, including paragraph- and semantic breaks, but in our analysis and experience, neither offers the same balance of both conceptual advantages and practical usability as OSPL.
Specification
In English prose portions of source files formatted with a “One Sentence Per Line” (OSPL) structure, a single line break MUST be used after each prose sentence, and SHOULD NOT be used within a sentence, absent other markup which requires it.
For such files, a hard minimum or maximum character limit for column width MUST NOT be enforced for prose text, but to aid readability, sentences SHOULD be kept to a reasonable length (with ≈240-300 characters max as a rough guide).
The OSPL source structure is RECOMMENDED for new PEPs, and MAY be used for existing draft PEPs whose authors choose to adopt it. PEPs MUST be consistent about their choice of source structure.
OSPL MAY be used for prose text by other Python-related projects, such as documentation, should they choose to adopt it.
Backwards Compatibility
As this change does not affect the meaningful syntax of reST (or Markdown) files, nor the rendered output, there is no direct backwards compatibility impact. We could progammatically convert files from hard breaks to OSPL, but particularly on the PEPs repo, this is not really necessary, aside from authors who may wish to do so when rewriting their draft PEPs. Rather, future PEPs can simply be written using OSPL.
Security Implications
As this merely changes the line-breaking strategy, there are no conceivable negative security implications from this change.
How to Teach This
Teaching PEP authors, editors and reviewers to implement this is the simplest of all considered alternatives (including the status quo), aside from possibly paragraph-only breaks. Contributors need only to press Enter rather than (once or twice) Space after each sentence. That’s it, and it can be relatively reliably automated with a fairly straightforward regex-based script.
Unlike hard breaks, is no need for contributors to install and set up an editor and appropriate plugin(s) to hard-wrap reST (if one is even available for the users’ platform); nor configure an editor to display a vertical rule at the indicated column length, learn what constructs in reST can be broken by spaces, and then remember to apply them; nor copy and paste back and forth from one in interfaces (e.g. GitHub).
Likewise, unlike semantic breaks, there is no need to teach contributors (particularly those for whom English is not their native language) to constantly recall and parse the technical details of English grammar as to the difference between dependent and independent clauses, and remember and worry about circumstances that may or may not merit a line break, and the various other nitpicky rules of sembr.
While paragraph breaks are perhaps even more “natural”, by using a space rather than a line break after sentences, they do create the potential for uncertainty and inconsistency with the issue of one versus two spaces after sentences, which OSPL neatly side-steps.
Reference Implementation
OSPL requires no particular build system, linting or other changes to implement on the PEPs repository (or presumably elsewhere). However, the authors propose developing, as part of this proposal, an autoformatter to automatically conform (new) PEPs to this style, on an opt-in basis, which the authors have already experimented with locally. Such a formatter would leverage the existing pre-commit framework already used on the PEPs repository for local automatic, on-demand and CI based linters and fixers. With such, the formatter would be automatically installed, executed and updated via pre-commit cross-platform with a single one-time setup command (along with the existing linters), and could be run both on-demand and automatically with each commit, with no additional user effort, as well as optionally on the CIs (for opted-in PEPs).
Such a formatter could not only apply the OSPL style, but could also be extended to do so for the existing PEP 12 requirements, such as header underline characters, preceeding/following line breaks and other mechanical changes, greatly smoothing the process for both authors and editors/reviewers alike, much like the black autoformatted for Python code. In the future, it could even be configured and adapted for other Python prose applications, if desired.
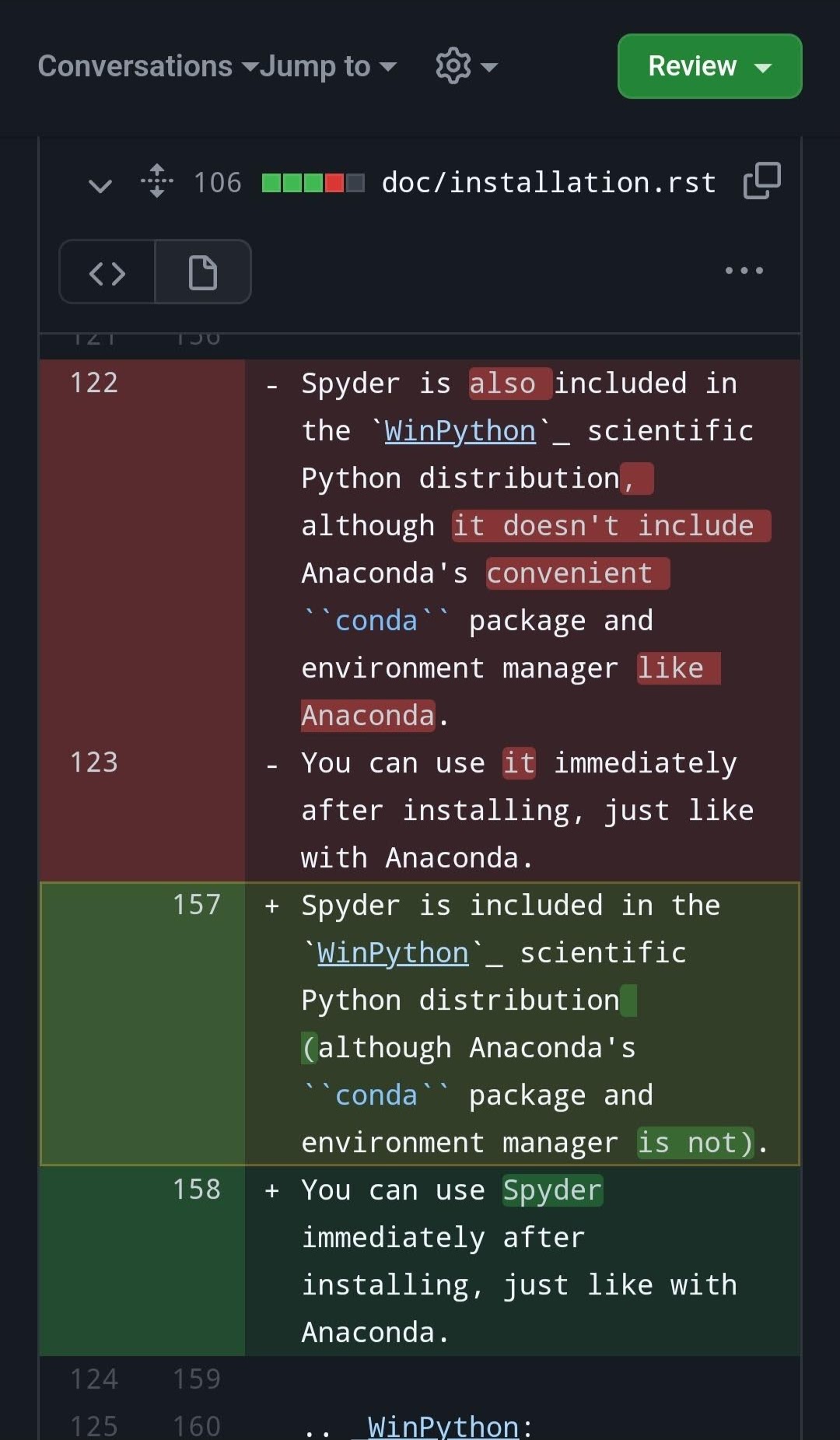
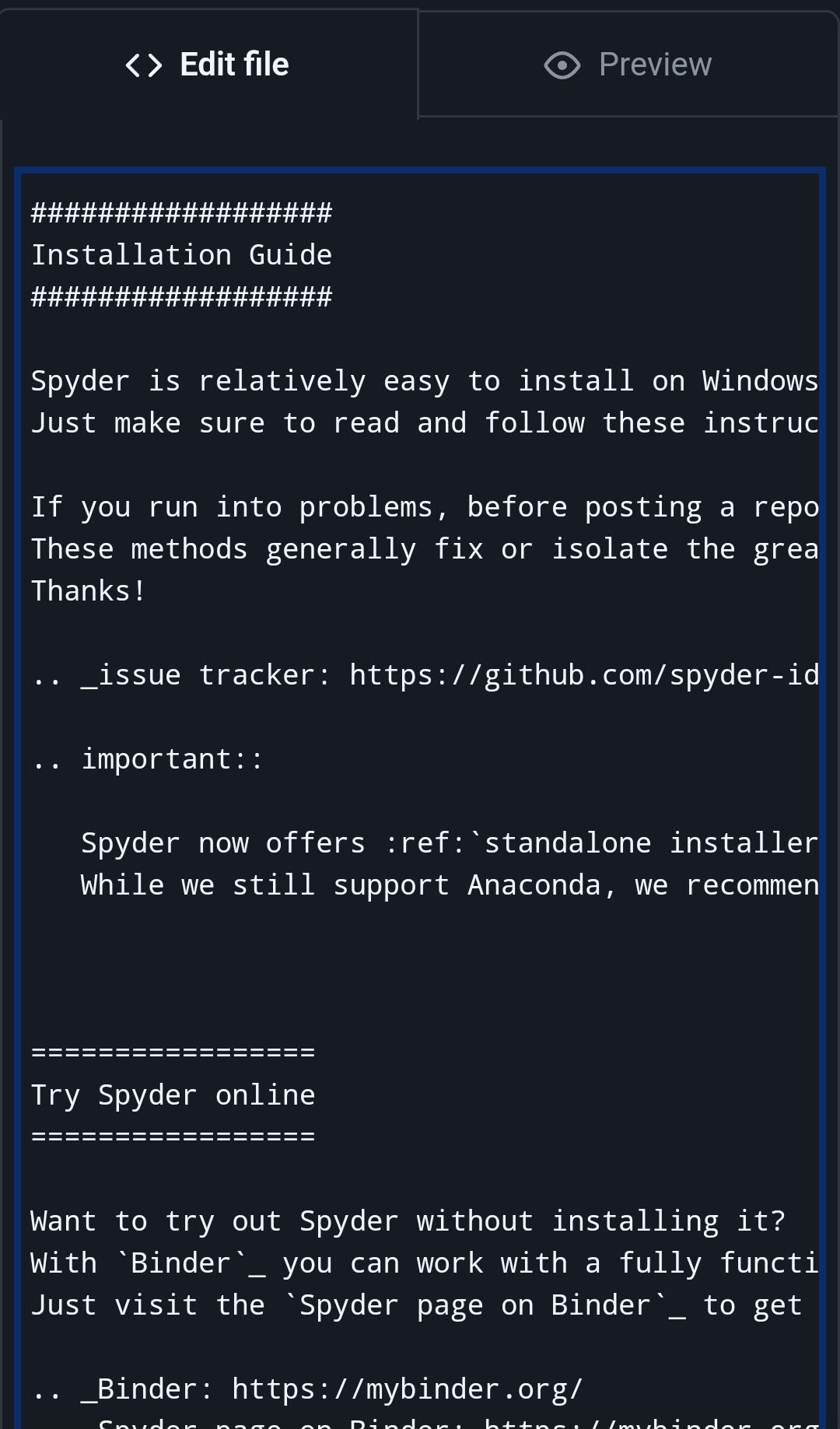
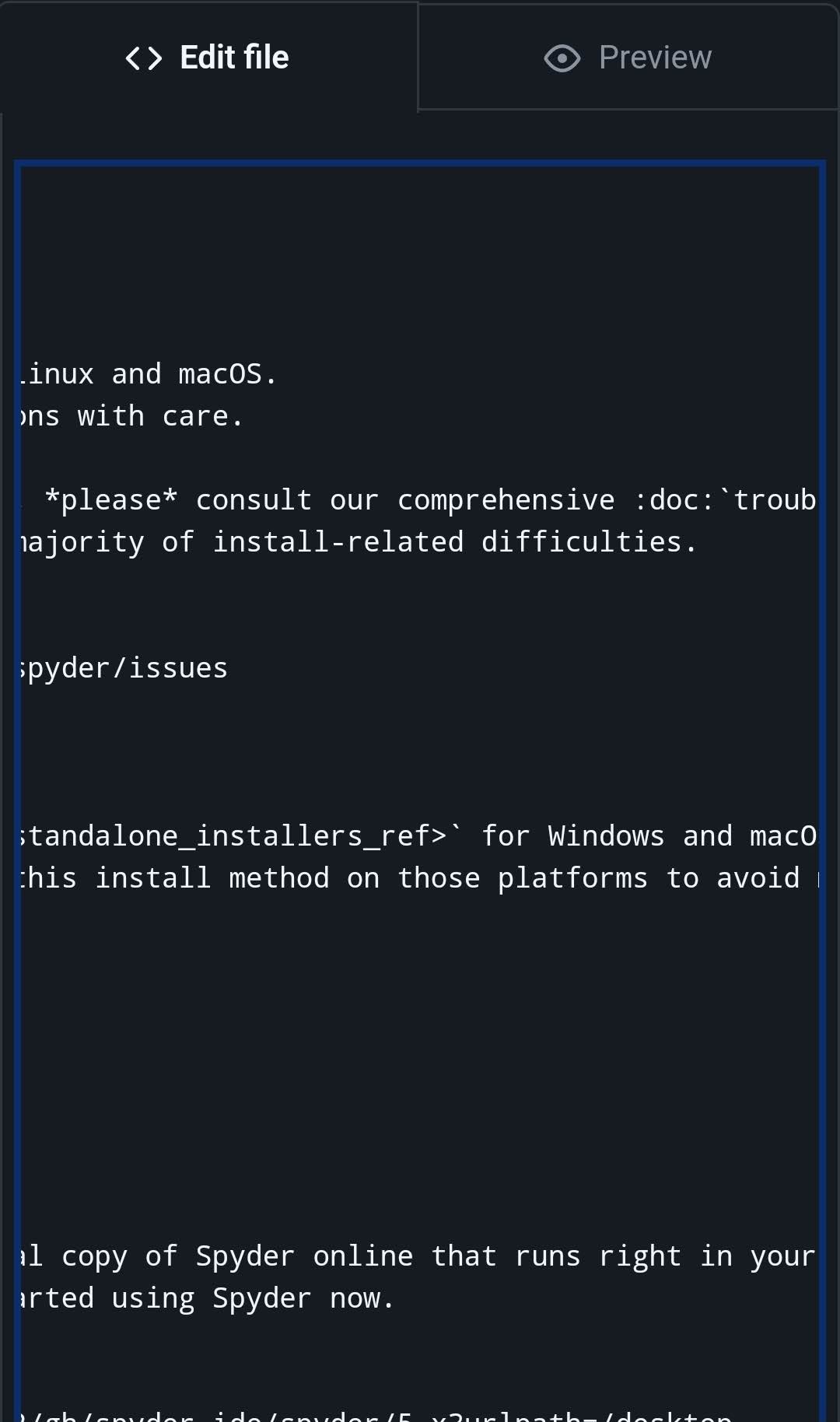
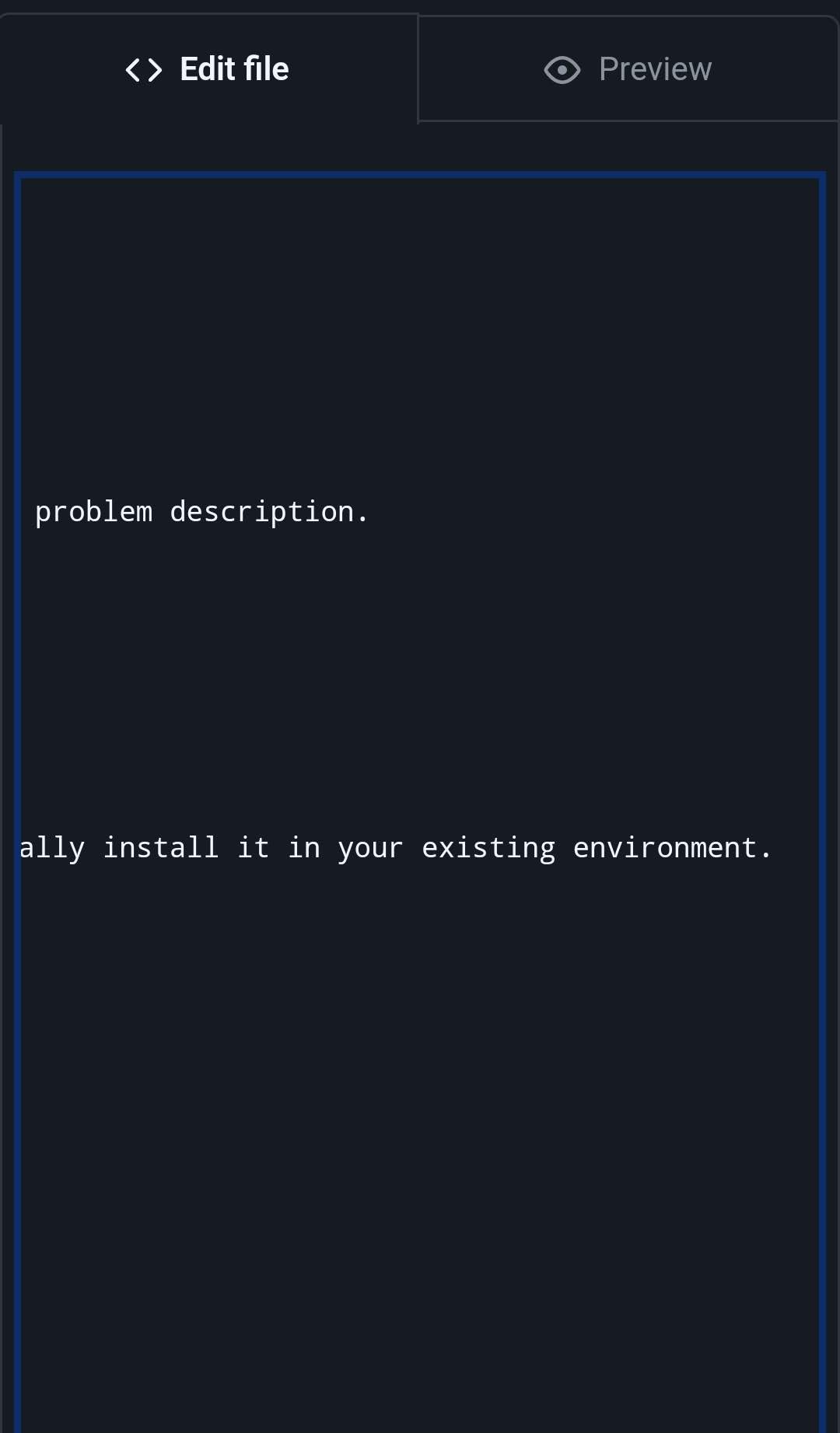
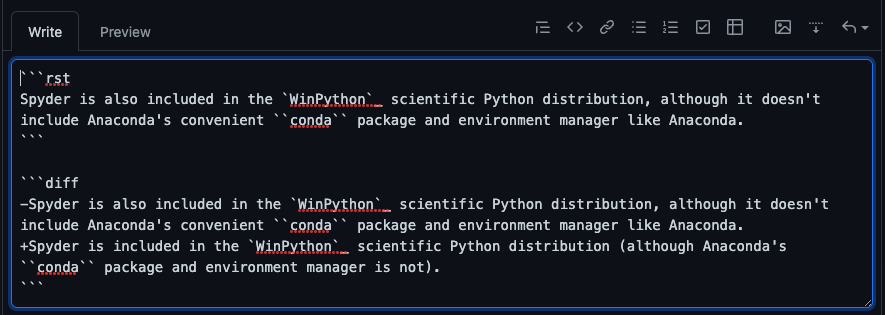
However, the Spyder-Docs repository for the Spyder scientific environment and IDE, which the primary author is the maintainer of, serves as an example of a moderately large documentation project (and associated style guide) that has successfully adopted OSPL, along with the various other prose projects in the Spyder organization (including the Spyder website, website theme, docs theme, API docs, proposals and others).
Additionally, ASCIIdoc, another major documentation system, has adopted OSPL as a recommended standard.
If its adoption and use by the PEPs repository is successful, and critical issues are resolved or worked around, the PEPs repo in turn may serve as a reference implementation for other prose content in the Python community.
Open Issues
Would it make sense to extend this approach to the Python documentation and related projects (devguide, etc) as well? Or would it be wiser to just apply it to the PEPs repo initially, as currently proposed here, which limits the scope and allows it to be tested in a controlled, well-suited and minimally disruptive environment for possible applicability elsewhere?
Rejected Ideas
Hard wrapping
Hard wrapping is the status quo, the myriad of issues with which are described in the Motivation section, and summarized here.
+ The status quo; requires no nominal changes
+ Keeps physical line width narrow, improving usability on some platforms without soft breaks (e.g. GitHub mobile)
- Requires constant, usually manual reflows
- Less straightforward make common edits with standard tools
- Makes diffs, blame, patches and suggestions very noisy and less meaningful
- More difficult to use with Git/GitHub review workflow
- Easier to make many mistakes and harder to spot
- Inconsistent separation between sentences (1/2 spaces, or sometimes break)
Paragraph breaks
With paragraph breaks, line breaks are only used to separate paragraphs and syntax. The most “natural” style in prose writing, but despite being a nearly opposite approach to hard breaks, share many of the same downsides, and thus haven’t been seriously considered.
+ Most natural and easiest to learn (what untrained users type by default)
- Far longer line lengths than any other strategy, for cases where it matters
- Noisy, not very useful diff, blame and patch output
- Poor granularity with comments/suggestions applied on whole paragraphs
- Higher chance of suggestion and merge conflicts
- No clear separation between sentences
Semantic breaks
With semantic breaks (SemBr), line breaks are placed between semantically meaningful sub-components of sentences and other constructs. Conceptually, it is rather attractive for many of the same reasons as is OSPL, and it still is generally better (at least in theory) in most respects than “dumb” hard breaks in that the breaks have semantic meaning and the diffs are cleaner, while keeping line length shorter than OSPL (usually around or below the previous 80-character hard limit, so long as the clauses are a reasonable length).
However, “practicality beats purity”, and the practical downsides in actual use—increased tedious effort and cognitive burden, increased learning curve (especially for those who aren’t native English writers), difficulty of consistently enforcing, impossibility to check or automate with tooling, introducing choppy, poetry-like flow when reading, greater total vertical space consumption, more complex to review/suggest—weight strongly against it. From our experience, OSPL is a much better solution in practice, which seems to be the case for others as well, as the authors are currently not aware of any large projects that have formally adopting and consistently used semantic breaks.
In more depth, some of the practical difficulties with SemBr are as follows:
- It results in a high degree of tedious effort inserting breaks everywhere, and even greater cognitive burden (having to constantly parse both the language syntax and semantics to determine what merits a break, rather than simply putting one after each sentence and being done with it)
- It is less obvious to readers, and substantially more difficult to teach writers, especially the high proportion of those for whom English is not their first language, how to determine where the breaks go (they have to understand much more about the technical details of the English language, which is difficult even for many native English speakers)
- It is practically much more difficulty to mandate or apply consistently, since it is a less simple, obvious and “natural” style than sentence-level breaks
- Since it relies on details of English grammar and semantics, it is essentially impossible to check or automate with tooling
- As others mentioned, the very short fragments are too short to smoothly read
- It increases total length and vertical space consumption by several times
- It is more complex to review/suggest, because often one wants to (or later decides they need to) modify more than one clause in a sentence, which does not play well with GitHub suggestions
In summary:
+ Writing and editing are less constrained than hard breaks (though more than OSPL)
+ Line length is as short (or shorter) than hard breaks
+ Diffs, blame, etc. are fairly meaningful and highly granular
+ Conceptually rather elegant, at least in theory
- Still a lot of tedious effort, and even more cognitive burden
- Less obvious to contributors and requires substantial effort to teach
- No clear, consistent rules could result in churn and bikeshedding
- Impossible to check, lint, or reflow automatically
- Review comments/suggestions still difficult due to multiple lines
- Can be difficult/choppy to read and gauge flow
- Longer file length and vertical space consumption